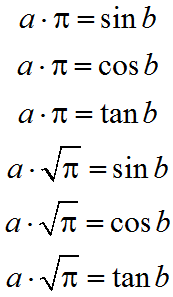Какова вероятность выбить дабл в рулетке на дваче? А трипл, а квадрипл, а n-дипл с первого раза? А со второго, а с третьего, а m-ного? А?а?а? Слабо решить?
Сап! Прошу разбирающегося в логике человека содержательно объяснить следующую теорему, а именно случай применения правила введения квантора всеобщности и случай кв.существования. Заранее большое спасибо!
PS. Есть подозрение, что в самой статье допущена ошибка: " t does occur in any member of Γ1 or in θ" "Then, since t does not occur in Γ1, Γ1⊆Γ′."
Я значит учился и постигал алгебру с геометрией а мне вот так подсовывают хуев калькулятор нахуя? Если фактически все задачи в огэ можно решить без калькулятора зачем? Что бы я купил калькулятор Casio и решил половину задач вот это да. Конечно есть вторая часть где нужно расписывать но трояк можно получить и в первой пиздец Ященко убил всю суть экзамена, может он ещë разрешит смартфоны? Ященко очнись и прими таблетки и иди дальше порти жизнь 11 классу а нам девятиклассникам не мешай учиться.
Зачем зубрить таблицу умножения и как правильно считать? Как сформировать и развить "математическое чутьё"? Сколько и каких задач надо решать для понимания? Что значит понимать математику? Нужны ли сложные задачи и науч-поп по математике или это развлекательный контент? Как сформировать мотивацию к математике или вообще отбить всякий интерес ("Плач математика")? Почему уровень математических познаний падает? Нужно ли возвращаться с старым учебникам? Как вообще можно обучать математике, какая тут связь с условными рефлексами и основаниями математики? Как написать экзамен по математике, если ничего не понимаешь? Как производственными масштабами выпускать математиков если "Нет царских путей к геометрии"? Можно ли используя измененные состояния сознания (речь не идёт о лихорадке) и современные представления стать как Сриниваса Рамануджан Айенгор?
✵ Эти и подобные вопросы можно будет обсудить в данном треде. ✵
В тред приглашаются учителя/преподаватели математики, со своими прохладными историями.
>>49397 Потому что ты прав, и они существуют в разных мирках. Между формулами и конкретными задачами существует определённый логический "пробел", который пидорасы-преподаватели, пидорасы-писатели учебников, пидорасы-объяснятели хуйни в интернете НИКОГДА не заполняют. Так что анон, твои мозги работают как надо, и ты ни в чём не ошибся. Действительно, знание теории не означает умения эту теорию грамотно применить.
По существу, это одна из загадок мышления. Часто для того, чтобы привести в порядок мысли, бывает необходимо попытаться изложить их в письменном виде. Когда вы по-настоящему заходите в тупик, когда речь идет о настоящей проблеме, которую требуется решить, обычное традиционное математическое мышление не может помочь вам ничем. К новой идее ведет только длительный период необычайного сосредоточения на проблеме без каких-либо отвлечений. Необходимо действительно не думать ни о чем, кроме проблемы, полностью сосредоточиться на ней. Затем вы должны остановиться, после чего, насколько я могу судить, наступает период релаксации, во время которого вступает в игру подсознание, и в этот момент к вам приходит новая идея вроде Эндрю Уайлс (по крайней мере в известной книге о теореме Ферма это цитируют, и он вроде не оспаривал)
Привет! В октябре решил изучить анализ на R и R^n, а также линейную алгебру. Нужно мне это было для изучения алгоритмов машинного обучения. Прочитав шапку треда для начинающих, я понял, что нужно начинать с листочков 57-ой школы. Ну, пошел в магазин канцелярии, купил тетрадки для конспектов и решения задач. Открываю первый листок, "Теория множеств". Прочитал первое определение, вроде понял его. Затем записал его в тетрадь для конспектов. Потом повторил то же самое с другими определениями. Приступил к задачам. Понимаю, что не помню ни одного определения. У меня вылетела из головы информация, которую я прочитал 5 минут назад. Потом, подглядывая в конспект, начал решать задачи. В одной из задач нужно было что-то доказать. Я написал доказательство и перечитал его. Понимаю, что оно запутанное, в нем много лишнего и есть логические ошибки. После этого я поплакал от собственной ничтожности и забросил математику. Но сейчас я вспомнил про это и решил попробовать снова, однако понимаю, что меня ждёт такой же результат. Что мне делать?
>>110473 (OP) >Прочитав шапку треда для начинающих, я понял, что нужно начинать с листочков 57-ой школы это особые (((листочки))) для особых учеников, обычному человеку нафиг не нужные
>>110473 (OP) У листочков 57 школы же нет ответов. Как учить это говно в соло без ответов и препода? Или о каких листочках речь? В оранжевой книге по матану нет нихуя.
Сап, пацаны. В общем, нужна народная помощь. Как найти координаты вершин треугольника { x, y, z }, который подобен треугольнику с известными координатами вершин { a, b, c }, такие, чтобы расстояние между параллельными сторонами треугольников было равно заданному t? За помощь помолюсь за тебя, за помощь + объяснение решения впишу имя/ник в благодарности в создании моего проекта (если захочешь). Заранее спасибо
>>110872 (OP) Хуяли не читаешь шапку? С такими вопросами в новичковый тред. Если что, по мере увеличения $t$ точки маленького треугольника стягиваются в центр вписанной окружности.
Указывает ли математик на существование Бога? Давайте подумаем. Если теория эволюции верна, то чел
Аноним03/05/23 Срд 12:36:40№102524Ответ
Давайте подумаем. Если теория эволюции верна, то человеческая математика это просто адаптация, которая возникла как случайная мутация и была поддержана отбором, потому что позволяла нашим предкам лучше размножаться в Африканской саванне и снегах Европы каменного века.
Исходя из этого можно было бы ожидать, что математика, как и прочие адаптации человеческого тела, вроде глаз или лёгких, была бы эффективна разве только в типичных условиях человеческого обитания. Но мы наблюдаем, что эффективность математики куда шире, чем эффективность человеческих глаз и лёгких, математика оказывается работает везде во вселенной, на любом уровне, от субатомных частиц, до сверхскоплений галактик. Как это объяснить?
С позиции атеиста математические объекты, такие как числа и теоремы, являются просто абстракциями, полезными людям для выживания, а значит применимость математики за пределами человеческой среды обитания является просто совпадением. У атеиста нет другого объяснения почему вселенная от атомов до галактик соответствует абстракциям поздних гоминид.
Напротив, у теиста есть готовое объяснение: когда Бог создал физическую вселенную, Он спроектировал ее в терминах математической структуры, и наделил нас соответствующей способностью к математике, чтобы могли познавать его творение.
>>102596 >Как и математика любых других животных: У животных нет математики. Количество и другие свойства физических стимулов, которые могут различать животные, это NAARR (non-arbitrary applicable relational response), тогда как абстрактные математические объекты это AARR (arbitrary applicable relational response), человечеству не известно ни одного животного, которое могло бы в AARR.
>>102524 (OP) >Давайте подумаем. Ну давай, покажи, как ты умеешь думать. >Если теория эволюции верна, то человеческая математика это просто адаптация, которая возникла как случайная мутация и была поддержана отбором Лол. Математика - культурное явление, возникшее в историческую эпоху. Когда эволюция уже не рулила развитием человечества в той же мере, а для выживания были изобретены рабы. Это не результат естественного отбора. Даже если бы редукция к биологии верна, не все в организме обязательно адаптация т.к. естественный отбор не отсекает бесполезные, но и безвредные для выживания штуки. Кстати о странном в эволюции, привет хвосту павлина. >Исходя из этого можно было бы ожидать, что математика, как и прочие адаптации человеческого тела, вроде глаз или лёгких, была бы эффективна разве только в типичных условиях человеческого обитания. Можно было ожидать, а можно и не ожидать. Почему отобранная случайная мутация, оказавшаяся полезной, обязательно должна быть "специализированно полезной"? Это же не разумно спроектирвоанный для конкретной задачи инструмент. >математика оказывается работает везде во вселенной Лол, откуда знаешь? Побывал везде во вселенной? Физики рассказали? Они тоже точно не знают. Наука тысячу раз менялась и еще тысячу раз поменяется. >С позиции атеиста математические объекты, такие как числа и теоремы, являются просто абстракциями Не всё так просто. Можно дрочить на Доккинза и быть при том неоплатоником. Фигня вопрос вообще. >Напротив, у теиста есть готовое объяснение Далеко не все теисты парятся проблемами математики т.к. религии в принципе не про неё. У теиста найдется ответ, также как и у эволюциониста найдется ответ на любой культурологический вопрос. Но правда в том, что и для первых и для вторых данный вопрос не профильный, а ответ спорный.
Я преследую 4 цели: 1) Стать МЛ инженером и устроиться на работу с ЗП 300ккк/с. 2) Изучить математик
Аноним01/10/23 Вск 16:01:19№109197Ответ
Я преследую 4 цели: 1) Стать МЛ инженером и устроиться на работу с ЗП 300ккк/с. 2) Изучить математику на уровне магистратуры. 3) Изучить физику на уровне магистратуры. 4) Изучить химию на уровне магистратуры. Напишите мне подробный план, как мне САМОСТОЯТЕЛЬНО И БЕЗ ВУЗОВ достичь каждую из этих целей.
>>109197 (OP) >Стать МЛ инженером и устроиться на работу с ЗП 300ккк/с Для этого нужны только связи: знакомый тимлид, который даст место, или хорошая внешка и соцскиллы чтоб понравиться hrочке и команде и получить стажировку. Опционально: жить в ДС, диплом в МФТИ и подобных, связи с преподавателями ml-компаний. Так всё устроено в 2023 году, скиллы и желание почти не решают. >Изучить математику на уровне магистратуры Хватит двух курсов бакалавриата любого мат факультета, больше - вредно, так как на старших курсах преподают белеберду, засерающую молодому студенту мозг. >Изучить физику на уровне магистратуры >Изучить химию на уровне магистратуры Не нужно, хотя и полезно для общего развития.
А что если нуля не существует? Ноль просто является абстракцией такого поворота фазы, при котором п
Аноним02/09/23 Суб 15:47:37№106914Ответ
>>106914 (OP) Ноль существует как абстракция и выражает отсутствие. Он одновременно и есть и его нет, при этом его бесконечно много и везде. Ззотерическая эротика ока саурона
Все время в школе мучали проблемы с пониманием физики/химии/математики из-за крайне запутанных и излишне абстрактных для меня объяснений в учебнике. Возьмем случайную тему: >Напряжение (разность потенциалов) – отношение работы, выполняемой полем при переносе заряда из начальной точки в конечную, к величине этого заряда. Я просто не врубаюсь в смысл этих слов. Это набор рандомных слов для меня, я не могу их связать между собой и тем более не смогу применить на практике. Читаю просто как "поле, начальная точка, конечная точка, заряд". Каким полем, какого заряда, какой работы? Вижу дикое сочетание слов "отношение работы", я знаю, что это означает, только по отдельности. Мне скажут, что отношение - это деление (почему нельзя сразу назвать это делением?). Деление переноса к величине? Что это такое? Поле переносит заряд и одновременно делится на заряд? Как это? Почему это назвали поле, когда я слышу слово поле, для меня это синоним слова "плоскость", уже потом, когда объяснили, выяснилось, что поле - это сила, почему тогда нельзя изначально вместо слова "поле" использовать слово "сила"? >Потенциал, как мы помним, это отношение потенциальной энергии заряда, помещенного в некую точку поля, к величине этого заряда, или же это работа, которую выполнит поле, если поместить в эту точку единичный положительный заряд. Вот еще сложнее. "Потенциал это отношение потенциальной энергии заряда". Для меня это как "кошка это отношение кошачьей энергии заряда". Заряд надо поместить в точку поля, к величине этого заряда. Заряд надо поместить к величине заряда. Как это? Объяснять эти вещи, если что, не прошу, просто привела пример, как я мыслю обычно и что испытываю. Я читаю все эти определения и ничего не понимаю. И не понимаю, что со мной. Другим моим одноклассникам это всегда давалось, почему же мне никогда ничего не было понятно? По математике могу вроде понять, когда преподаватель объясняет, но потом, когда надо применять это знание на практике, опять впадаю в ступор. Еще я очень тяжело считаю в уме, если возникает задача, касающаяся сравнения свойств между собой, то "загружаюсь по полной", начинаю подходить к этому излишне основательно и дотошно, вызывая у других недоумение. Кроме того, имею сильные проблемы со вниманием, стоит сместить фокус с одного на другое, как все рушится, все забывается. Я много играла в шахматы в детстве и постоянно впадала в ступор после каждого чужого хода, в голове мысли как будто расползались, не могла подолгу сделать ход, начинала пытаться просчитывать ходы и тут же забывала, что уже просчитала. Я могу логически прийти к чему-либо и тут же забыть всю цепочку. Может, у меня какие-то нарушения в мозге/проблемы с интеллектом/не умею в абстрактно-логическое мышление? С другими типами мышления при этом проблем нет, хорошо дается инженерная графика/ориентировка в пространстве/представление разных объектов/разгадывание головоломок. Мне говорили, что я не могу держать в голове целиком всю логическую цепочку. Это так сильно убивает самооценку, что же делать? Только, пожалуйста, не говорите про "дано-не дано", "твое-не твое", гуманитариев/технарей, считаю это полным бредом.
>>91702 >Математические знания передаются генетически и половым путём. Если это так, то почему дети великих математиков с пелёнок не решают диф. уравнения?
1 и $\sqrt{2}$ ведь невыразимы друг относительно друга рациональными коэффициентами? Значит множество $\{\sqrt{2} \cdot n, n \in \mathbb{N} \pmod{1}\}$ должно включать в себя все точки от 0 до 1 Получается мы пересчитали континуум
>>110380 (OP) Может я тебя не так понял, но перемножая sqrt(2) x N ты получишь только иррациональные числа легко доказать, что иррациональное x рациональное = иррациональное и не факт что все.
>>108146 (OP) Вместимость посуды и объём твёрдого тела это не одно и то же. Объём у арбуза есть, а вместимости нет, сколько на него не ссы. Объём не меняется от положения тела, а вместимость да. Если ты перевернёшь чашку, то не сможешь в неё нассать, но её объём, то есть объём в-ва из котораго она сделана останется неизменным.
Когда вместимость физического тела не образующего замкнутую полость называют объёмом (сосуда), то предполагают использование его в определённом положении в поле гравитации Земли, где часть ограничивающей этот объём поверхности является сегментом сферы, нормали которой совпадают с направлением силы притяжения. Сегмент этот замыкает поверхность, ограничивающую внутренний объём.
Сап, матач. Студент 2 курса меда, вопрос: что делать дальше (развиваться) в математике, если полност
Аноним08/10/23 Вск 21:04:52№109512Ответ
Сап, матач. Студент 2 курса меда, вопрос: что делать дальше (развиваться) в математике, если полностью выдрочил программу школьной математики (учился по Сканави, элементарная матеша). Хочу упороться в мат.логику, но понимаю, что все равно по базе не достаю в знаниях
>>109720 он может заниматься исследованиями (в медицине), а не медицинской практикой (т.е. лечением пациентов) это тесно связанные вещи, но всё же раздельные
как вы это понимаете? проблем с математикой не было с 7-го класса, но после начал болеть и перестал всё это понимать. Зайдя сюда я ахуел, от того что люди не просто понимают всё что написано, но и вносят свои правки, спорят и т.д. как это получилось, хорошо учились в школе/универе или самообразование интересно было бы почитать
>>101879 (OP) >как вы это понимаете? проблем с математикой не было с 7-го класса, но после начал болеть и перестал всё это понимать. У меня с математикики было 1-2 начиная с 7 класса, за последние 5 лет пытался вкотится но никак не выходило, месяц назад решил еще раз и начал немного понимать, лучше вкатываться через лекции на ютубе, где все разжевывается, книги лучше использовать как дополнение.
Математеки знаете такой труд уатхейда и рассела "принципы математики"? Или он только у нас на филосо
Аноним29/09/23 Птн 10:51:11№109141Ответ
>>109222 >>109224 > тиктак Я давно говорил, что это твой максимум, мозгов у тебя нет. Если бы ты ещё за пределами тиктака не срал, вообще хорошо было бы. Но вы, пердежи, к сожалению, пердежируете везде, откуда вас ссаными тряпками не гонят.
>>109225 >тирег на тикток Это был байт на щитпост-картинку с зумером и ты повёлся на него, как дешевка, коей ты и являешься, конструктивный петух. Посрал на тебя ещё раз, обтекай.
>>109226 >>109227 > N-петух не попадает по кнопкам Кроме тряски и тиктака ты ни на что и не способен. Свои маняаргументы ты все просрал, кроме тупого кукареканья в надежде кого-то оскорбить, ты не можешь ничего, лох без задач с отрицательным интеллектом школотрона. Ты и на этот пост что-то прокукарекаешь из-за своей школьной уверенности в том, что прав тот, кто последний пукнул. Такой тут даунятник развели, ну вы и дебилы...
Пытался перевести утверждение на язык предикатной логики и столкнулся с проблемой. Суть такова: как мне указать на то, что переменная является подмножеством другой переменной? Есть мысль сделать эту переменную предикатом, но в таком случае не понятно, какая должна быть к этому предикату переменная.
Если обувь носят на ногах, то туфли носят на ногах, если туфли - это обувь.
Я вижу 2 компонента антецедента, которые, я так понимаю, нужно соеденить конъюнкцией: 1. Если обувь носят на ногах. 2. Если туфли - это обувь. И консеквент, понятно: Туфли носят на ногах.
До этого думал через ≡ соединить обувь и туфли, но понял, что это что-то не то.
>>108929 > можно ли использовать \in в логике? Я думал, что такие символы только к множествам применяются. То есть, ты не знаешь как логические операции связаны с операциями над множествами?
>>108932 Судя по: >как мне указать на то, что переменная является подмножеством другой переменной? Есть мысль сделать эту переменную предикатом, но в таком случае не понятно, какая должна быть к этому предикату переменная. Он вообще не в курсе что такое множество истинности предиката, а просто значки посмотрел.
>>108929 Ты можешь переписать $B \subseteq A$ как $(\forall x \in B)[x \in A]$, это будет то же самое значить. Прикол предикатов в том и состоит, что ты любую парашу задать как предикат Т.е. у тебя получается тавтологичная импликация из элементарной конъюнкции из двух высказываний (это высказывания, потому что переменные в предикатах связаны квантором) и высказывания-заключения.
>>108929 Короче чел. Возьми любую книгу по дискретке, там первые две главы с большой вероятностью будут про теормнож и логики пропозициональную и первого порядка. Это на самом деле несложно
Очередной тред, посвященный основаниям математики. Основная проблема оснований - устаревшая логика, тянущаяся еще со времен Платона с Аристотелем. В наше время основаниям не хватает результатов, полученных доказательными исследованиями природы человеческого языка и сознания, проделанным в рамках Relational Frame/Field Theory. Математика - вербальное поведение человека, соответственно, логика, лежащая в ее основе, должна быть приведена в актуальное состояние, учитывающее важнейшие достижения в этой области, полученные исследователями RFT.
>>106412 Так мне-то есть где, анон. Я тут майевтикой пытался позаниматься из альтруистических побуждений. Но аноны не захотели тянуться к знаниям. Что ж... будут жестоко наказаны, как некогда говаривал ныне покойный Н.Н. Константинов. Затем он уточнял, в чём именно это будет залкючаться. Но предлагаю анонам догадаться об этом самим.
Но в целом сборников уровня Коуровской тетради по диффурам и динсистемам мне не известно.
ps. Надо понимать, что Коуровская тетрадь - это, конечно, баловство. Она никаким образом не повлияла на развитие алгебры и даже не коррелировала с ходом этого развития. Это не более, чем сборник головоломок.
Можете мне порекомендовать книги на русском/английском которые мне помогут понять какие и как мне применять практические математические формулы, например формулу действия гравитации на твердое тело а также сопротивление воздуха на это тело, типа что бы можно было придать импульс объекту и он будет физически верно себя вести в 2D/3D пространстве. Насколько я понимаю те формулы которые описаны в классических учебниках не подходят так так там результат одно число а мне нужно что бы это были координаты x, y, вроде бы должны подойти формулы из линейной алгебры но я не знаю в какую сторону копать.
Например смотрите на пикчу, формула движение точки по окружности выдает только одномерный вектор, это бесполезная формула, так как минимум нужно что бы были два результата x, y.
Нашел вот эту книгу: Bourg D., Bywalec B. - Physics for Game Developers, 2nd Edition - 2013 может быть вы знаете книги по математике которые поясняют за эту тему.
>>106274 (OP) >результат одно число а мне нужно что бы это были координаты x, y, >например формулу действия гравитации на твердое тело а также сопротивление воздуха на это тело А разве в учебниках не поясняют отношения между понятиями? Чем должны быть эти x и y? Ты понимаешь что ты получаешь в ответе этой "бесполезной" формулы? Причём тут чтение книг и скрин из википедии, может все-таки откроешь учебник по механике?
>>106274 (OP) У тебя с самыми основами беда, раз не можешь формулу из википедии расшифровать. Насколько хорошо математику с физикой знаешь, до какого класса изучал?
>>106574 >В школьных учебниках такого точно нет Чушь, вот первый попавшийся учебник по механике за 10 класс