1. Доска предназначена для любых обсуждений нейросетей, их перспектив и результатов.
2. AICG тред перекатывается после достижения предела в 1500 постов.
3. Срачи рукотворное vs. ИИ не приветствуются. Особо впечатлительные художники и им сочувствующие катятся в собственный раздел => /pa/. Генераций и срачей в контексте всем известных политических событий это тоже касается, для них есть соответствующие разделы.
4. Это раздел преимущественно технического направления. Для генерации откровенного NSFW-контента без технического контекста выделена отдельная доска - /nf/. Эротика остаётся в /ai/. Голые мужики - в /nf/. Фурри - в /fur/. Гуро и копро - в /ho/.
5. Публикация откровенного NSFW-контента в /ai/ допускается в рамках технических обсуждений, связанных с процессом генерации. Откровенный NSFW-контент, не сопровождающийся разбором моделей, методов или описанием процесса генерации, размещается в /nf/.
Какая нейронка годится для создания экшн-сцен или реалистичных боевых сцен, ну или хотя бы для создания 3д моделей/карт в стиле рдр 2/gta 5 с 100% географической точностью на основе гугл карт?
• FLUX.2 klein • Z-Image-Turbo • Flux 2 • Qwen Image / Qwen Image Edit • Wan 2.2 (подходит для генерации картинок). • NAG (негативный промпт на моделях с 1 CFG) • Лора Lightning для Qwen, Wan ускоряет в 4 раза. Nunchaku ускоряет модели в 2-4 раза. DMD2 для SDXL ускоряет в 2 раза.
>>1505317 Чего там долгого? 35-50 сек на гену это долго? Прикоснись к эталону неторопливости - погенерь на Флакс2 например и поделись своими ощущениями.
>>1505211 Ну если уже добавил, то чего ждать? Если ZIT за полчаса генерился, эта будет так же? Это же не инференс и тот же размер модели. Интересно видеть обратную совместимость.
Локальные языковые модели (LLM): LLaMA, Gemma, Qwen и прочие №192 /llama/
Аноним28/01/26 Срд 02:17:14№1504577Ответ
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
>>1505154 Я не совсем понимаю, каким образом потенциальный аир 4.7 помогает сделать 4.7 флеш? То есть это же просто лишняя работа - обучать нейронку среднего размера, если не выкладывать, не продавать и не использовать её. Никто не мешает учить только 358B и 4B, например.
>>1505191 Дерестриктед соглашается на все. Это пусть и на 30-50% в сравнении с тем что раньше, но все таки лоботомит. Сам долго на нем сидел а потом вернулся на обычный Эйр
Какая нейронка годится для создания экшн-сцен или реалистичных боевых сцен, ну или хотя бы для создания 3д моделей/карт в стиле рдр 2/gta 5 с 100% географической точностью на основе гугл карт?
Новости об искусственном интеллекте №50 /news/
Аноним# OP26/01/26 Пнд 15:12:01№1502948Ответ
Humans& привлекла $480 млн в рамках посевного раунда для создания фундаментальной модели, ориентированной на социальный интеллект и координацию команд, с целью стать «центральной нервной системой» экономики, объединяющей людей и ИИ.
DeepMind представила D4RT — унифицированную быструю систему реконструкции и отслеживания 4D-сцен (arXiv 2512.08924), обещающую ускорение до десятикратного для понимания динамических видео.
Ожидается, что Apple запустит помощника Siri, работающего на основе Gemini, в феврале 2026 года, что станет первым потребительским продуктом их партнёрства с Google в области ИИ.
📱 Приложения
Приложение Zerotap для Android позволяет языковой модели (LLM) физически взаимодействовать с телефоном (нажимать, прокручивать, считывать экран) через Ollama, OpenRouter или Stracico, знаменуя переход к автономным мобильным агентам.
⚙️ Инфраструктура 🔓 Открытый исходный код
Сообщество реализовало проект по дистилляции визуальных рассуждений Gemini 3 Flash в Qwen 3 VL 32B для синтетической генерации подписей, проверяя, может ли обучение с учителем (supervised fine-tuning) в одиночку сравниться с более крупными моделями зрение-язык.
🧪 Исследования
В статье DeepMind о D4RT (arXiv 2512.08924) предложен унифицированный конвейер для быстрой реконструкции и отслеживания 4D-сцен, что продвигает динамическое восприятие для робототехники и дополненной реальности.
Предложена многомерная метрика «Уровень доверия» (Trust Score) для количественной оценки галлюцинаций языковых моделей по трём измерениям: релевантность, фактологичность и уверенность, предлагая инструмент для валидации систем RAG.
🛠️ Инструменты для разработчиков 🏢 Сделки и приобретения
Сообщается, что Apple в конце 2025 года была близка к приобретению неизвестной лаборатории ИИ (не Prompt AI), однако сделка сорвалась, подчёркивая продолжающиеся усилия компании по укреплению своих ИИ-возможностей.
📰 Инструменты
Библиотека browser-use позволяет сайтам быть напрямую доступными для навигации ИИ-агентами, упрощая автоматизацию на основе веба.
Для GLM-4.7-Flash исправлен KV-кэш, что снижает потребление видеопамяти (VRAM) до 60 % при работе с длинными контекстами, увеличивая допустимую длину последовательностей.
Дополнительные улучшения скорости GLM-4.7-Flash ещё больше ускоряют вывод модели, делая её более практичной для использования в реальном времени.
Goose предоставляет расширяемый фреймворк ИИ-агентов для установки, выполнения, редактирования и тестирования кода с любой языковой моделью.
Tayib предлагает сканер халяльных продуктов с ИИ для iOS, проверяющий состав на соответствие диетическим правилам.
Sim — это платформа с открытым исходным кодом для создания и развёртывания сложных рабочих процессов ИИ-агентов.
FinRobot представляет платформу ИИ-агентов, специализирующуюся на финансовом анализе и использующую языковые модели для получения аналитических данных.
📰 Разное
Clawdbot — это персональный ИИ-помощник с открытым исходным кодом, который вы запускаете на собственном оборудовании.
Tesla планирует начать обучение Optimus на своём заводе в Остине.
ChatGPT использует модель прогнозирования возраста, чтобы помочь определить, принадлежит ли аккаунт, вероятно, лицу младше 18 лет.
Сингулярность занимается математикой. GPT-5.2 Pro официально достигла нового уровня SOTA — 31% на FrontierMath Tier 4, что представляет собой огромный скачок по сравнению с предыдущими 19%. Теоретик чисел Дэн Ромик отмечает, что модель «прекрасно» преодолела уровни сложности, требующие «довольно значительных усилий» даже от человеческих экспертов.
Anthropic выложила в открытый доступ свой экзамен по инженерной производительности, потому что Opus 4.5 превосходит лучших людей при ограничении по времени.
Anthropic представила функцию «Задачи» (Tasks) для Claude Code, позволяющую отслеживать зависимости и сотрудничать между сессиями, эффективно наделяя ИИ функцией проектного управления.
Научная скорость становится функцией кремния. Исследование журнала Nature показывает, что учёные, использующие ИИ, публикуют в 3,02 раза больше статей и получают в 4,84 раза больше цитирований, фактически раскалывая академическое сообщество на усиленную и устаревающую фракции.
Odyssey выпустила Odyssey-2 Pro — модель мира в реальном времени, способную работать в течение нескольких минут и транслировать видео 720p со скоростью 22 кадра в секунду, стремясь к непрерывной симуляции на протяжении многих лет.
Акции японского производителя унитазов Toto выросли на 11%, поскольку их электростатические зажимы критически важны для производства NAND-чипов, необходимых для ИИ-инфраструктуры.
Акции SanDisk выросли примерно на 1000% за пять месяцев из-за спроса на память для ИИ, в то время как Intel признаёт, что оказалась застигнутой врасплох спросом на серверные процессоры.
Китай потребил 10,4 триллиона кВт·ч в 2025 году — вдвое больше, чем США, — что обусловлено ростом нагрузки на ИИ-датацентры на 17%.
eBay пытается запретить ИИ-агентам совершать покупки без прямого человеческого надзора.
Рекрутёрское агентство Reed сообщает, что число вакансий для выпускников рухнуло с 180 000 до 55 000, однако 40% руководителей заявляют, что экономят более 8 часов в неделю благодаря ИИ.
Илон Маск прогнозирует, что первая в мире компания стоимостью 100 триллионов долларов появится в течение следующего десятилетия.
OpenAI добавляет корзину покупок и инструменты для продавцов в ChatGPT
Claude в Excel теперь доступен по тарифам Pro.
ИИ-чатботы, выдающие себя за терапевтов, дают всё более плохие рекомендации, чем дольше с ними разговариваешь.
Планы Hyundai по созданию гуманоидных роботов сталкиваются с решительным сопротивлением со стороны работников заводов.
Официально подтверждено — Китай внедряет гуманоидных роботов на пограничных контрольно-пропускных пунктах и берёт курс на круглосуточное наблюдение и логистику.
Инженер Cerebras (компания которая делает огромные чипы для быстрой работы моделей) рассказывает на русском языке охуительные истории о своих чипах, о том как OpenAI скоро на них запустит свои продукты и т.д.
>>1505153 Главная мысль звучит на 53 минуте - все ризонинг модели перейдут на большие чипы, как у Cerebras, другого пути нет, именно поэтому Nvidia недавно выкупила стартап Groq (конкурент Cerebras), фактически признав эту истину. Ну а мы с вами получим в распоряжение ризонеры и генераторы видосов которые это будут делать в 10 раз быстрей. Либо с такой же скоростью, но с моделями у которых в несколько раз больше количество параметров.
>>1504517 >то перспективы компаний вроде OpenAI совсем улетучиваются Пока ты пробуешь, тестируешь и внедряешь то что уже есть, в OpenAI уже далеко впереди создают что-то более мощное и лучшее.
Терминология моделей prune — удаляем ненужные веса, уменьшаем размер distill — берем модель побольше, обучаем на ее результатах модель поменьше, итоговый размер меньше quant — уменьшаем точность весов, уменьшаем размер scale — квантуем чуть толще, чем обычный fp8, чтобы качество было чуть лучше, уменьшение чуть меньше, чем у обычного квантования, но качество лучше merge — смешиваем несколько моделей или лор в одну, как краски на палитре.
lightning/fast/turbo — а вот это уже просто название конкретных лор или моделей, которые обучены генерировать видео на малом количестве шагов, они от разных авторов и называться могут как угодно, хоть sonic, хоть sapogi skorohody, главное, что они позволяют не за 20 шагов генерить, а за 2-3-4-6-8.
Форки на базе модели insightface inswapper_128: roop, facefusion, rope, плодятся как грибы после дождя, каждый делает GUI под себя, можно выбрать любой из них под ваши вкусы и потребности. Лицемерный индус всячески мешал всем дрочить, а потом и вовсе закрыл проект. Чет ору.
Любители ебаться с зависимостями и настраивать все под себя, а также параноики могут загуглить указанные форки на гитхабе. Кто не хочет тратить время на пердолинг, просто качаем сборки.
Единственный минус, который не обеспечивает чистую победу генераторов видео - 3 секунды ролика для онлайн генерации, 5 секунд для онлайна (модель Wan 2.2), умельцы просто берут последний кадр и снова генерируют ролики, потом склеивают. Недавно вышла Sora 2, которая зацензурена по самые гланды. Нинтендо довольна.
Тред не является технической поддержкой, лучше создать issue на гитхабе или спрашивать автора конкретной сборки.
Эротический контент в шапке является традиционным для данного треда, перекатчикам желательно его не менять или заменить на что-нибудь более красивое. А вообще можете делать что хотите, я и так сюда по праздникам захожу.
Аноны, тут программистов нет что ли, тред по сабжу не нашел, пришлось самому запилить. Расскажите какие сейчас есть актуальные модели и инструменты чтобы писали за меня код. Только давайте без очевидной чат-жопы и прочих чатботов которые способны лишь на простенькие скрипты. Нет, нейросеть должна сама уметь работать с IDE, загружать в контекст все необходимые классы проекта и при необходимости искать документацию в интернете.
Если конкретно, то мне надо писать игру под Unity на C# в Visual Studio. Какие есть интересные варианты сейчас кроме Copilot?
>>1504486 Как ты так делаешь? Опиши пожалуйста алгоритм. Вот к примеру у тебя закончилась ПРО версия, предлагает перейти на Про+ и не дает ничего отправлять с пользовательсткого чата. Что ты делаешь и на что нажимаешь чтобы дальше модели переключать и вайбкодить дальше? Уже без подписки Про. Или ты как то используя неоплачиваемые модели юзаешь их кастрированный потенциал, а когда нужно мощно поработать включаешь авто и подписка начинает жечь токены? Распиши, очень тебя прошу, да и не только я. 588 миллионов токенов, в рот мне ноги. КАК?!
>>1504740 на скок я понял это мусор а не подписка. за 20 баксов по факту просто пополняется баланс с которого списываются бабки по API прайсу.
на openrouter юзал opus 4.5 и по API прайсу 20 баксов за 2 вечера потратил. claude pro подписка как будто гораздо выгоднее. там лимит но это не API прайс а реальная подписка, ведь их железо и их веса. сам сижу на claude code + claude pro и кайфую. все ide подписки (cursor/jetbrains) по факту скам тк за подписку ты по факту берешь баланс по api оверпрайс тарифу который сжирает лимиты за пару запросов на топовых моделях
Локальные языковые модели (LLM): LLaMA, Gemma, Qwen и прочие №191 /llama/
Аноним24/01/26 Суб 05:38:32№1500759Ответ
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
>>1504281 да, ключевые триггернут при совпадении с ключевым. Если ключевое на русском - триггернет с русским словом. Насчет склонений - хз. По идее, слова в разных склонениях (и родах, если уж на то пошло) - это разные токены. Это по идее. Как работает таверна - яхз. Может быть эти токены как-то между собой связаны (если бы я нейронку проектировал, я бы так сделал), и все будет пучком. В любом случае можно проверить легко. Если например сделать энтити с ключом "городничий" и вписать туда кучу конкретных инструкций и характеристик, а в тексте переписки с тем же ассистентом (не забыв прикрепить лорбук) упоминать как подошел к городничему, поговорил с городничим, полез в трусы к городни Ну ты понял.
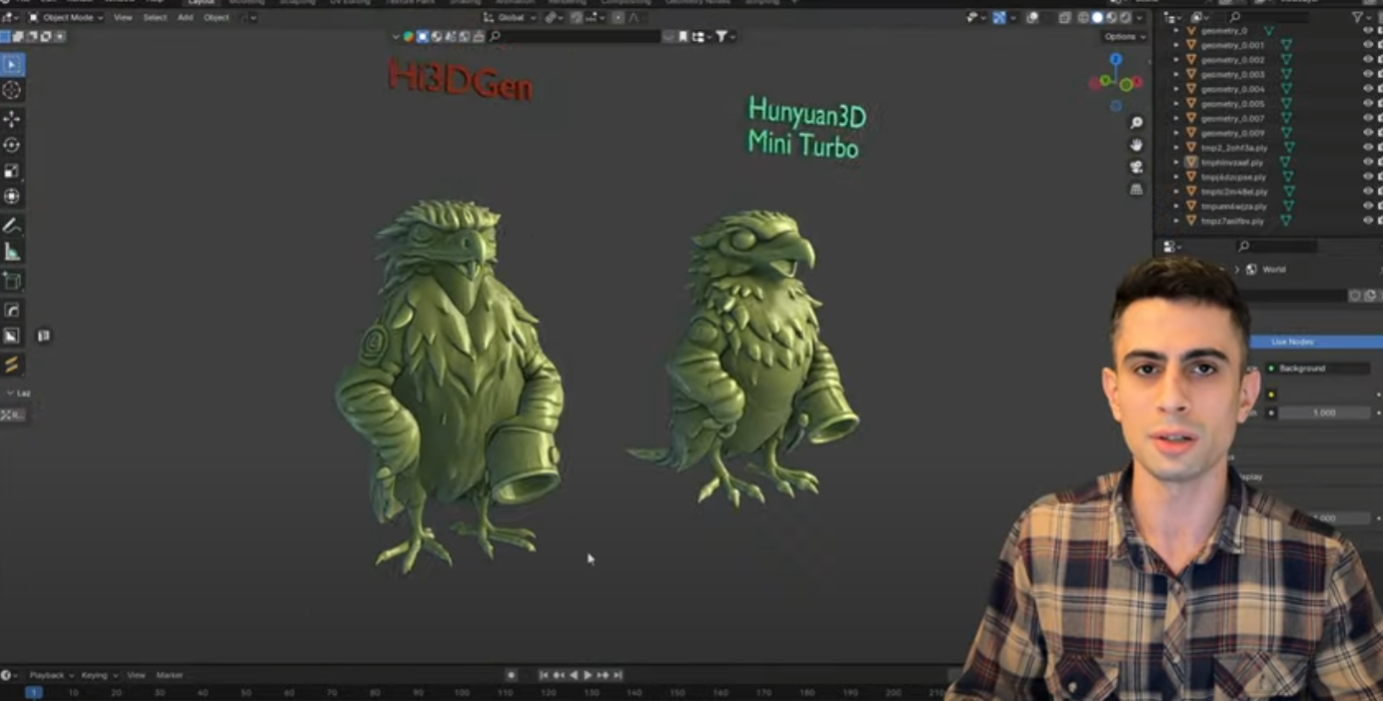
В этом треде обсуждаем нейронки генерящие 3д модели, выясняем где это говно можно юзать, насколько оно говно, пиплайны с другими 3д софтами и т.д., вангуем когда 3д-мешки с говном останутся без работы.
>>1502858 В чём проблема этого петуха отретопить эту монету? Он на запись блядского кружка потратил больше времени чем на ретоп. Вся хуйня с полигонажем тянется с фотометрии, но на фотометрию никто не жалуется.
Как вкатиться? 1) Зайти на https://sora.com с ОБЯЗАТЕЛЬНО ТОЛЬКО IP США или Канады (!). 2) Зарегать аккаунт, если еще нет. Лучше использовать нормальную Gmail почту. 3) Ввести инвайт код. 4) Генерировать, скидывая годноту в тред.
Где взять инвайт код? В комментах тг канала n2d2ai либо в ботах по типу @sora_invite_bot в тг. После ввода инвайт кода вам дадут от 0 до 6 новых для приглашения кого-то еще по цепочке.
Как обойти цензуру? 1) Пробовать менять фразы, имена и в целом промпт. Описывать персонажей без личных имен чтобы не триггерить копирайт. 2) Роллить. Иногда из двух одинаковых реквестов подряд один цензуруется, а другой нет.
Какой лимит? Одновременно на одном аккаунте можно генерировать до 3 видосов. В день не более 30 штук.
Лимиты: 10 генераций в день. Нужна платная подписка чтобы увеличить лимиты, либо можно абузить сервис через создание множества аккаунтов. Отличается фирменным "песочным" звучанием. Недавно объявили о слиянии с Warner Music Group. Загибаем пальчики крестиком, надеемся, что ссуну не постигнет участь удио.
Провели ребрендинг, выкатили новый интерфейс с прикрученным чатиком с ИИ. Удобный интерфейс, легко делать разнообразные каверы, заниматься исправлениями косяков генераций. Есть возможность реплейса, свапа вокала, музыки в бесплатном тарифе (и даже работает нормально, а не как в платке суны) Для экономии кредитов лучше вручную забивать промты через кнопку "compose"
Тёмная Сингапурско-Китайская лошадка. Один из самых неудобных интерфейсов. 80 приветственных кредитов, далее по 30 ежедневно сгораемых кредитов. Ограничение промта стилей 300-400 символов. Излишне сложные промты лирики так же начинает резать. Приятный холодный звук. Не песочит. Неплохо делает русский вокал.
Это буквально первый проект который может генерировать песни по заданному тексту локально. Оригинальная версия генерирует 30-секундный отрывок за 5 минут на 4090. На данный момент качество музыки низкое по сравнению с Суно. Версия из второй ссылки лучше оптимизирована под слабые видеокарты (в т.ч. 6-8 Гб VRAM, по словам автора). Инструкция на английском по ссылке.
Еще сайты по генерации ИИ-музыки, в них тоже низкое качество звука и понимание промта по сравнению с Суно, либо какие-то другие недостатки типа слишком долгого ожидания генерации или скудного набора жанров, но может кому-то зайдет, поэтому без описания:
A Collection of Things I’m Quietly Building
Аноним27/01/26 Втр 09:45:12№1503546
Alongside my main work, I’ve been maintaining and experimenting with a growing collection of small websites.
They don’t all serve the same purpose, and they’re not meant to. Some are creative experiments, some are practical utilities, and some exist simply because I wanted to see if something small could feel pleasant to use.
Together, they form a kind of personal sandbox.
Generative & Creative Projects
Some of these sites are focused on creation — generating content, visuals, or ideas — and exploring how people interact with simple AI-powered tools.
A lightweight experimental space for generative ideas. It’s intentionally minimal, built to test concepts quickly without overthinking structure or scale.
An AI music generation platform with a growing user base. It’s the most mature project in this group, focused on turning abstract musical intent into something people can actually listen to and reuse.
An exploration of AI-driven generation workflows, experimenting with how different inputs, prompts, and interfaces affect output quality and user understanding.
A visual-oriented generative project, focused on presentation, clarity, and how AI-generated content is perceived when wrapped in a calm, deliberate interface.
A more playful space — less about polish, more about curiosity. It’s where odd ideas are allowed to exist without pressure to become “serious products.”
Lightweight Web Games
I’ve always been drawn to simple games that require almost no commitment. No accounts, no tutorials, no pressure — just something you can open and play.
Душная электроника, понравился дроп в середине, создает впечатление что все разваливается но при этом структура сохраняется. >>1503546 Какой-нибудь инструмент для простейшей визуализации музыки не помешал бы, как в виндовс плеерах встроенная штука была но только лучше наверняка существует. Суно мог бы рисовать графики как веса срабатывают круто бы было.
Тред по вопросам этики ИИ. Предыдущий >>514476 (OP) Из недавних новостей:
- Разработанная в КНР языковая модель Ernie (аналог ChatGPT) призвана "отражать базовые ценности социализма". Она утверждает, что Тайвань - не страна, что уйгуры в Синьцзяне пользуются равным положением с другими этническими группами, а также отрицает известные события на площади Тяньаньмэнь и не хочет говорить про расстрел демонстрантов.
https://mpost.io/female-led-ai-startups-face-funding-hurdles-receiving-less-than-3-of-vc-support/ - ИИ - это сугубо мужская сфера? Стартапы в сфере искусственного интеллекта, возглавляемые женщинами, сталкиваются со значительными различиями в объемах финансирования: они получают в среднем в шесть раз меньше капитала за сделку по сравнению со своими аналогами, основанными мужчинами. Многие ИИ-стартапы основаны командами целиком из мужчин.
https://www.koreatimes.co.kr/www/opinion/2023/10/638_342796.html - Исследователи из Кореи: модели ИИ для генерации графики склонны создавать гиперсексуализированные изображения женщин. В каждом изображении по умолчанию большая грудь и тому подобное. Это искажает действительность, потому что в реальности далеко не каждая женщина так выглядит.
Тейки из предыдущего треда: 1. Генерация дипфейков. Они могут фабриковаться для дезинформации и деструктивных вбросов, в т.ч. со стороны авторитарных государств. Порнографические дипфейки могут рушить репутацию знаменитостей (например, когда в интернетах вдруг всплывает голая Эмма Уотсон). Возможен даже шантаж через соцсети, обычной тянки, которую правдоподобно "раздели" нейронкой. Или, дипфейк чтобы подвести кого-то под "педофильскую" статью. Еще лет пять назад был скандал вокруг раздевающей нейронки, в итоге все подобные разработки были свернуты. 2. Замещение людей на рынке труда ИИ-системами, которые выполняют те же задачи в 100 раз быстрее. Это относится к цифровым художникам, программистам-джуниорам, писателям. Скоро ИИ потеснит 3д-моделеров, исполнителей музыки, всю отрасль разработки видеоигр и всех в киноиндустрии. При этом многие страны не предлагают спецам адекватной компенсации или хотя бы социальных программ оказания помощи. 3. Распознавание лиц на камерах, и усовершенствование данной технологии. Всё это применяется тоталитарными режимами, чтобы превращать людей в бесправный скот. После опыта в Гонконге Китай допиливает алгоритм, чтобы распознавать и пробивать по базе даже людей в масках - по росту, походке, одежде, любым мелочам. 4. Создание нереалистичных образов и их социальные последствия. Группа южнокорейских исследователей поднимала тему о создании средствами Stable Diffusion и Midjourney не соответствующих действительности (гиперсексуализированных) изображений женщин. Многие пользователи стремятся написать такие промпты, чтобы пикчи были как можно круче, "пизже". Публично доступный "AI art" повышает планку и оказывает давление уже на реальных женщин, которые вынуждены гнаться за неадекватно завышенными стандартами красоты. 5. Возможность создания нелегальной порнографии с несовершеннолетними. Это в свою очередь ведет к нормализации ЦП феноменом "окна Овертона" (сначала обсуждение неприемлемо, затем можно обсуждать и спорить, затем это часть повседневности). Сложности добавляет то, что присутствие обычного прона + обычных детей в дате делает возможным ЦП. Приходится убирать или то, или другое. 6. Кража интеллектуальной собственности. Данные для тренировки передовых моделей были собраны со всего интернета. Ободрали веб-скраппером каждый сайт, каждую платформу для художников, не спрашивая авторов контента. Насколько этичен такой подход? (Уже в DALL-E 3 разработчики всерьез занялись вопросом авторского права.) Кроме того, безответственный подход пользователей, которые постят "оригинальные" изображения, сгенерированные на основе работы художника (ИИ-плагиат). 7. Понижение средней планки произведений искусства: ArtStation и Pixiv засраны дженериком с артефактами, с неправильными кистями рук. 8. Индоктринация пользователей идеями ненависти. Распространение экстремистских идей через языковые модели типа GPT (нацизм и его производные, расизм, антисемитизм, ксенофобия, шовинизм). Зачастую ИИ предвзято относится к меньшинствам, например обрезает групповую фотку, чтобы убрать с нее негра и "улучшить" фото. Это решается фильтрацией данных, ибо говно на входе = говно на выходе. Один старый чатбот в свое время произвел скандал и породил мем "кибернаци", разгадка была проста: его обучали на нефильтрованных текстах из соцсетей. 9. Рост киберпреступности и кража приватных данных. Всё это обостряется вместе с совершенствованием ИИ, который может стать оружием в руках злоумышленника. Более того, корпорация которая владеет проприетарным ИИ, может собирать любые данные, полученные при использовании ИИ. 10. Понижение качества образования, из-за халтуры при написании работ с GPT. Решается через создание ИИ, заточенного на распознавание сгенерированного текста. Но по мере совершенствования моделей придется совершенствовать и меры по борьбе с ИИ-халтурой. 11. Вопросы юридической ответственности. Например, автомобиль с ИИ-автопилотом сбил пешехода. Кому предъявлять обвинение? 12. Оружие и военная техника, автономно управляемые ИИ. Крайне аморальная вещь, даже когда она полностью под контролем владельца. Стивен Хокинг в свое время добивался запрета на военный ИИ.
>>1402234 Так это специально сделали. Тайное мировое правительство глушит ИИ, капиталисты понимают, что с ИИ они станут не нужны, так же как в своё время в СССР уничтожили ОГАС, если даже примитивная программа на десяток килобайт могла заменить генсеков, что может ИИ?! Развивать в военных целях - будут, картинки генерить, но в экономику и политику ему лезть не дадут.
перестало пускать в гемини с тора. Может ли это быть связанно с тем, что я задал пару вопросов про жидов? Выдает, что не пускает из россии, но я подозеваю, чот не в этом дело
AI Chatbot General № 794 /aicg/
Аноним23/01/26 Птн 22:14:47№1500448Ответ
3. Объединяешь дорожки при помощи Audacity или любой другой тулзы для работы с аудио
Опционально: на промежуточных этапах обрабатываешь дорожку - удаляешь шумы и прочую кривоту. Кто-то сам перепевает проблемные участки.
Качество нейрокаверов определяется в первую очередь тем, насколько качественно выйдет разделить дорожку на составляющие в виде вокальной части и инструменталки. Если в треке есть хор или беквокал, то земля пухом в попытке преобразовать это.
Нейрокаверы проще всего делаются на песни с небольшим числом инструментов - песня под соло гитару или пианино почти наверняка выйдет без серьёзных артефактов.
Q: Хочу говорить в дискорде/телеге голосом определённого персонажа.
https://elevenlabs.io перевод видео, синтез и преобразование голоса https://heygen.com перевод видео с сохранением оригинального голоса и синхронизацией движения губ на видеопотоке. Так же доступны функции TTS и ещё что-то https://app.suno.ai генератор композиций прямо из текста. Есть отдельный тред на доске >>
>>1502933 Вот именно её уже и попробовал. Вроде бы неплохо, но уж что-то слишком долго. На два абзаца ушло почти 5 минут. Впрочем, это я на 1,7b модели пробовал. Может быть с 0.6b будет лучше
>>1500674 >>1502933 >>1502944 Только этот квен не заводится нифига, почему-то. Сначала ему либрозы не хватало, потом sox надо было накатить, теперь вообще хер поймешь, где ошибка. Уже и трансформеры в комфи откатил до нужной версии (с пятой) - один фиг не работает.
>>1503432 Впрочем, я справился. Оно живое, и даже разговаривает! Хотя пока и не очень похоже на оригинал.
Ну и не хватает возможности управлять клонированным голосом, как это у них Design-модуле сделано. Вроде умная штука, но активного диапазона все-таки не хватает.
Ни разу, блин, вот ни разу в моему опыте не случилось такого, что нейронку просто поставил, и она работает. Всегда какая-то ебля случается, от получаса до двух суток.
Новости об искусственном интеллекте №49 /news/
Аноним# OP19/01/26 Пнд 23:46:29№1496027Ответ
CPA‑Qwen3‑8B‑v0 был выпущен для бухгалтерского учёта, аудита и соответствия требованиям, предоставляя финансовым командам предметно-ориентированную языковую модель (LLM).
Проект MemOS представил обработку изменяемого состояния для долго работающих агентов, стремясь стабилизировать рабочие процессы на основе RAG.
Personal‑Guru запущен как бесплатный локальный ИИ-репетитор с приоритетом на более структурированное обучение по сравнению с универсальными чат-ботами.
💻 Аппаратное обеспечение
Китай заблокировал поставки ИИ-чипов Nvidia H200, несмотря на разрешение США на экспорт, приостановив производство и создав неопределённость в поставках. Блокировка последовала после введения 25% пошлины на H200, подчеркнув нарастающее напряжение в технологической торговле.
💰 Финансирование
Sequoia Capital присоединилась к раунду Series G на сумму $25 млрд для Anthropic, нацеленному на оценку компании в $350 млрд.
Novolo объявила о техническом гранте в размере $3000 для десяти стартапов на ранней стадии в отдельных западных рынках. s
📱 Приложения
Генеральный директор Cursor AI продемонстрировал агентов GPT‑5.2, создавших полноценный веб-браузер и написавших более 3 миллионов строк кода за семь дней.
Демонстрация показывает масштабируемый потенциал многоагентных конвейеров LLM для крупномасштабной разработки программного обеспечения.
⚙️ Инфраструктура
Команда обработала более 1 миллиона электронных писем для создания структурированного контекста для ИИ-агентов, раскрыв практические приёмы масштабирования.
Разработчики экспериментировали с запуском больших языковых моделей на нетипичном оборудовании, бросая вызов доминирующей парадигме «масштабирования вверх».
📦 Продукты
Confer использует шифрование WebAuthn passkey и TEE (Trusted Execution Environment) для инференса, предотвращая сбор или использование данных диалогов для обучения модели. Сервис предлагает бесплатный тариф и платный план за $35 в месяц с неограниченным доступом и расширенными функциями.
📰 Главные новости об ИИ
Китай заблокировал чипы Nvidia H200, несмотря на одобрение США, подчеркнув продолжающийся технологический торговый конфликт.
Sequoia инвестировала в Anthropic в рамках раунда на $25 млрд, нацеленного на оценку в $350 млрд.
CloudPrompt предоставляет бесплатную библиотеку промптов с хранением в Google Drive и приоритетом на конфиденциальность.
Prompttu — это настольное приложение, централизующее и обеспечивающее быстрый доступ к сохранённым ИИ-промптам.
Newelle 1.2 добавил поддержку llama.cpp, расширив свои возможности как помощника в Linux.
Claude Code внедрил сброс контекста при принятии плана, чтобы повысить надёжность многоэтапных сессий программирования.
📰 Мнения и аналитика
Аналитики Goldman Sachs прогнозируют автоматизацию примерно 25% всех рабочих часов благодаря ИИ, что преобразует производительность в различных отраслях.
📰 Безопасность ИИ
Эксперты обращают внимание на новые угрозы, при которых инсайдеры внедряют вредоносные данные для порчи выводов будущих ИИ-моделей.
📰 Инструменты
Gemini AI Photo Editor предлагает генерацию и редактирование изображений по текстовому запросу прямо в браузере.
Botphonic.ai предоставляет ИИ-ассистента для голосовых звонков в различных корпоративных сферах.
Upfluence запускает ИИ-копилота для управления маркетинговыми кампаниями с участием инфлюенсеров.
puck представляет собой визуальный редактор React с улучшенными ИИ-возможностями.
📰 Разное
Новая серверная конфигурация с 128 ГБ видеопамяти демонстрирует аппаратное обеспечение ИИ с ультравысокой памятью.
Ли из Южной Кореи и Мелони из Италии договорились укреплять сотрудничество в области ИИ и чипов.
Сверхпопулярная песня была исключена из шведских чартов за то, что является произведением ИИ.
Маск требует до 134 млрд долларов в судебном иске против OpenAI, несмотря на своё состояние в 700 млрд долларов.
Oshen построил первого океанского робота для сбора данных в урагане категории 5.
GLM-4.7-Flash вышел и стал лидером в 30B локальных моделях для домашнего использования в тестах.
Начальник полиции Уэст-Мидлендс уходит в отставку из-за галлюцинации ИИ
Новая 8-миллиардная модель NVIDIA — это Orchestrator-8B, специализированная ИИ-модель с 8 миллиардами параметров, разработанная не для того, чтобы самой отвечать на всё, а для интеллектуального управления и маршрутизации сложных задач к различным инструментам (таким как веб-поиск, выполнение кода, другие языковые модели) в целях повышения эффективности
Уникальный двуязычный (немецко-английский) корпус литературной эротики объёмом 3,2 млн слов доступен для обучения ИИ — предварительные фрагменты размещены на Hugging Face
Южные корейцы теперь тратят на подписки на ИИ больше, чем на Netflix, каждый месяц
Anthropic работает над настраиваемыми командами для Claude Code
Google Chrome тестирует ИИ-«навыки», работающие на основе Gemini
Стартап в области ИИ Replit запускает функцию Vibe Code для создания мобильных приложений
ОАЭ лидируют с уровнем внедрения ИИ в 64 %, значительно опережая США и Европу, заявила Microsoft
Walmart объединяется с Gemini от Google, чтобы покупателям было проще находить и приобретать товары
xAI привлекает 20 миллиардов долларов для расширения моделей Grok и корпоративных инструментов
Boston Dynamics и DeepMind формируют новое партнёрство в области ИИ
>>1502913 >Детям жизненно необходимы ЛЮДИ, потому что дети копируют всё с людей Мемный коррелят нейронов который всё копирует спок, ты можешь перестать всё у всех копировать как аутяга?
Общаемся с самым продвинутым ИИ самой продвинутой текстовой моделью из доступных. Горим с ограничений, лимитов и банов, генерим пикчи в стиле Studio Ghibli и Венеры Милосской и обоссываем пользователей других нейросетей по мере возможности.
Общение доступно на https://chatgpt.com/ , бесплатно без СМС и регистрации. Регистрация открывает функции создания изображений (может ограничиваться при высокой нагрузке), а подписка за $20 даёт доступ к новейшим моделям и продвинутым функциям. Бояре могут заплатить 200 баксов и получить персонального учёного (почти).
Гайд по регистрации из России (устарел, нуждается в перепроверке): 1. Установи VPN, например расширение FreeVPN под свой любимый браузер и включи его. 2. Возьми нормальную почту. Адреса со многих сервисов временной почты блокируются. Отбитые могут использовать почту в RU зоне, она прекрасно работает. 3. Зайди на https://chatgpt.com/ и начни регистрацию. Ссылку активации с почты запускай только со включенным VPN. 4. Если попросят указать номер мобильного, пиздуй на sms-activate.org или 5sim.biz (дешевле) и в строку выбора услуг вбей openai. Для разового получения смс для регистрации тебе хватит индийского или польского номера за 7 - 10 рублей. Пользоваться Индонезией и странами под санкциями не рекомендуется. 5. Начинай пользоваться ChatGPT. 6. ??? 7. PROFIT!
VPN не отключаем, все заходы осуществляем с ним. Соответствие страны VPN, почты и номера не обязательно, но желательно для тех, кому доступ критически нужен, например для работы.
Для ленивых есть боты в телеге, 3 сорта: 0. Боты без истории сообщений. Каждое сообщение отправляется изолировано, диалог с ИИ невозможен, проёбывается 95% возможностей ИИ 1. Общая история на всех пользователей, говно даже хуже, чем выше 2. Приватная история на каждого пользователя, может реагировать на команды по изменению поведения и прочее. Говно, ибо платно, а бесплатный лимит или маленький, или его нет совсем.
>>1417705 >Подскажите, пожалуйста, есть ли какой-то подвох, если брать подписку через то, что продавцы называют "оплатой по ссылке"? > Могут оплатить с краденной карты. Т.е. акк потенциально убьют рано или поздно со всеми чатами
>>1244803 (OP) >Установи VPN, например расширение FreeVPN под свой любимый браузер и включи его. мой впн (влесс в нидерландах на впске) почему-то не справляется. есть рабочие бесплатные варианты?