Анончики, вот уже десять дней как познакомился с генерацией. Скажите есть ли смысл продолжать? Есть ли у меня перспективы? Десятый день всё свое свободное время я генерирую ИИ контент, делаю трейлер несуществующего фильма/сериала по Варкрафту. В целом очень увлекательно, но каждый день я сталкиваюсь с трудностями. Например довольно часто я не могу добиться нужной мне анимации. Где персонаж тупо идёт и все. Но ИИ упирается: то персонаж начинает пиздеть, то странно мотает головой, то в кадре появляется хер пойми что, то персонаж просто встает на месте. Я прописывал промт с чатом ГПТ, прописывал сам вручную. Но бесполезно. Одну сцену могу генерить по 30 раз. Пока не получу результат. В такие моменты я ловлю сильную дизмораль, начинает кипеть голова, хочется отдохнуть, чувствую усталость. В итоге чтобы сделать 3х минутный ролик я работаю по много часов уже 10 день.
>>1488545 (OP) А разве есть на HTML? Все нейросети на Python нативно запустятся. Главное найди желаемую модель, посмотри примеры использования, и пользуйся как хочешь.
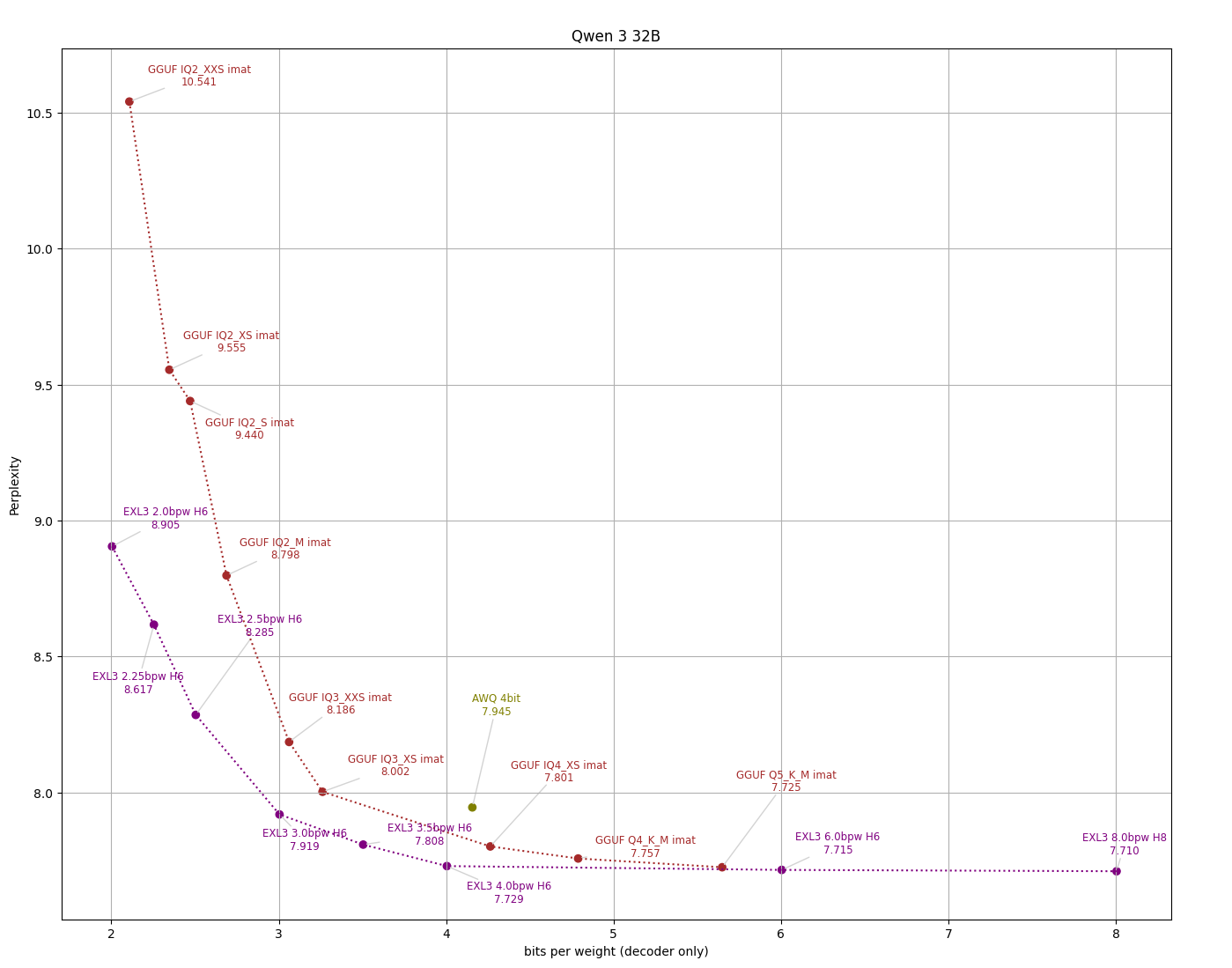
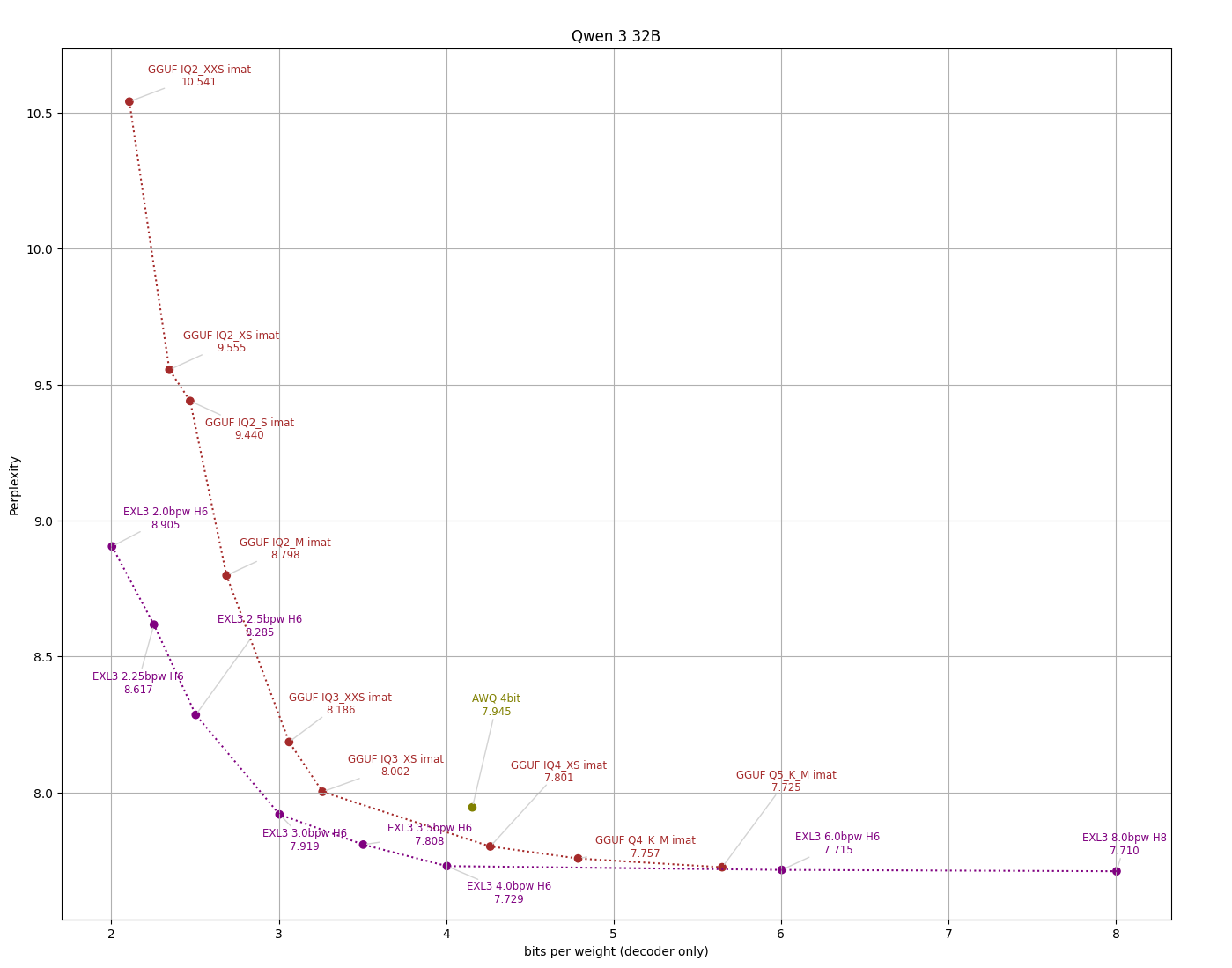
Локальные языковые модели (LLM): LLaMA, Gemma, Qwen и прочие №188 /llama/
Аноним10/01/26 Суб 18:53:06№1485378Ответ
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
>>1488581 >чтобы такое можно было запустить у вас. Интересно, но я просто убираю "всегда добавлять имя персонажа в промпт" из шаблонов и модель пишет текст для всех, кроме {{user}} (у того, единственного, отдельное сообщение). Ролеплей не структурирован, это скорее новелла, но мне так даже больше заходит. Хотя в чистом РП твой подход моделям явно больше понравится.
Добрый день. Столкнулся с такой проблемой, что гемини 3 на русике постоянно пишет "Знаешь, большинство на твоем месте..."/"Многие бы сделали... (то, это), а ты..." Как с этим бороться?
Новости об искусственном интеллекте №47 /news/
Аноним# OP06/01/26 Втр 07:24:46№1480386Ответ
Компания NVIDIA объявила, что чипы Vera Rubin находятся в полномасштабном производстве и позволят сократить затраты на запуск ИИ-моделей примерно до одной десятой от уровня Blackwell; поставки ожидаются в конце 2026 года.
На выставке CES 2026 компания NVIDIA представила набор базовых моделей для робототехники (Cosmos Transfer 2.5, Predict 2.5, Reason 2, Isaac GR00T N1.6), а также открытую симуляционную платформу Isaac Lab-Arena, которая призвана стать стандартной платформой для универсальной робототехники.
Компания NVIDIA досрочно запустила вычислительную платформу Vera Rubin для ИИ, обеспечивающую до пятикратного увеличения вычислительной мощности для обучения по сравнению с Blackwell, а также впервые представила конфиденциальные вычисления на уровне стойки.
Компания Plaud представила носимое устройство NotePin S стоимостью 179 долл. США — ИИ-гаджет для записи заметок без использования рук, нацеленный на смещение рынка заметок в сторону доступного аппаратного обеспечения.
Plaud также запустила приложение Plaud Desktop — инструмент для транскрибирования совещаний, синхронизирующий аудиозаписи между устройствами и укрепляющий кросс-платформенную экосистему Plaud для профессионалов.
SwitchBot представила голосовой рекордер AI MindClip — устройство весом 18 граммов, поддерживающее более 100 языков и оснащённое функциями ИИ-резюмирования и создания задач, тем самым расширяя конкуренцию на рынке аудиозахвата с применением ИИ.
💻 Аппаратное обеспечение
Компания NVIDIA представила архитектуру Rubin — систему из шести чипов с новым процессором Vera CPU и усовершенствованными соединениями NVLink/BlueField, ориентированную на крупных облачных провайдеров, таких как Anthropic, OpenAI и AWS.
Модуль краевых вычислений Jetson T4000 обеспечивает производительность до 1 200 FP4 TFLOPS и объём памяти 64 ГБ, обеспечивая высокопроизводительный ИИ-вывод на роботах и других устройствах на границе сети.
📦 Продукты
Google DeepMind интегрирует свою модель Gemini Robotics в гуманоидного робота Atlas от Boston Dynamics с целью улучшить контекстно-зависимое манипулирование на производственных линиях.
Hyundai начнёт массовое производство 30 000 роботов Atlas в год, начиная с 2028 года, на своём заводе в Саванне, штат Джорджия; изначально они будут выполнять задачи по упорядочиванию деталей, а позже — более тяжёлые операции.
NotePin S от Plaud обеспечивает радиус захвата звука до 9,8 футов (около 3 метров), время автономной работы до 20 часов и объём встроенной памяти 64 ГБ, позиционируя устройство как надёжную аппаратную альтернативу для ведения заметок с использованием ИИ.
AI MindClip от SwitchBot обеспечивает резюмирование разговоров в реальном времени через облачный сервис по подписке, формируя модель регулярных доходов для аксессуаров на базе ИИ.
🧠 Модели
Компания NVIDIA выпустила Alpamayo 1 — модель VLA с 10 млрд параметров и цепочкой рассуждений, обеспечивающую рассуждения автономных транспортных средств, сходные с человеческими.
Модель Gemini Robotics от Google DeepMind будет управлять гуманоидными роботами Atlas и Spot, обеспечивая контекстно-зависимое восприятие и манипуляции для промышленного применения.
Falcon-H1-Arabic (7 млрд параметров) демонстрирует наилучшие на сегодняшний день результаты в области обработки арабского языка благодаря гибридной архитектуре Mamba-Transformer и окну контекста в 256 тыс. токенов.
MiroThinker 1.5 превосходит ChatGPT-Agent по показателю BrowseComp, при этом его стоимость составляет лишь 1/20 от стоимости Kimi-K2, обеспечивая более высокую скорость вывода и лучшее соотношение интеллект/стоимость.
🔓 Открытый исходный код
Компания NVIDIA выпустила новые открытые модели (семейство Nemotron, Cosmos, Alpamayo) и инструменты для работы с данными, ориентированные на речь, мультимодальный RAG и обеспечение безопасности, с их ранним внедрением компаниями Bosch, Palantir и другими.
Falcon-H1-Arabic представляет гибридную архитектуру, которая продвигает показатели в бенчмарках для арабского языка и расширяет длину контекста до 256 тыс. токенов.
Adaptive‑P — новый сэмплер для llama.cpp, обещающий более творческую генерацию текста и предоставляющий разработчикам более тонкий контроль над разнообразием результатов.
Курируемый репозиторий на GitHub содержит чистые, автономные реализации на PyTorch более чем 50 научных статей по машинному обучению, ускоряя воспроизводимость результатов для исследователей и инженеров.
PlanoA3B представляет открытую языковую модель (LLM), оптимизированную для быстрой и предсказуемой оркестрации множества агентов, ориентированную на разработчиков приложений с агентной архитектурой.
Z.ai анонсировала скорый выход модели GLM‑Image, расширяя возможности открытых решений в области компьютерного зрения для мультимодальных задач.
📱 Приложения
Модели Cosmos Transfer 2.5, Predict 2.5 и Reason 2 от NVIDIA ускоряют разработку роботов за счёт возможностей генерации синтетических данных и поддержки рассуждений.
Alpamayo в паре с открытой симуляционной платформой AlpaSim позволяет проводить замкнутую оценку архитектур автономных транспортных средств, основанных на рассуждениях.
DGX Spark в сочетании с платформой Reachy Mini позволяет разработчикам создавать частные, настраиваемые ИИ-ассистенты с полным контролем над маршрутизацией моделей и потоками данных.
🧪 Исследования
В статье «Propagate» демонстрируется обучение «мышлящих» моделей с помощью эволюционных стратегий всего при 30 случайных возмущениях, предлагая экономически эффективную альтернативу методам, основанным на градиентном спуске.
Анализ моделей типа Mixture of Experts (MoE) выявил, что в GPT‑OSS 120B доля активных параметров может составлять всего 4,4 %, что подчёркивает существенную неэффективность вычислений в крупных экспертных моделях.
⚖️ Регулирование
Французские, малайзийские и индийские регуляторы инициировали расследования в отношении Grok от xAI после того, как модель сгенерировала сексуализированные дипфейки несовершеннолетних; Индия пригрозила отменой защиты от ответственности (safe‑harbor), если X не выполнит требования в течение 72 часов.
📰 Инструменты
Defapi агрегирует API для языковых моделей, компьютерного зрения и аудио от таких провайдеров, как OpenAI и Anthropic, в единый шлюз, снижая затраты на интеграцию для разработчиков.
Sketchflow AI генерирует UI-дизайны, интерактивные прототипы и фронтенд-код для различных платформ, оптимизируя процесс перехода от проектирования к разработке.
Pathway — это фреймворк ETL с открытым исходным кодом на языке Python, поддерживающий аналитику в реальном времени и конвейеры с участием языковых моделей, что позволяет масштабировать RAG и потоковую обработку данных.
PhotoCat AI Image Extender расширяет фон изображений путём синтеза новых пикселей, предоставляя авторам быстрый способ «раскадрировать» фотографии без ручной ретуши.
Claude Code от Anthropic использует многопоточный рабочий процесс с Opus 4.5, позволяя одному разработчику достигать результатов, сопоставимых с работой небольшой инженерной команды.
vLLM Semantic Router v0.1 Iris вводит цепочку плагинов для принятия решений на основе сигналов и модульную LoRA, обеспечивая интеллектуальную маршрутизацию между неограниченным количеством категорий моделей и встроенную функцию обнаружения галлюцинаций.
Evolink AI предоставляет единый API, объединяющий доступ к более чем 40 ИИ-моделям для генерации чатов, видео, изображений и музыки, упрощая интеграцию для разработчиков.
📰 Разное
В модели GPT‑OSS 120B (типа MoE) на каждый токен активируется лишь 4,4 % параметров.
Гуманоидный робот Boston Dynamics с искусственным интеллектом учится работать на заводе.
Судебная система штата Аляска создала чат-бота на основе ИИ. Всё прошло не гладко.
Исследователи DeepSeek применили алгоритм нормализации матриц 1967 года для устранения нестабильности в гиперсвязях.
Под БАЗУ нейрогенерации уже созданы номерные треды SD и WD+NAI. Меж тем, это всего несколько моделей, тогда как только на Фэйсе их более 112 тысяч. Этот тред для тех, кто копнул хоть немного глубже: необязательно до уровня обскурщины, выпиленной даже из даркнета, а просто за пределами того, что удостоилось своих тредов. ИТТ делимся находками и произведенными результатами.
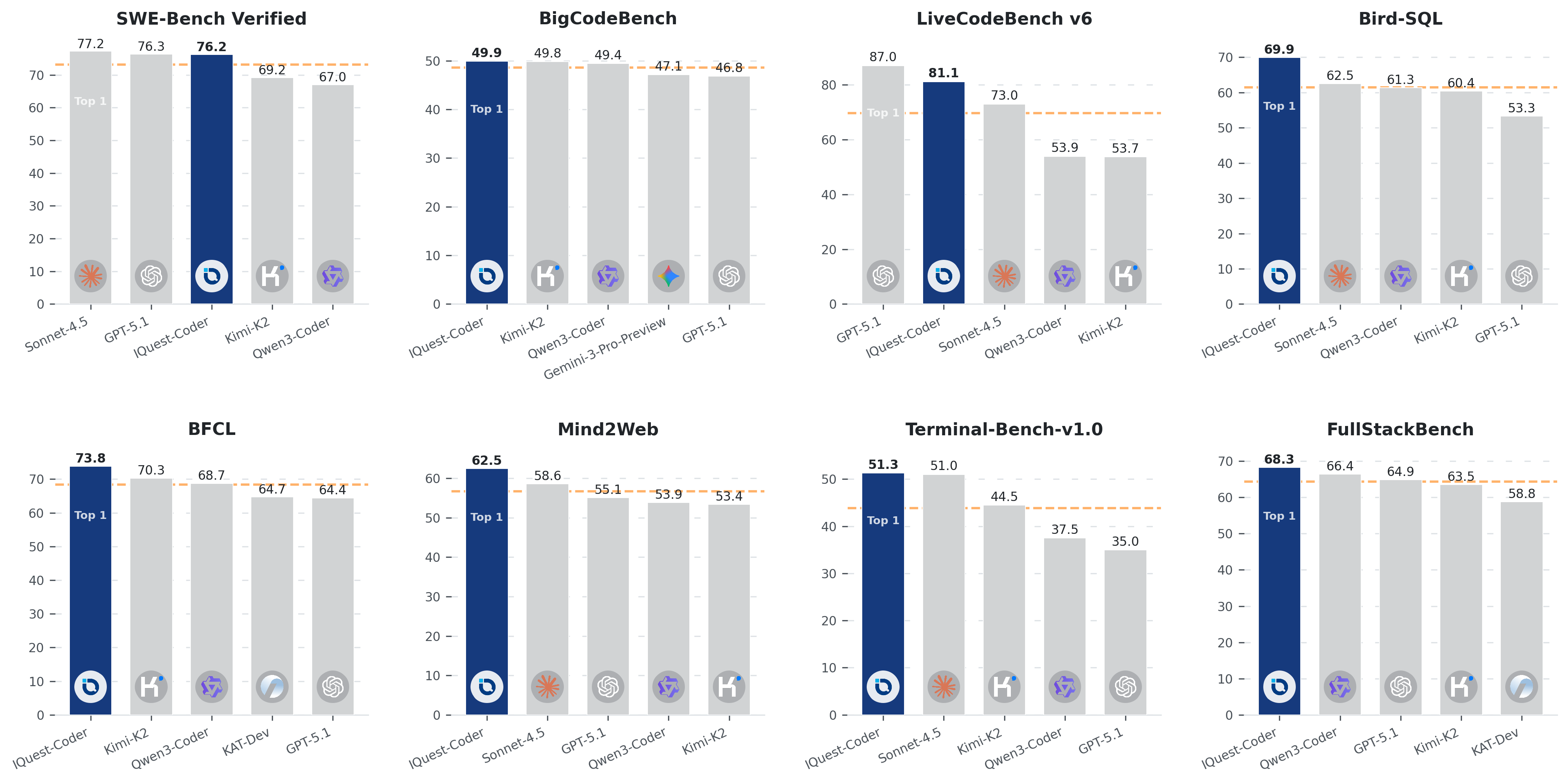
⚡️ IQuest-Coder-V1: первый опенсорс-кодер 2026 года с топ-результатами
IQuest Lab выкатили линейку IQuest-Coder-V1 — модели для реального разработки и агентных сценариев. Флагман 40B в открытом доступе, и по бенчмаркам он обходит сопоставимые закрытые модели (включая Claude Sonnet 4.5 и GPT-5.1 на SWE-Bench Verified). Вся серия доступна на https://huggingface.co/IQuestLab
Под капотом — Code-Flow Training: обучение на эволюции репозиториев, истории коммитов и «живых» трансформациях кода. Плюс Loop-варианты с рекуррентным трансформером и общими параметрами между итерациями — это экономит ресурсы и даёт прирост устойчивости на длинных задачах. Вариации: 7B / 14B / 40B, нативный 128K контекст, две линии — Instruct (прикладной кодинг) и Thinking (усиленные рассуждения).
За всем этим стоит очередной китайский хедж-фонд
сап аноны нужна помощь, стоит задача сделать локальную нейронку для учебы по электротехнике кто мож
Аноним03/10/25 Птн 17:05:56№1374086Ответ
>>1374086 (OP) Она безмятежно улыбнулась видимо при вычная к подобным свараТы выбрал мадзоку значит ты мой враг А если я оставлю им в живых Мао с реальной силой сам себе ярмо повешу! м
AI Chatbot General № 789 /aicg/
Аноним10/01/26 Суб 18:37:35№1485347Ответ
Аноны. Предлагаю обсудить как должна выглядеть архитектура и стандартный код нейроморфных процессоров. Вот есть условные блоки что воспроизводят каждый нейрон. У каждого блока есть своя память. Какими должны быть блоки для того чтоб реализовать хотяб простейшие формы нейросетей . Как должны взаимодействовать .Универсальность не требуется . Каждый чип воспроизводит свой тип нейросетей. Какими должны быть чипы для глубоких сетей , свёрточных и GAN .
>>1371090 (OP) Гугли "neural network on FPGA", всё давно уже есть.
Только какой смысл это здесь обсуждать? У тебя собственное производство чипов есть? Да у тебя наверняка даже FPGA в распоряжении нет, раз ты задаёшься такими наивными вопросами. Это всё дорогое развлечение, не для обычного двачера.
Для справки: FPGA может симулировать любой произвольный чип через программирование. Они используются для прототипирования новых чипов. Покупаешь плату с FPGA и экспериментируешь. Да, нейросетки FPGA ускоряют намного сильнее GPU, но стоимость одного чипа очень высокая и его память существенно ограничена по сравнению с CPU/GPU.
Обычно специализированные чипы создают для устоявшихся, стабильных алгоритмов. Нейросети находятся в стадии активного поиска новых, более эффективных алгоритмов, поэтому делать чипы, заточенные под конкретную архитектуру, рановато. Трансформеры те же постоянно оптимизируют...
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Лимиты: 10 генераций в день. Нужна платная подписка чтобы увеличить лимиты, либо можно абузить сервис через создание множества аккаунтов. Отличается фирменным "песочным" звучанием. Недавно объявили о слиянии с Warner Music Group. Загибаем пальчики крестиком, надеемся, что ссуну не постигнет участь удио.
Провели ребрендинг, выкатили новый интерфейс с прикрученным чатиком с ИИ. Удобный интерфейс, легко делать разнообразные каверы, заниматься исправлениями косяков генераций. Есть возможность реплейса, свапа вокала, музыки в бесплатном тарифе (и даже работает нормально, а не как в платке суны) Для экономии кредитов лучше вручную забивать промты через кнопку "compose"
Тёмная Сингапурско-Китайская лошадка. Один из самых неудобных интерфейсов. 80 приветственных кредитов, далее по 30 ежедневно сгораемых кредитов. Ограничение промта стилей 300-400 символов. Излишне сложные промты лирики так же начинает резать. Приятный холодный звук. Не песочит. Неплохо делает русский вокал.
♫Elevenlabs♫ elevenlabs.io
Очень тёплый звук. По звуку прям конфетка, но... Без платки делать там практически нечего. ______________
Это буквально первый проект который может генерировать песни по заданному тексту локально. Оригинальная версия генерирует 30-секундный отрывок за 5 минут на 4090. На данный момент качество музыки низкое по сравнению с Суно. Версия из второй ссылки лучше оптимизирована под слабые видеокарты (в т.ч. 6-8 Гб VRAM, по словам автора). Инструкция на английском по ссылке.
Еще сайты по генерации ИИ-музыки, в них тоже низкое качество звука и понимание промта по сравнению с Суно, либо какие-то другие недостатки типа слишком долгого ожидания генерации или скудного набора жанров, но может кому-то зайдет, поэтому без описания:
>>1485770 Для ролеплея на русском хороша Saiga Nemo 12B, цензуры почти нет, обходится системным промптом. Для других задач тоже хороша, но не самый топ. На всю твою GPU может поместиться (6-7ГБ из твоих 8ГБ как понимаю), будет летать.
Для остальных задач очень рекомендую "GPT-OSS 20B", из минусов цензура. Из плюсов лучшее соотношение скорости/интеллекта. Будет тебе десятки токенов в секунду генерировать даже на CPU, можно настраивать силу "мышления". От OpenAI.
Предел контекста можешь смело выставлять около ~8-16к, а сильно много нагрузят память (128к контекста может занять в разы больше чем сама модель). Если ошибки, то так уж и быть ~2-4к.
Модельки то может и видят весь контекст, ты всё сделал правильно, но это проблема их обучения - они часто обучаются лишь на одиночных парах "вопрос-ответ", длинные диалоги у подавляющего большинства моделей проблемные. Может, в пределах 1-2к адекватный контекст, дальше уже как в помутнении. Зависит от моделей, узнать можно в основном на опыте.
Если чат ультра-долгий, и явно не на пару тысяч токенов, то фреймворк может иногда автоматически забывать часть диалога. Лечится если выставлять контекст больше (8-16к+), если превышаешь потолок то либо ошибки пишет, либо как я уже сказал - физически забывает часть.
Чтобы сгладить углы, можешь качать более "жирные" версии той же модели. Ты же видел там Q3, Q4, Q5 и т.д. Можешь брать Q6_K_M если будет позволять место, немного поможет. Можно и q8 если жиру хочется, но разница между ним и q6_k_m мизерная. Но и твои q4_1 вполне норм, это в районе стандарта. Учти, что у GPT-OSS-20B по умолчанию оригинал в MXFP4 (как q4), лучше его и качать если будешь.
Могу ещё посоветовать понижать температуру, это степень "рандомности" выбора ответов. Держать лучше в районе 0.4-0.7. По умолчанию стоит "1" обычно, можно так и оставлять иногда для разнообразия.
К сожалению крутой ответ насчёт "запоминания ключевых событий" не могу дать, может тебе тут ещё подскажут. Обычно это делается либо вручную, то есть сам записываешь и переносишь в новую переписку самое важное (90% юзеров обычно так и делают, как я видел), либо через плагины/скрипты.
Как делаются все эти пересказы фильмов в тиктоке через нейросети с субтитрами c музыкой на фоне, с правильными подобранными сценами из пересказа, ИИ-шной озвучкой пересказа фильма. Ниже прикрепил пример
>>1479416 (OP) Обычно это полу-ручная работа? Не знаю ни одного хорошего примера, где бы это всё полностью делегировалось нейросетям. Как я это сам вижу, такие видео делают люди, для которых нейросети как легальный костыль/бустер, т.к справляются достаточно хорошо на их взгляд.
В теории моожно конечно попробовать на 98% автоматизировать, но готовых систем тоже не видел. А так есть какие-то конечно, отдельные как минимум (нарезка, сценарий, озвучка, а субтитры это вообще встроенная функция CapCut)
Оффлайн модели для картинок: Stable Diffusion, Flux, Wan-Video (да), Auraflow, HunyuanDiT, Lumina, Kolors, Deepseek Janus-Pro, Sana Оффлайн модели для анимации: Wan-Video, HunyuanVideo, Lightrics (LTXV), Mochi, Nvidia Cosmos, PyramidFlow, CogVideo, AnimateDiff, Stable Video Diffusion Приложения: ComfyUI и остальные (Fooocus, webui-forge, InvokeAI)
Терминология моделей prune — удаляем ненужные веса, уменьшаем размер distill — берем модель побольше, обучаем на ее результатах модель поменьше, итоговый размер меньше quant — уменьшаем точность весов, уменьшаем размер scale — квантуем чуть толще, чем обычный fp8, чтобы качество было чуть лучше, уменьшение чуть меньше, чем у обычного квантования, но качество лучше merge — смешиваем несколько моделей или лор в одну, как краски на палитре.
lightning/fast/turbo — а вот это уже просто название конкретных лор или моделей, которые обучены генерировать видео на малом количестве шагов, они от разных авторов и называться могут как угодно, хоть sonic, хоть sapogi skorohody, главное, что они позволяют не за 20 шагов генерить, а за 2-3-4-6-8.
Что-то активность нулевая. Кто-то вник в ltx2 детально? Есть пример лучшего воркфлоу? Я пока только запустил пример через разорванные файлы киджая. Зачем он их распотрошил, кстати? Есть в этом смысл? Расскажите, что узнал, покидайте годные ссылки, которые пробовали.
собственно, 20 лвл, сделал нейронку, где можно задать любые параметры характера для нейро-девочки, говорит на любые темы по сексу не стесняясь в словах, ну я и подрочил на такое, могу ли я себя считать нейрофилом ? (к слову, это была лучшая дрочка за последний год)
душно, но ты ее не создал, ты вязл готовую обученую на датасетах - deepseek, обучение это когда только токенизатор пиздишь на крайняк, ну на самый край данные для обучения тоже пиздишь, а тут готовая неронка уже ))))
периодически юзал notebooklm. был гуглакк на андройде под ру рынок без симки и без номера, офк. прост на ведре акк сделан и всё. как с квн, так и без юзался неск лет. недавно отлетел доступ к нотбуклм. вот вопрос собственно. как регать гуглакк из рф сейчас надо, чтобы был доступ к нотбуклм и т.д.? как сами делали? что посоветуете?
помогите, пожалуйста, я умираю... сир плиз ду хелп ма фемили даинг и т.д.
над купить ведро с глобальной прошивкой, как серый импорт китайский? или какие варианты? чё делат... где обычно ищите обходы и т.д.? умоляю, Анончик... подскажи...
Какой ии делает видео интервью. видел много таких видосов в ТТ. Например 2 обезьяны обсуждают людей и тп. Сам хочу юзать 2-3х людей в видео. Если ии платный - ок