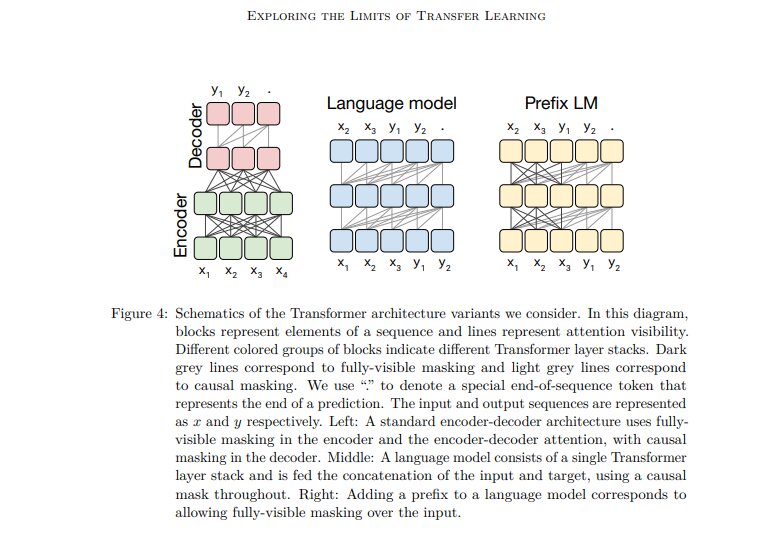









































Нейросетевая фотоника как средство против энергетического ИИ-кризиса
Аноним
09/10/24 Срд 03:04:12
№
441