Обсуждаем развитие искусственного интеллекта с более технической стороны, чем обычно. Ищем замену надоевшим трансформерам и диффузии, пилим AGI в гараже на риге из под майнинга и игнорируем горький урок.
Я ничего не понимаю, что делать? Без петросянства: смотри программу стэнфорда CS229, CS231n https://see.stanford.edu/Course/CS229 (классика) и http://cs231n.stanford.edu (введение в нейроночки) и изучай, если не понятно - смотри курсы prerequisites и изучай их. Как именно ты изучишь конкретные пункты, типа линейной алгебры - дело твое, есть книги, курсы, видосики, ссылки смотри ниже.
Почему python? Исторически сложилось. Поэтому давай, иди и перечитывай Dive into Python.
Можно не python? Никого не волнует, где именно ты натренируешь свою гениальную модель. Но при серьезной работе придется изучать то, что выкладывают другие, а это будет, скорее всего, python, если работа последних лет.
Стоит отметить, что спортивный deep learning отличается от работы примерно так же, как олимпиадное программирование от настоящего. За полпроцента точности в бизнесе борятся редко, а в случае проблем нанимают больше макак для разметки датасетов. На кагле ты будешь вилкой чистить свой датасет, чтобы на 0,1% обогнать конкурента.
Количество статей зашкваливающее, поэтому все читают только свою узкую тему и хайповые статьи, упоминаемые в блогах, твиттере, ютубе и телеграме, топы NIPS и прочий хайп. Есть блоги, где кратко пересказывают статьи, даже на русском
Где ещё можно поговорить про анализ данных? http://ods.ai
Нужно ли покупать видеокарту/дорогой пека? Если хочешь просто пощупать нейроночки или сделать курсовую, то можно обойтись облаком. Google Colab дает бесплатно аналог GPU среднего ценового уровня на несколько часов с возможностью продления, при чем этот "средний уровень" постоянно растет. Некоторым достается даже V100. Иначе выгоднее вложиться в GPU https://timdettmers.com/2019/04/03/which-gpu-for-deep-learning заодно в майнкрафт на топовых настройках погоняешь.
Когда уже изобретут AI и он нас всех поработит? На текущем железе — никогда, тред не об этом
Кто-нибудь использовал машоб для трейдинга? Огромное количество ордеров как в крипте так и на фонде выставляются ботами: оценщиками-игральщиками, перекупщиками, срезальщиками, арбитражниками. Часть из них оснащена тем или иным ML. Даже на швабре есть пара статей об угадывании цены. Тащем-то пруф оф ворк для фонды показывали ещё 15 лет назад. Так-что бери Tensorflow + Reinforcement Learning и иди делать очередного бота: не забудь про стоп-лоссы и прочий риск-менеджмент, братишка
Список дедовских книг для серьёзных людей Trevor Hastie et al. "The Elements of Statistical Learning" Vladimir N. Vapnik "The Nature of Statistical Learning Theory" Christopher M. Bishop "Pattern Recognition and Machine Learning" Взять можно тут: https://www.libgen.is
Напоминание ньюфагам: немодифицированные персептроны и прочий мусор середины прошлого века действительно не работают на серьёзных задачах.
>>1151064 (OP) >Когда уже изобретут AI и он нас всех поработит? >На текущем железе — никогда, тред не об этом Ящитаю что это возможно. GPT показал что он может хранить вполне осмысленную информацию о мире и строить множество связей между абстракциями. Проблема лишь в том как эта информация представлена и каким обрмзом создавать новые связи в процессе работы.
Почему популярные нейронки так долго тренируют? Насколько я понимаю, все стремятся найти какой-то глобальный минимум, избежав локального. Вот этот глобальный минимум ищется очень долго - мелкими осторожными шажками. Поэтому всё так долго, да? Например, чтобы на 99% гарантировать точность?
Допустим, меня не интересуют ни глобальный, ни локальный минимумы. Мне нужна манёвренность: - посчитали 1-й слой -> сразу подкрутили его веса; - посчитали 2-й слой -> сразу подкрутили его веса; - посчитали N-й слой -> выдали ответ -> ждём ввод. Нормальная же скорость будет? Не придётся ждать нескольких месяцев - обучение на скорости работы?
Конкретной задачи нет, я хочу только разобраться, конкретно чему может научиться такая нейросеть. Датасета, соответственно, тоже нет, и правил для валидации результатов тоже не придумал - меня интересует пока лишь скорость подкрутки под произвольные сигналы из входного потока. Дальше разберёмся, к чему можно подключить и как именно интерпретировать выходные сигналы нейросети.
А то все туториалы по нейросетям сводятся к: 1. Загрузить датасет (у меня нет); 2. Задать цель тренировки (у меня нет); 3. Ждать N дней/месяцев (зачем и почему?); 4. Протестировать аккуратность (мне не нужно). Как-то странно, на мой взгляд. Хочу разобраться.
>>1152913 >Насколько я понимаю, все стремятся найти какой-то глобальный минимум, избежав локального. Лол, нет. Для гроккинга сетки нужно тренировать ещё в 1000-10000 раз дольше, буквально. >меня интересует пока лишь скорость подкрутки под произвольные сигналы из входного потока Ты конечно можешь поставить lr хоть в единицу (вместо традиционных 0,0005), но сеть так будет ебашить, что мало не покажется. >- посчитали 1-й слой -> сразу подкрутили его веса; Эм, прочитай, что такое обратное распространение ошибки. Намекаю- оно идёт в обратную сторону, от последнего слоя к первому, и соответственно требует градиента на всех слоях. Короче пройди какие-нибудь машобчик курсы из шапки, ты пока сильно плаваешь в теме.
>>1152913 Ты это сообщение написал нейросетью с галлюцинациями, ты в курсе? Словно животное высрал порцию бессмысленного бреда.
>>1153095 > Для гроккинга сетки нужно тренировать ещё в 1000-10000 раз дольше, буквально. Нейросетки после грокинга выстраивают веса под "модель мира" или вроде того. Но это полная хуйня потому что это не модель абстракций объектов и отношений между ними, а модель основанная на словаре в пространстве параметров. Нужно выкинуть нахуй словарь и заменить его абстракциями объектов, тогда обучение будет занимать недели две или меньше, за пару дней нахуй. Это если не считать время обучение LLM для парсера языка. Надеюсь никто не успеет спиздить эту идею пока я хуйней страдаю и сам не нахуячу нейросеть такую
Кстати параметры при грокинге выстраиваются в замкнутые контуры, если считать по векторам, и в живом мозге тоже такая хуйня есть.
>>1153095 >тренировать ещё в 1000-10000 раз дольше А я читал, что чем дольше тренируешь, то тем хуже нейросетка файнтюнится. Т.е. генерализация сильно ухудшает адаптивность сетки под новые задачи... Следовательно, для дальнейшей работы лучшими нейросетями являются недотренированные.
>что такое обратное распространение ошибки >соответственно требует градиента на всех слоях >Короче пройди какие-нибудь машобчик курсы Хе-хе-хе, это ты недостаточно знаешь.
Обратное распространение ошибки (backprop) - один из многих способов поиска решения. Помимо него существует масса других, сильно отличающихся.
Для сравнения, ты можешь вообще не калибровать отдельные веса, а разворачивать их из аналога ДНК, мутируя эту ДНК подобно биологической. Это будет симулятор эволюции - генетический алгоритм. Ему достаточно посчитать эффективность нейронки в решении задачи и сравнить с другими вариантами, не трогая слои/нейроны/веса любого из вариантов. Конечно, это тоже лишь один из многих способов поиска, не самый эффективный на практике.
Но он мне не подходит. Я рассматриваю вариант биоподобного обучения, когда нейрон настраивается, полагаясь только на "локальную" информацию - т.е. собственную активацию и активацию нейронов, что непосредственно участвуют в его активации: https://ru.wikipedia.org/wiki/Теория_Хебба Опять же, существует огромная масса вариантов "локального обучения", т.к. у него есть сложности со стабильностью - нейроны слишком задрачивают соединения и остаются активными всегда, лол, либо бросают все свои соединения, остаются неактивны. Пофиксить можно, нужны определённые "костыли".
Однако, есть преимущества. В частности, нейронка адаптируется под входные данные максимально натуральным способом. Т.е. вместо инопланетных паттернов она сразу вырабатывает то, что мы от неё ожидаем, и всего за ~5 эпох опережает бэкпроп в аккуратности результата, но потом отстаёт. Т.е. теоретически, это более эффективный способ, если необходимо обрабатывать данные как они есть (поддерживая интерпретируемость нейросети), не выжимая каждый 1% аккуратности из нейронки.
На практике бэкпроп доминирует, потому что он позволяет любой мартышке с клавиатурой дать нейронке примитивные пары данных наподобие: >кошка.jpg == "кошка" >собака.jpg == "собака" И нейронка с бэкпропом где-то через 100500 эпох гарантированно научится различать кошек и собак (инопланетным способом, который легко ломается фотографией рандомного шума на маске человека). Поэтому бэкпроп задрочили до дыр и суют везде...
Короче, бэкпроп мне принципиально не подходит - поскольку оптимизирует всю нейронку в целом на практическое решение конкретной задачи, которой, повторяюсь, у меня нет, т.е. я не могу задать пары "входящий вопрос" == "верный ответ". Мне нужно "обучение без учителя", но только самое быстрое, на уровне пинга в онлайн-игре или что-то вроде того.
>>1154049 >высрал порцию бессмысленного бреда После нескольких часов чтения Reddit твой мозг превращается в жидкую кашицу. Шизофреников на реддите неожиданно больше, чем даже на двачах...
>это не модель абстракций объектов >заменить его абстракциями объектов LLM, обученная исключительно на тексте, имеет эти "абстракции объектов". Да, они не связаны ни с чем (помимо других абстракций), поскольку у модели не было "жизненного опыта" кроме "чтения текстов". Поэтому языковая модель имеет проблемы с такими визуальными задачами, как поиск пути на графе. Но несмотря на нехватку визуальной информации и пространственного понимания, нейронка всё же оперирует внутри себя абстракциями объектов, а не словами, описывающими эти объекты.
Я считаю, что основная сложность в обучени чисто текстовых моделей подобна сложности в обучении слепоглухонемых детей: чтобы понять, что с ней пытаются разговаривать, и научиться отвечать, ей необходимо создать модель мира, не опираясь на привычные нам зрение, слух и другие ощущения; представьте себя слепым, глухим и неподвижным, ощущающим ритмичные покалывания - как скоро получится понять, что эти покалывания - язык, и научиться рационально взаимодействовать с ним?
Я не особо интересовался "мультимодальными" LLM. Насколько понимаю, часто пытаются сделать чисто распознаватель картинок, формулирующий описание, поступающее на вход основной текстовой модели - естественно, это неправильно. Но главная проблема в отсутствии связи между картинкой и текстом. Т.е. в идеальном варианте нейронка должна обучаться на потоковых данных с видеокамеры (поэтому нужна максимальная скорость), а не на текстовой копии Википедии с редкими иллюстрациями.
В общем... Основное препятствие - бэкпроп. Из-за доминирования бэкпропа альтернативы почти не рассматриваются. Но он принципиально не может адекватно решить задачу, которую решает мозг - восприятие реальности и адаптация к ней почти в реальном времени (как я понимаю, пинг у мозга чрезвычайно высокий и мы видим не реальность, а собственную модель реальности - устаревшую на несколько сотен миллисекунд как минимум, а то и на несколько секунд/минут в редких случаях).
Алсо, я считаю, что масштаб не обязателен. Бэкпропу требуется огромный масштаб нейросети, чтобы найти подходящее решение чрезвычайно сложной задачи - поэтому LLM раздуло до невероятных масштабов. Восприятие реальности как таковое несложно и для большинства задач хватило бы и дюжины нейронов (искусственных, конечно; в мозгах много "лишнего"), расположенных сразу после блока восприятия и непосредственно перед моторным блоком.
К сожалению, большинство обучающих материалов сфокусированы на использовании бэкпропа...
>>1151064 (OP) попросил гпт 4.5 сделать улучшение для шапки не читал:
Обсуждаем развитие искусственного интеллекта с более технической стороны, чем обычно. Ищем замену надоевшим трансформерам и диффузии, пилим AGI в гараже на старых ригах из-под майнинга и игнорируем горький урок.
Я ничего не понимаю, что делать? Без петросянства: изучай классику Stanford CS229 (https://see.stanford.edu/Course/CS229) и введение в нейроночки CS231n (http://cs231n.stanford.edu). Если что-то непонятно — проверь prerequisites (линейная алгебра, базовый матан, программирование). Формат обучения — книги, курсы, видосы, ссылки ниже.
Почему Python? Исторически сложилось, экосистема огромная. Читай Dive into Python.
Можно не Python? Можно, но придется изучать код других, а это почти всегда Python.
Что почитать для вкатывания? - http://www.deeplearningbook.org (классика от Ian Goodfellow) - https://d2l.ai/index.html (примеры и код) - Николенко «Глубокое обучение» (на русском, понятный, но охват поменьше) - Франсуа Шолле «Глубокое обучение на Python»
Любая книга старше года — частично устарела, но основы те же.
Учти, спортивный deep learning отличается от работы примерно так же, как олимпиадное программирование от продакшена. На Kaggle борются за десятые процента, в жизни чаще нанимают больше размечающих данных.
Количество статей огромное, обычно следят за своей темой и хайпом (блоги, X, YouTube, Telegram, топы конференций). Есть отличные блоги и каналы на русском.
Когда AI поработит человечество? Не в этом треде и не на текущем железе.
А что насчет ML и трейдинга? Боты активно используют ML на крипте и фонде. Tensorflow + Reinforcement Learning тебе в руки, не забывай про риск-менеджмент и стоп-лоссы.
Классика ML для серьезных людей: - Trevor Hastie, «The Elements of Statistical Learning» - Vladimir Vapnik, «The Nature of Statistical Learning Theory» - Christopher Bishop, «Pattern Recognition and Machine Learning»
>>1154273 > После нескольких часов чтения Reddit твой мозг превращается в жидкую кашицу. Не читай эту хуйню вообще. Смотри видосики от новучных блогеров и читай научные статьи, разбирайся в работах топовых специалистов. > LLM, обученная исключительно на тексте, имеет эти "абстракции объектов". > нейронка всё же оперирует внутри себя абстракциями объектов, И да и нет. Это не объекты, а абстракции над токенами, а не над объектами. Они могут как совпадать с объектами, так и не совпадать из-за чего модель шизоидная и не может в логику. > ей необходимо создать модель мира, не опираясь на привычные нам зрение, слух и другие ощущения; Это всё хуйня. В нейросетях вообще нету привычной картины мира потому что она не опирается на объекты, а на токены. Мозг за миллиарды лет эволюции имеет структуры для оперирования объектами и временем, в нейросетях этого тупо нет. > Я не особо интересовался "мультимодальными" LLM. > Т.е. в идеальном варианте нейронка должна обучаться на потоковых данных с видеокамеры (поэтому нужна максимальная скорость), а не на текстовой копии Википедии с редкими иллюстрациями. Хуйня. Все эти GPT предообучены на терабайтах текста и именно из-за этого текста они начинают "воспринимать" картинки и рисовать их. Они буквально прочитали весь интернет и стали способны представлять себе какую-то "модель мира". Но опять, эта модель мира не основана на объектах, она основана на хуйне. > В общем... Основное препятствие - бэкпроп. Потому что он хорош для обучения. Есть результат и есть выход, который нужно подстроить под результат. > Но он принципиально не может адекватно решить задачу, которую решает мозг - восприятие реальности и адаптация к ней почти в реальном времени Полная хуйня. Обратное распространение ошибки это всего лишь алгоритм для обучения, а ты говоришь про общую архитектуру сети и то что происходит во время её работы.
Рассматривай P (pre-trained в GPT) и backpropagation как что-то что тренирует нейросеть на создание "модели мира". То что у нас заложено в днк - нейросети создают через pre-trained на терабайтах текстов. Это не совсем верно в деталях, но в целом так.
>>1154282 >Они могут как совпадать с объектами, так и не совпадать из-за чего модель шизоидная и не может в логику. Ну, тут может быть только два исхода: 1. Абстракции не совпадают с реальностью: предсказания нейронки некорректные и бэкпроп крутит педали в каком-то другом направлении. 2. Абстракции совпадают с реальностью: предсказания нейронки корректны и бэкпроп больше не крутит педали (в идеале, конечно). "Горький урок" прав в том, что если накинуть 100500 видеокарт на задачу, решение точно будет найдено... когда-нибудь - возможно, через тысячу лет бэкпропа. Поэтому закладывать какие-то особые абстракции не обязательно - они в любом случае формируются.
А у мозга преимущество в том, что за миллионы лет эволюции сложился удачный генетический хардкод, изначально закладывающий чёткие абстракции; т.е. нейронки мозга не рандомно инициализируются. Свёрточные нейронки, например, вдохновлены расположением нейронов в колонках, что намного эффективнее описывает визуальную информацию (теоретически, любую информацию в принципе).
Проблема в том, что люди слишком мало знают об устройстве мозга, чтоб повторить нужные структуры (избежав миллионов лет симуляции эволюции). Т.е. было бы это так просто - давно бы уже сделали...
>она не опирается на объекты, а на токены Токены - это просто какие-то данные. LLM могла бы оперировать байтами бинарных данных не хуже, чем токенами (обрывками слов). Просто токенами вроде эффективнее обучать для реальных (бизнес) задач. Смысл в том, что если нейронка правильно выдаёт следующий токен, то у неё 100% есть достаточно правильная абстракция над реальным миром (в конкретном вопросе, во всяком случае).
>Все эти GPT предообучены на терабайтах текста и именно из-за этого текста они начинают "воспринимать" картинки и рисовать их. >эта модель мира не основана на объектах Лол. Во-первых, с чего взял, что текст обязательно необходим для восприятия и рисования картинок? Генераторы картинок могут обучаться и без текста - текстовый интерфейс нужен только для удобства пользователей. Без текста пришлось бы вводить, например, числовые ID нейронов для активации.
Во-вторых, какие объекты тебе нужны? В мозге нет специальной магии с ярлыком "объект", там только нейронные колонки и их активность (если говорим о неокортексе, который и видит все эти "объекты").
Я думаю, GPT мог бы иметь правильную картину реальности, но на это нужно слишком много лишних вычислений из-за неудачно популярного бэкпропа (и отсутствия железа для ускорения альтернатив).
>он хорош для обучения. Есть результат Он хорош только для мелких моделек и суперузких задачек наподобие "отличить кошек от собак", да и то фейлится из-за нахождения странных решений.
>всего лишь алгоритм для обучения Для обучения с учителем. Мозг обучается совсем без "учителя" (не путать с учителем в школе), и не считает градиент всех своих десятков миллиардов нейронов. Какие-то глобальные сигналы в мозге есть, но это не обратное распространение ошибки, а что-то другое.
>"модели мира". То что у нас заложено в днк Настолько точная модель мира, какая есть в GPT, в молекулу ДНК даже не поместится, лол. Если тупо сравнивать объём информации, у ДНК 750 МБ - но с повторами, а у GPT до терабайта, которые никак не сжимаются ещё сильнее (т.е. повторов нет). Плюс новорождённые ничего не знают и не понимают, а языковые модели уже давно умнее 99% взрослых.
Поэтому это совершенно некорректное сравнение. Эволюция мозга нашла не только оптимальную архитектуру (колонки в коре), но и алгоритм для их обучения (в основном - локальный, но также ещё специальные костыли, типа боли и удовольствия).
Т.е. GPT больше похож на кусочек мозга взрослого, образованного человека, который просмотрел весь Интернет, но алгоритм обучения (и файнтюна) у него совершенно не подходит для быстрых изменений - например, если вдруг столица какого-то государства изменит название, GPT будет сложнее переобучить в сравнении с человеческим мозгом (как минимум, потребуется множество примеров). Поэтому многие надрачивают на "промпт инжиниринг", а не файнтюн (логичнее было бы дообучать, а не срать в контекст волшебными заклинаниями и надеяться на удачу).
Вообще, подумай сам. Вот у глубокой нейронки слои: 1. Ближе к вводу - мелкие абстракции (слова и т.п.). 2. Ближе к середине - абстракции крупнее (объекты). 3. Ближе к выходу - большие абстракции (например, принципиальный отказ выполнять что-то опасное). Интуитивно очевидно, что мелочь можно понять чрезвычайно быстро на минимальном датасете, а большие понятия редко меняются. Для обучения на терабайтах текста тебе нужно только добавлять абстракции среднего уровня - новые объекты или действия с ними. Но бэкпроп вычисляет градиент полной нейросети и пытается максимально туго затягивать веса везде, на любую задачу. Это тупое разбрасывание ресурсами без реальной пользы.
Конечно же, ты можешь применить костыли: - заморозить часть слоёв, обучая другие; - нарастить новые слои и обучать только их; - расширить слои сбоку и обучать добавленное. Но откуда тебе знать, что нужно обучать, а что нет? Очевидно, было бы лучше, если бы алгоритм для обучения автоматически определял, что требуется изменять, а что нет, но бэкпроп так не умеет.
>>1154273 >Помимо него существует масса других, сильно отличающихся. Но их не используют, так что мимо. >не самый эффективный на практике Самый неэффективный скорее уж. >конкретной задачи, которой, повторяюсь, у меня нет В виду того, что тебе похуй на результат, предлагаю тебе обучать в 0 эпох сетку со случайной инициализацией. Будет выдавать ХЗ что, но так как у тебя нет задачи, то оно подойдёт. >>1154278 >не читал Тогда менять не будем >>1154282 >Рассматривай P (pre-trained в GPT) и backpropagation как что-то что тренирует нейросеть на создание "модели мира". То что у нас заложено в днк - нейросети создают через pre-trained на терабайтах текстов. Это не совсем верно в деталях, но в целом так. База. >>1155873 >Абстракции совпадают с реальностью Так абстракции твоего мозга нихуя с реальностью не совпадают. Ты банально никогда не видел сраного жёлтого света, а хочешь что-то там обучать. >Он хорош только для мелких моделек Ага, всего лишь 2Т.
>>1155873 > "Горький урок" прав в том, что если накинуть 100500 видеокарт на задачу, решение точно будет найдено... когда-нибудь - возможно, через тысячу лет бэкпропа. Не. Горький урок в том что решение не будет найдено никогда. Вообще никогда. Будет только приблизительное решение с разной степенью приближения. Такова природа нейросетей и нихуя ты с этим не сделаешь. По крайней мере на современных архитектурах. > сложился удачный генетический хардкод, изначально закладывающий чёткие абстракции; Не совсем так, скорее днк закладывает саму возможность абстракций и абстрактных объектов, мозг может с рождения воспринимать объект как что-то цельное, это в мозгу срабатывает как true нахуй. > Проблема в том, что люди слишком мало знают об устройстве мозга, Главная проблема в том, что люди хуй клали на создание новых архитектур. Бизнесу это нинужно, вся эта наука ебаная. В опенаи как ебали GPT, так и ебут до сих пор, похуям им на всё. > если нейронка правильно выдаёт следующий токен, то у неё 100% есть достаточно правильная абстракция над реальным миром Нехуя. Это абстракция над токенами в пространстве параметров. Так совпало что на какой-то выборке эта абстракция совпадает с реальным миром. > Лол. Во-первых, с чего взял, что текст обязательно необходим для восприятия и рисования картинок? В душе не ебу что там необходимо, мне поебать на картинки, это лишь наблюдение о работе GPT. > В мозге нет специальной магии с ярлыком "объект", Есть. Человек рождается с этой магией. > Он хорош только для мелких моделек Он хорош для всего. В GPT backpropagation используется. > Настолько точная модель мира, какая есть в GPT, Она принципиально не может быть точной, ибо такова структура нейросети. И это не модель мира, это просто некая модель в пространстве параметров, это можно назвать моделью мира, но это даже близко не то что есть у человека. > Очевидно, было бы лучше, если бы алгоритм для обучения автоматически определял, что требуется изменять, а что нет, но бэкпроп так не умеет. Нет никаких проблем для реализации всего этого через методы градиентного спуска. > Нужна рабочая (и быстрая) альтернатива бэкпропу. Ты не понимаешь работу нейросетей, не понимаешь что вообще происходит внутри и зачем вообще нужны эти алгоритмы. Изучи это для начала, потом фантазируй. Альтернатива градиентного спуска (если что это и есть backpropagation) нужна только потому что градиентный спуск вычислительно сложен.
>>1155948 >предлагаю тебе обучать в 0 эпох сетку со случайной инициализацией Знаю, топовая тема, нужно обязательно попробовать. https://en.wikipedia.org/wiki/Extreme_learning_machine >According to some researchers, these models are able to produce good generalization performance and learn thousands of times faster than networks trained using backpropagation. Но интересно понаблюдать за обучением... Всё-таки зафиксированные веса не будут адаптироваться под поступающие данные, не так ли? Результат не важен, интересен процесс адаптации к чему-то новому. Имхо, важно понимать, как твоя нейросеть адаптируется...
>никогда не видел сраного жёлтого света Что ты имеешь в виду? Философ что ли? Мы видим "жёлтый свет", потому что это логично. Нет смысла реагировать только на базовые сигналы (R/G/B), это разделение потребовало бы дополнительных затрат.
Ладно, допустим, мозг имеет "неправильную" модель реальности. Но если мы тренируем ИИ, чтобы он стал социальным агентом (робожена, рободомработница, робоповар и т.д.), то мы, очевидно, хотим, чтобы его внутренняя модель напоминала нашу собственную. Другими словами, ИИ должен повторять не только наружное проявление нашего поведения, но и то, что заставляет нас вести себя определённым образом. В противном случае не выйдет исправить все текущие проблемы (галлюцинации, alignment и так далее).
>всего лишь 2Т Попробуй файнтюнить этого монстра, чтобы он мог нормально ролеплеить эротику, которую полностью исключили из базового датасета. ИРЛ человек в это втянуться может за вечер, потребляя всего 100 Вт/ч, нейросетку будешь учить за сотни кВт/ч несколько месяцев, и результатом будет потеря её интеллекта. Алгоритм обучения мясного мозга пока лидирует.
>>1156187 >Будет только приблизительное решение с разной степенью приближения. Такова природа нейросетей Поэтому нейронки должны дообучаться в реальном времени на конечных устройствах (твоём смартфоне, робожене, автомобиле), т.е. адаптироваться к вечно меняющейся среде. Необучаемые животные в дикой природе полагаются на свою способность быстро и дёшево размножаться (бактерии, насекомые), т.е. основное преимущество нейронок в их способности динамически адаптироваться к текущим условиям (независимо от того, что было заложено в генах).
А для этого нужен другой алгоритм обучения.
>клали на создание новых архитектур Мне кажется, они просто не пиарятся так, как все эти мейнстримные LLM. А результат их работы не такой впечатляющий, как сексуально озабоченная вайфу...
>Так совпало что на какой-то выборке Из моего общения с LLM чатботами - это "совпадение" слишком часто и неожиданно встречается, чтобы его можно было списать на случайность. Даже если там целиком весь интернет наизусть заучен, некоторые понятия не могут просто так "совпадать на выборке".
>В GPT backpropagation используется. Предлагаю пофиксить Llama 4 на домашнем ПК. А то обосрались со своим GPU кластером, но ты-то точно правильно дообучишь на своих 4-х RTX 3090?
>Человек рождается с этой магией. >ибо такова структура нейросети. >даже близко не то что есть у человека. Ты понимаешь, что это утверждения из разряда: >У мясного мешка есть ДУУУШААААА, а какая душа может быть в куске железа? Там же нет МЯСА! Мясо вкусное, а железо вкусное? НЕТ! Значит, и души нет! Пацаны из Numenta ковыряют ИРЛ нейроны под микроскопом и даже закодили что-то рабочее на современном железе - поэтому к ним у меня есть определённое доверие, а какие у тебя аргументы?
>не понимаешь что вообще происходит внутри Вот поэтому я и хочу разобраться нормально.
Туториалы по нейросетям делятся на: >Уот так уот делаем простейший перцептрон... Всё, остальное слишком сложно, не все смогут понять. И доминирующее сегодня: >Делаете from krutaya import gopata, потом просто выполняете run("ваши данные") и нейронка готова! Где чёткое объяснение того, как нейронка (хотя бы единственный нейрон) находит верное решение? И главное, почему она его находит, а альтернативы не находят, т.е. почему именно нейронки нужно делать.
Все говорят "ну, это чёрный ящик" и всё тут. Раз это "чёрный ящик", значит, алгоритмы неправильные? Правильные алгоритмы не называют так. Кто-нибудь называл сортировку массива "чёрным ящиком"? Нет. Нейросетки же рассматривают как необъяснимое...
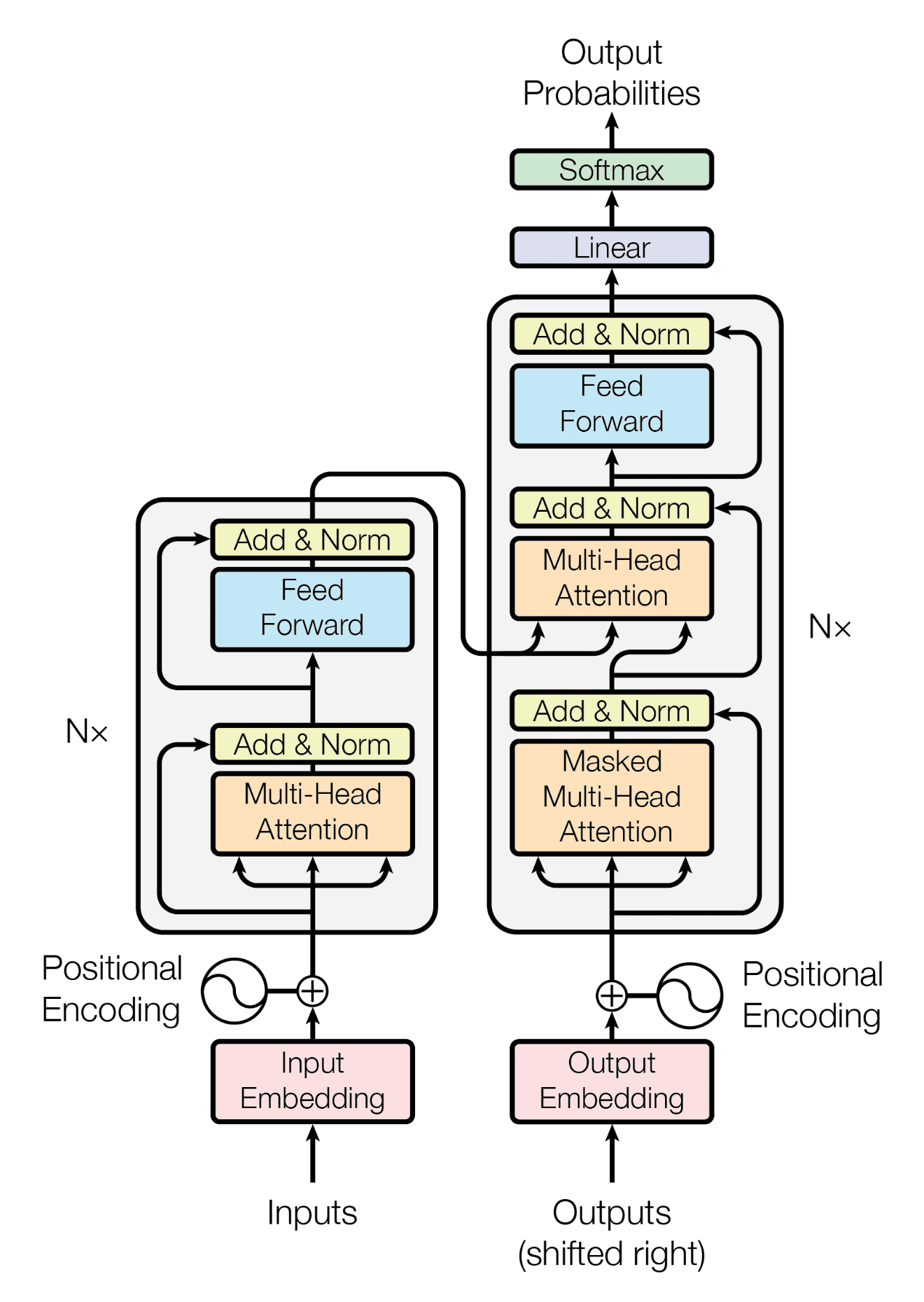
Вот я не понимаю нейронки, а ты? Можешь расписать подробно, как именно GPT на триллион параметров выбирает конкретный следующий токен? Не общую архитектуру трансформера, а логику, которой уже достаточно обученный трансформер следует внутри триллионов своих параметров, этого "чёрного ящика".
Потом можешь расписать, почему эта логика как-то отличается от логики, которой следуют обученные биологические нейроны в твоей голове. Ты, видно, рассматривал их в микроскоп, так что знаешь...
Алсо, мне непонятно, если чисто рандомные веса с обучением линейного выхода (ELM) способны решить большинство задач чуть-чуть хуже бэкпропа, но очень быстрее, то почему их не применяют на практике? Это наверняка было бы дико полезно для тех же чатботов. Представь себе файнтюн за секунды на древнем ПК, подкручивающий только несколько связей, ибо все остальные просто не нужно никак изменять... Такой прорыв был бы намного важнее бенчмарков на IQ.
Ну, т.е. даже с "неправильной моделью мира", которая обучается только на токенах, можно много чего очень интересного сделать, если просто ускорить обучение.
>>1157032 > А для этого нужен другой алгоритм обучения. Другой алгоритм должен быть подвязан на всё, включая размерности векторов, внутреннее представления, словарь и его размерности, параллельность. Иначе он не имеет никакого смысла. > Мне кажется, они просто не пиарятся так, как все эти мейнстримные LLM. Нет, они просто хуй клали, как и все остальные. Если ты не в курсе - почти все модели основаны на трансформерах. Там нет ничего нового кроме частностей, трансформерам 12 лет уже стукнет скоро. > Hierarchical_temporal_memory > the-thousand-brains-theory-of-intelligence/ Да, занятная хуйня c большим потанцевалом из-за параллельности. Слои можно сжать, но из-за распараллеливания добиваться результатов гораздо лучших. Но всё это говно нужно переработать с нуля, уверен что эти выблядки очередную хуйню делают. > Из моего общения с LLM чатботами - это "совпадение" слишком часто Что ты там себе представляешь всем поебать, я тебе говорю как это работает в реальности. > если кинуть побольше GPU в неё, то рано или поздно она станет правильной Модель не станет правильной если она изначально построена на архитектуре трансформеров. У тебя магическое мышление. > Предлагаю пофиксить Llama Нахуй мне трансформеры фиксить? Они говно. > Ты понимаешь, что это утверждения из разряда: >У мясного мешка есть ДУУУШААААА Это твой бред в башке, не мой. Подтверждено экспериментально - человек рождается с пониманием объектов и пространства, с моделью мира. На младенцах проверяли. > Пацаны из Numenta ковыряют ИРЛ нейроны под микроскопом и даже закодили что-то рабочее на современном железе - поэтому к ним у меня есть определённое доверие, а какие у тебя аргументы? Что ты высрал вообще? К чему это? Ты думай прежде чем писать эту хуйню. > Вот поэтому я и хочу разобраться нормально. Читай статейки научные, сиди с ручкой и пиши в тетрадочке конспекты, если в мозгу это не можешь удерживать. > Можешь расписать подробно, как именно GPT на триллион параметров выбирает конкретный следующий токен? Нейросеть строит вектор в многомерном пространстве, вектор будет указывать на следующий токен. Ты лучше не меня спрашивай, а иди статьи читай, твоё и моё понимание отличаются. > Потом можешь расписать, почему эта логика как-то отличается от логики, которой следуют обученные биологические нейроны в твоей голове. В нейронах есть множество векторов, плюс обработка сигнала на каждом нейроне, огромное количество связей, есть опорные вектора - нейромедиаторы. В GPT вектор лишь один и единственная функция обработки вектора. > Ты, видно, рассматривал их в микроскоп, так что знаешь... Да не трясись ты так. > Алсо, мне непонятно, если чисто рандомные веса с обучением линейного выхода (ELM) способны решить большинство задач чуть-чуть хуже бэкпропа Хуйню несешь полную. ELM не в состоянии решать какие-то сложные задачи, они проебывают в производительности кратно. Они просто говно. Но ускорение обучение необходимо, это беспезды.
> Hierarchical_temporal_memory > the-thousand-brains-theory Алсо, я примерно то же самое нахуячил у себя в голове, но исходил прежде всего из задач парализации. Это точно весьма перспективное направление если одному и тому же решению можно прийти с разных позиций. Впрочем, дальше я пока не зашёл, нужно решить задачу представления абстракций внутри сети.
>>1157032 >Философ что ли? Физик. >то мы, очевидно, хотим, чтобы его внутренняя модель напоминала нашу собственную Тогда и его уровень будет сравним с нашим. >>1157320 Ты забыл про отсутствие масштабирования, сиди учи 1000 макак, если нужно увеличить скорость в 1000 раз.
Есть кто в треде? Я вот мазохизмом решил позаниматься, разработать GPT с нуля на C++, обучение тоже с нуля написал.
Но что-то идёт не так, ошибка немного падает, модель тупо немного обучается и зацикливается на одном-двух словах, выходит выдача типа "the the the the..." или "пре но пре но пре...". Притом не важно, как токенизацию делаю - по символам или словам, результат одинаков.
Запилил Dropout, Label Smoothing, Weight Decay, напоследок ещё реализовал Entropy Penalty. Но в итоге толку ноль, проблема не решается, энтропия выдачи падает всегда, даже если немного повышаю параметры, чтобы это исправить, а если повышаю много - просто обучение начинает расходиться и ошибка вообще растёт (а энтропия при этом всё падает, лол).
Где я мог потенциально проебаться? Думал, может, в изначальной генерации параметров, но экспериментировал - тоже без толку, да и вроде стандартное mean=0, std=0.02 вполне подходит ведь.
>>1172306 Ладно, походу я ебланю просто, снизил learning rate, теперь оно наконец супер-медленно, но таки опускается, хотя блин, в примере, на который я изначально опирался, и на 1e-3 училось хорошо и быстро, а у меня только на 1e-4 вот оно начало малость (но всё ещё охренеть как недостаточно) адекватно себя вести.
Может, конечно, ещё датасет для тренировки говно, но у чела с ютуба на этом датасете нормально тренировалось.
>>1174474 Нет и нет, но сейчас, по сути дела, проблема решена, его тупо оказалось нужно супер-долго тренировать, чтобы он доходил до адекватных результатов.
Перепишу потом код, внеся всякие оптимизации и вычисления на видеокарте, чтобы быстрее куда всё было.
А делаю я это для того, чтобы глубоко разобраться в теме ИИ, а сразу хуйнуть практикой - самый быстрый способ разобраться
>>1172306 >Но что-то идёт не так, ошибка немного падает, модель тупо немного обучается и зацикливается на одном-двух словах, выходит выдача типа "the the the the..." или "пре но пре но пре...". Притом не важно, как токенизацию делаю - по символам или словам, результат одинаков. >>1175928 > его тупо оказалось нужно супер-долго тренировать, Да, это так. Нужен грокинг словить, когда модель выстраивает внутри себя "модель мира". Без этого нихуя у тебя не будет.
В этот грокинг будет работать при любых параметрах, это влияет примерно никак. Может скорость обучения может чуть-чуть уменьшиться или увеличиться, но в принципе похуй.
>>1172306 >Но что-то идёт не так, ошибка немного падает, модель тупо немного обучается и зацикливается А ещё это похоже что ты попал в некий локальный минимум и получился хуй. В теории твои параметры должны подбираться так, чтобы проскакивать эти локальные минимумы, подбираются они чуть ли не экспериментально, да и я не ебу что за параметры и формулы у тебя. Да и вообще GPT это кал, рекомендую экспериментировать дальше с чем-то более интересным.
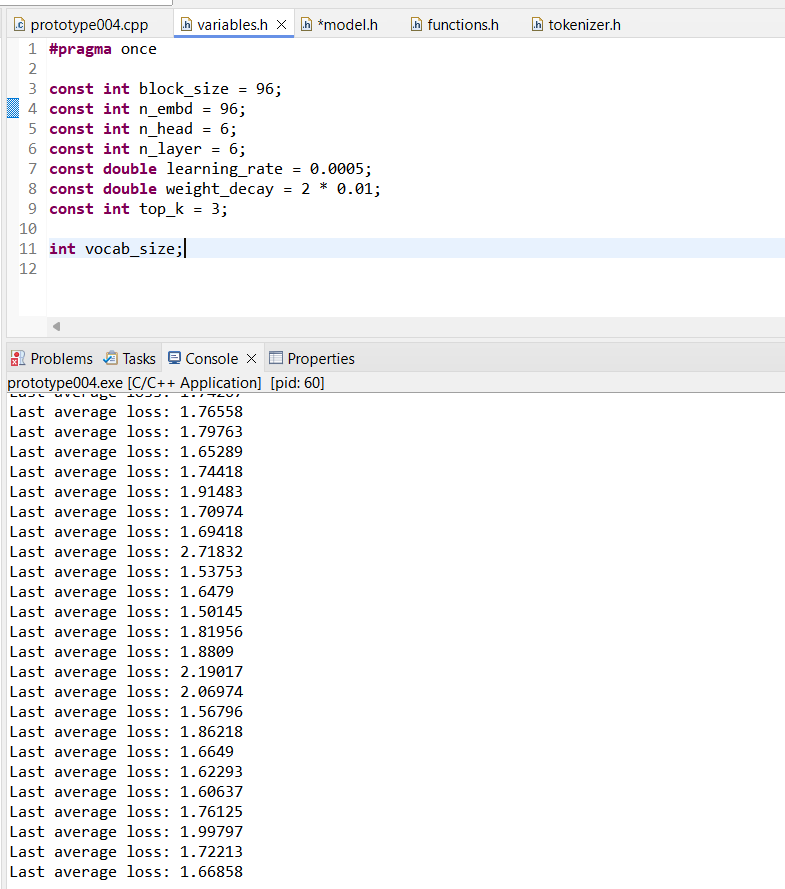
>>1182622 >>1182629 Да я уже разобрался с проблемой, я просто слепой еблан, короче, на градиентном спуске градиенты к параметрам нормализации и баясам суммировал, а не усреднял, плюс почему-то скорость обучения 0,001 оказалась херовой, а вот 0,0005 уже заебись. Плюс ещё код переписал на использование Eigen для линейной алгебры, стало сильно шустрее.
Прямо сейчас вот тренирую на вот таких параметрах, ошибка опустилась уже до того, что показывают обычно в учебных заданиях, а это значит, что я справился.
А про эксперименты ты верно говоришь, я буду экспериментировать, уже знаю, какую модель следующей напишу, нашёл кое-что интересное в исследованиях китайцев. Но ГПТ не зря писал тоже, для меня месяц-полтора назад вообще всё сложнее просто многослойного перцептрона было магией, а сейчас исследования читаю и всё свободно понимаю.