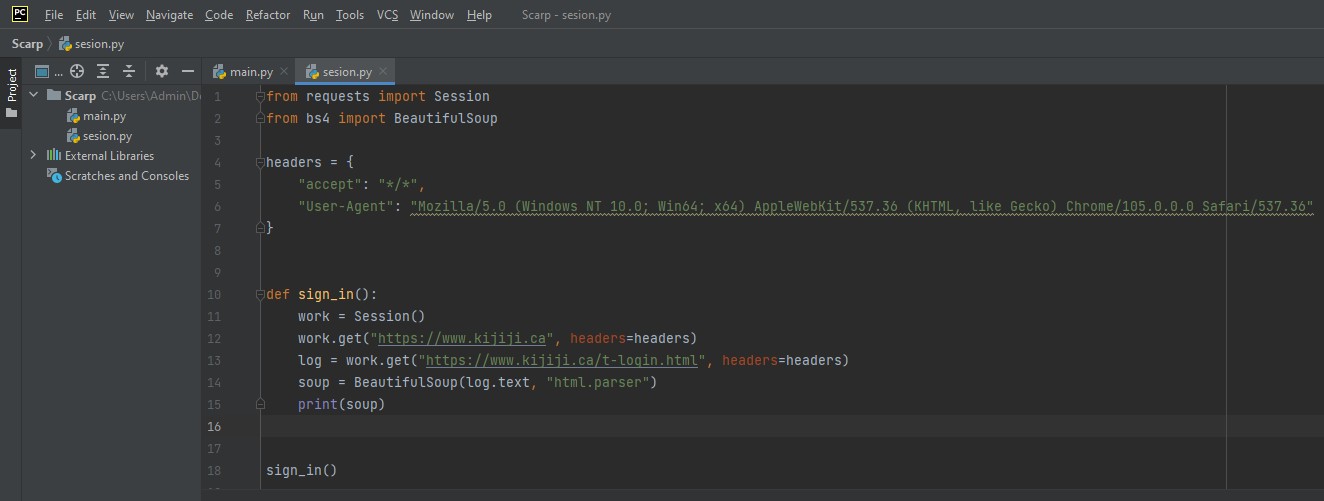
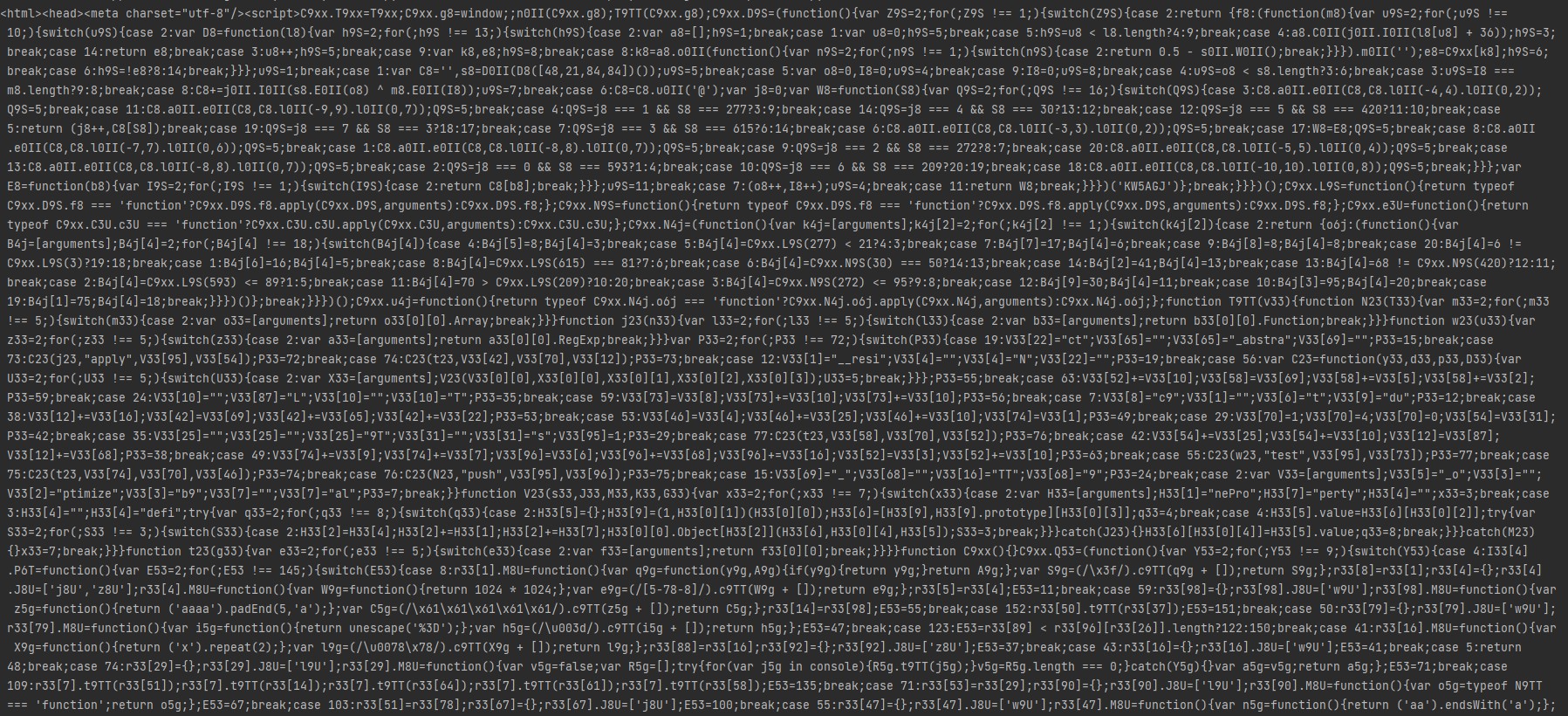
Решил научиться делать парсер, но столкнулся с такой проблемой как авторизация. На ютубе просмотрел кучу видео, но так и не нашёл решение для своей проблемы. Проблема в том что когда отправляю гет запрос, то приходит странный html код, хотя статус код 200. Когда пытаюсь найти любой тег, то суп его просто не видет или его нет. Пик 1 мой код и пик 2 html который я получаю. Хочу понять в чем проблема и как решить
>>136348 А как мне получить не js а html? На странице через инспектор кода вижу тег input, а когда применяю метод find() не находит ни тег input ни любой другой тег
>>136356 На клиенте авторизация должна как-то закрепиться, например записью в куке. Даже если авторизация выполняется каждый раз при первом входе на ресурс - что-то да появится на клиенте, вроде токена, который нужно приклеивать к дальнейшим запросам.
Что же касается респонса на втором пике - возможно там и js как server-side-render, но тогда в теле ответа будет json с нужными тебе данными. Крч, парсить будешь не api, не html, а json, что пришел вместе с хуйней со второго пика.
>>136337 (OP) Бля, если ты такие тупорылые вопросы задаешь, мол что мне делать с аутентификацией - то тебе beautiful soup противопоказан. Ты до него ещё не дорос. Возьми что попроще - puppeteer например или playwright. Или на худой конец селениум. Если ты не знаешь что такое csrf токен, то и нахуй ты лезешь в то, во что ты не понимаешь?
Оп, так как ты делаешь, в теории можно залогиниться, но это очень геморно Я пришел к библиотеке selenium, но сука на сайтах с хорошей защитой селениум как то палится и программа не работает
В связи с чем вопрос Мне нужно автоматизировать действия в браузере Какую технологию для этого изучить, чтобы она не палилась одним крупным сайтом? Ткните носом плс
>>136434 Или как скрыть действие хромдрайвера? Я юзаю selenium-stealth, но рабочей машине почему то не подменяется web-gl, я думаю из за этого сайт меня палит. Как вот подменить эту хуйню или более элегантно скрыть работу хромдрайвера? Понимаю что мне вряд ли ответят, но я не опускаю руки. Просто я даже не знаю, где спросить. Может анон подкажет какой нибудь форум или чат, где я смогу поинтересоваться мне очень интересно выполнить кое какую задачу, это в теории может принести бабки. я столько всего узнал за последние несколько недель в плане питона, селениума, фингерпринтов, вот этого всего. хотелось бы уже решить задачу залогина, как опу и писать программу дальше. дальше уже и обезьяна справится
>>136435 забей на селениум. юзай дефолтную либу запросов, парсить изи можно через регулярки \ хпат \ жсон (зависит от содержания ответа) . Если тебя на запросах палит сайт, то дело в составлении самих запросов \ проксях
>>136436 Мне нужно именно логиниться, нажимать на кнопки, короче мне нужно именно вводить данные, а не парсить. Автоматизировать надо другими словами Разве можно с помощью реквестов это сделать?
>>136437 Конечно можно. Ты вообще понимаешь суть реквестов? Это отдельный протокол, в том же браузере ты аналогично делаешь кучу запросов при совершении любых действий на сайте. Создаешь сессию, чтоб куки сохранялись и делаешь логин, далее уже парси, что хочешь
>>136439 Дело в том, что реквестами надо отправлять всю форму, а это не просто логин и пароль, но и всякие токены, js скрипты, не понятно откуда это всё берется и как это подставлять в запрос Мне нужно просто взять логин и пароль, вставить их в поле формы и нажать кнопку input
>>136440 Все там просто отправляется. Установи софт для снифа запросов, вроде барпа или фидлера. Настрой его и отснифай все что нужно. Потом, если в запросе на логин есть разные токены, то поищи их в других запросах. Как заполняется форма - чекай доки либы реквестов, там все изи, 3 типа контент тайпа
>>136443 Популярная, т.к. это прямая эмуляция браузера. Обывателю проще по кнопкам с координатами тыкать, чем разбираться в работе хттп протокола (запросах)
>>136444 Дело не в чеке конкретной либы. Ты при работе с селениумом - тоже делаешь запросы, как и при посещении любого сайта через браузер или мобильной прилы. На запросах ты можешь регнуть акк на сайте, условно, за пару секунд и потратишь на это пару кб на прокси. На вебе ты буш регать акк секунд, допустим, 30 и потратишь мб 10 от прокси трафика. Все защиты обходятся.
Понятно Просто не хотелось бы потратить месяц на изучение реквеста, а его по итогу так же задетектит сайт На самом деле изучать там очень много, особенно мне не понятна тема с токенами при логине
>Все защиты обходятся Просто селен реально проще и если есть варик обойти защиту под селениум, то я бы с удовольствием обошел под селениумом Мб ты знаешь куда копать? а если нет, то придется учить реквест, ниче не остается
>>136447 Не, не работал ни разу с селениумом. Онли запросы. Если тебя интересует автоматизация сайтов/ прил, то это нужно учить запросы. Да и учатся они точно не за месяц, гораздо быстрее. Короче, не трать время на селениум и подобные веб костыли, на запросах ты получишь скорость и точность.
>>136447 >На самом деле изучать там очень много Чел, если ты не занимаешься разработкой в постоянку, а хочешь только спарсить какой-то сайт, то у меня для тебя плохие новости - ты угробишь 9000 своего времени на это всё с минимальным выхлопом. Заебёшься сам, заебешь анонов вопросами, заебёшь сайт своим детским парсингом. Найди себе уже разраба и работайте с ним над этой проблемой. Если нет денег на разраба, то не еби мозги и найди себе нормальную работу - в инете без денег мало что можно.
>>136441 >вроде барпа Блять, этот сайт понимает что я его снифаю и просто не грузится Я ебал блять Я не знаю уже че делать Проблемы просто реально на каждом шагу
>>136337 (OP) Попробуй скопируй из браузера заголовки, ресурс не только по user-agent может определять действительно ли ты с браузера. Плюс, для питона, я уверен на %146, уже есть готовые либы, которые помогают маскировать запросы под юзера, обмазывая нужными заголовками. Плюс, контент твоего сайта можешь грузиться через js, в таком случае ты его не увидишь через обычный get запрос.
Судя по мусору в названиях классов в коде, этот сайт на реакте или ему подобном петушином JS-фреймворке сделан. Соответственно гет-запросом ты вытягиваешь JS, которым вся эта петушатня отрисовывается в браузере.
Посмотри есть ли он в кеше гугла. Если есть - значит используется пререндер и поисковым ботам отдается готовая статичная страница. В таком случае можно попробовать сменить юзер-агент на гуглбота и попробовать парсить статику.
>>136790 Судя по тому какую ты хуйню щас написал, от разработки ты далек, но пытаешься определять какие технологии петушиные а какие, что выдает недалёкого человека в принципе. Обфусцированный реакт палится легко, а тут типичная дрисня из jquery+bootstrap из нулевых.
>>136791 /static/ и мусор в названиях классов ни на что не намекает? То, что сюда еще и бутстрап подключили не отменяет того, что работает все на каком-то новомодном JS-фреймворке для петушониксов.
>>136433 вроде там можно настроить, чтобы когда отправляешь запрос там не было инфы про то что запрос из селениума, а заменить на какой нибудь фаерфокс и версию указать, это можно легко найти у всех браузеров есть свои версии и они как то по особенному написаны, честно несколько лет уже не занимался этим и всё позабыл, хотя в своё время парсил/скрэпил очень много сайтов в том числе booking.com, запомнился потому что дрочево лютое было и заказчик сам не знал чего хотел, но были и другие сайты абсолюнто разные с разными защитами, обычно если защиты меньше то парсер пишется быстро и собирает инфу быстро, а если там какая то защита то всё становилось дольше, по моему селениум я использовал в крайних случаях, по сути он как бы открывает окно браузера и выполняет команды из кода, так ведь? а то забыл уже все названия, но вроде эта штука называлась селениум, грубо говоря браузер работающий из кода Кстати там вроде есть возможность убрать так сказать графическую часть браузера, чтобы он выполнял свою функцию но на экране не отображался грубо говоря
так что бро там можно настроить тип браузера который запрашивает страницу сайта, поищи инфу