Литература: - Томас Кайт. Oracle для профессионалов - https://postgrespro.ru/education/books/dbtech - Алан Бьюли. Изучаем SQL. - про MySQL - К. Дж. Дейт. Введение в системы баз данных - Database Systems: Design, Implementation, & Management (Carlos Coronel, Steven Morris)
Q: Вопросы с лабами и задачками A: Задавай, ответят, но могут и обоссать.
Q: Помогите с :ORM_нейм для :язык_нейм A: Лучше спроси в тредах по конкретным языкам.
Q: Где хранить файлы? A: Не в БД. Для этого есть объектные хранилища, такие как Amazon S3 и Ceph.
Здесь мы: - Разбираемся, почему PostgreSQL - не Oracle - Пытаемся понять, зачем нужен Тырпрайс, если есть бесплатный опенсурс - Обсуждаем, какие новые тенденции хранения данных появляются в современном цифровом обеществе - Решаем всем тредом лабы для заплутавших студентов и задачки с sql-ex для тех, у кого завтра ПЕРВОЕ собеседование - Анализируем, как работает поиск вконтакте - И просто хорошо проводим время, обсирая чужой код, не раскрывая, как писать правильно.
>>3272255 У этого треда активность как у любого другого на этой доске - околонулевая. Даже если человек задает вопрос, этот вопрос может висеть день и больше. Зато соседний тред, в котором айтишники могут повнимаеблядствовать, +- живой.
Куда можно вкатиться с уверенным знанием MS SQL (1.5 года работы+), посредственным знанием питона (простенькие парсеры, работал с апи немного) ,и павер би(пара отчетов буквально было на PBI) . Думал в аналитику уйти, но там хуй поймешь требования, везде разные стэк требуют.
>>3278138 Ну ты вообще. SQL - это Structured Query Language. Есть в природе база в которой не используется язык запросов и у запросов нет никакой структуры?
Вот тебе и вывод: иметь язык запросов с понятной структурой лучше чем не иметь.
>>3278138 >поясните для тупых Это личное мнение какого-то петуха. Всё зависит от конкретного сценария использования. Есть сценарии когда лучше взять SQL и есть сценарии когда NoSQL лучше. Надо разбирать по каждому отдельному примеру. У меня есть и такие проекты и сякие. В том числе и NoSQL-проекты. И никто не умер от этого. Ничего такого сверхкритического нет. Ну да, в чём-то удобнее, а в чём-то неудобнее. В чём-то лучше, а в чём-то хуже. Где-то быстрее, а где-то медленнее. Можно до бесконечности обсасывать "ааааа, а вот у вас запись на 10% медленнее!" Есть случаи, когда одновременно и NoSQL и SQL в одном проекте используется, один для аналитики, а вторая БД для скорости. Такое тоже бывает.
>>3278315 >Есть случаи, когда одновременно и NoSQL и SQL в одном проекте используется Это когда основная БД нормальная реляционка но тимлид пропихнул в проект монгу для одного сервиса чтобы у себя в резюме потом написать NoSQL, MongoDB
Замечаю в последнее время большой хайп по локальным решениям для "не-распределенной обработки данных с высоким перформансом". Polars, Dask, Ray, DuckDB, и т.д. Кто-нибудь может объяснить мне, какие задачи у этой ебалы? В моей голове, если хочется поиграться локально с данными (будь то для локальной разработки, или же если ты аналитик и у тебя адхок задача) - есть Pandas для питонистов, есть SQLite для сиквела. Если же надо большие данные - есть жирные реляционные БД, есть всякие распределенные решения на мапредюсе, всё это можно захостить в облаке или онпрем. А вот этот класс инструментов - нафига он? У меня есть ощущение что это вышло из DS, где люди так или иначе работают на жирных ноутах и модельки локально обучают, но ХЗ, я не машобщик.
>>3278380 А чего ты порвался? У того, как ты выразился "петуха", хотя бы мнение какое-то было. А хули проку с твоего абзаца воды? Пук среньк, так-то да, а так-то нет.
Дженерик переливание из пустого в порожнее, один в один как жпт кал. Когда надо что-то высрать, но ничего конкретного ты не знаешь. Только жпт так запрограммирована чтобы всегда высирать ответ, а ты нахуя тут насрал?
>>3278450 Да не хочу я в ваших тупорылых спорах участвовать. Рассказывать по делу это с пеной у рта доказывать, что nosql пиздец хуже чем sql и вообще nosql нигде не применяется? Да иди ты нахуй и все кто доказывают эту хуйню - идите нахуй. Есть примеры когда nosql + sql используются одновременно, есть даже такой паттерн, называется CQRS:
>>3278370 Не обязательно так. У нас сейчас на проде одного довольно ебучего легаси продукта MySQL и Монга. Изначально был только мускуль, но продукт очень быстро разросся и требовал HA, так что мускуль заскейлить под эти требования не получалось. В итоге конфиги остались в мускуле, а основные OLTP в монге. Это в принципе неплохо работает.
>>3278474 Опять какая-то вода, бессмысленный мусор. Право на существование блядь какое-то, филосов стекломойный.
Если человек спрашивает что выбрать, то выбирать ему нужно реляционную базу. Без вариантов. Потому что данные будут в целости, сохранности и в нормальном виде. И перейти с реляционной базы на любую другую - легко. А вот обратно - хуй.
А рассказывать про какие-то охуительные исключения можно до бесконечности, только практической пользы от таких рассказов нихуя нет.
>>3278495 >Если человек спрашивает что выбрать Выбирается в зависимости от задачи. Взвешиваются все плюсы и минусы. У меня есть проекты на nosql, там где сложные запросы не требуются. Никто не жаловался. И есть проекты на постгре. Если ты не можешь сделать на nosql - проблема в тебе и в кривых руках растущих из жопы.
>>3278501 Согласен, все по факту. Выбирается постгрес потому что он способен решить большинство задач, и для него достатоно иметь немного кривые руки растущие из жопы. Он не даст сделать полной хуйни и обойдет за тебя большинство подводных камней.
Постгрес - вариант беспроигрышный. Пишешь в постгрес по умолчанию, а потом уже взвешиваешь плюсы и хуюсы и решаешь что делать дальше. Спойлер: в 99% случаев нихуя делать и не надо.
>>3278501 >где сложные запросы не требуются Сперва не требуются, а потом внезапно хуяк и потребовались. Стартап выстрелил, так иногда бывает. И начинаются анальные пляски с кучей баз каждая в своем микросервисе, по сети летают данные там, где хватило бы обычного запроса на десяток джоинов. В какой-то момент происходит пиздос, данные разъезжаются и вместо холодильника с маркетплейся приезжает коробка дилдаков. Зато не sql.
>>3278512 Когда стартап выстреливает - пока мвп лениво крутится в проде набирается команда и переписывается всё чуть ли не с нуля, но по уму. На стадии мвп и поиска инвесторов очень многое, как в коде, так и в инфре нахер не нужно и не делается.
И сделать выгрузку из одной базы для переноса в другую - обычная задача, сто раз уже пройденная многими тысячами разрабов с написанием гигабайтов гайдов.
>>3278531 Твои бы слова да в авито. Команду так просто не соберешь, если ты не гугл. Главкабан не понимает, почему надо просрать кучу бабла и получить точно такой же продукт. Чтобы что? Продукт уже есть, надо набрасывать новые фичи с лопаты.
>>3278512 Ой бля хорош нудеть нахуй. Ты как бабка авдрухчо. Зачем писать а вот если то произойдёт, то чё тогда? Ну произойдёт и произойдёт. Что-нибудь придумаю, поставлю вторую бд или дата лейк замучу, или будет какая-нибудь pre-aggregate функция. Ситуаций из которых прям никак не выкрутиться почти не бывает. Нуууу блять всё можно грамотно обыграть, это не конец света.
(PostgreSQL) Есть сущность с 16 байт ключом и двумя десятками опциональных атрибутов, из которых треть - text. Большинство запросов - чтение всех атрибутов, и обновление одного-двух атрибутов. Записей - десятки миллионов. Стоит выбор между одной широкой таблицей с NULL колонками, и двумя десятками таблиц, по одной на каждый опциональный атрибут. Что стоит выбрать и почему? Есть ли преимущество у таблиц с исключительно фиксированной длиной всех колонок?
Я джун с 0 опытом работы. Умею выполнять простые-средние SQL-запросы. Мне нужно составить знание что я должен делать, куда смотреть, что вводить, какими критериями руководствоваться, какими инструментами пользоваться, чтобы научиться анализировать и оптимизировать работу с mysql. Книги, материалы, темы может кто-нибудь подсказать для этой ситуации?
Сап, аноны Решил тут sql академию пройти и залип на задачке с insert Добавьте новый товар в таблицу Goods с именем «Table» и типом «equipment». В качестве первичного ключа (good_id) укажите количество записей в таблице + 1. 3й аргумент можно просто указать, но хочется его получить, а я не пойму как.
Написал решение: insert into goods (good_id, good_name, type) values( count(good_id) + 1, 'Table', (ifnull( select max(good_type_id) from GoodTypes where good_type_name = 'equipment' group by good_type_id, 0)))
Думал через селект выдернуть можно, не получилось, попробовал через ифналл, но и он не сработал. Что можно применить?
>>3295938 >натуральный ключ Ты совсем ебанулся? Что за шизофазию ты несешь? Какой он нахуй натуральный если вычисляется на лету, да еще и зависит от состояния ВСЕЙ таблицы, которое меняется постоянно?
Вот удалить запись с айди, например, три. И кто тут теперь вполне натуральный, кто тут блядь порядковый? Кто пятый? Кто десятый? А новый порядковый номер какой будет? Такой же как предыдущий? И это я не говорю про вставку записей. Там же блядь гонка будет перманентная. Каждый долбоеб пересчитывает записи, а пока он считал там новые добавились.
Даже не знаю с кого я больше охуеваю. С клоунов-академиков или с клоунов-двачеров.
>>3297145 По описанию логической модели данных напиши создай (напиши в DML) таблицы в 6NF, затем 5NF вьюшки для "основных" таблиц, и пару-тройку процедур для ввода данных. Создай индусы для процедур. Если осталось время, то опиши роли и права для администратора, пользователя, и приложения.
>>3297279 >таблицы в 6NF Зачем это? Выше 3нф редко бывает нужно на практике, а чаще всего одну жирную таблицу вообще дробят на много маленьких и хранят жсоны в базе, потому что так быстрее работает и ниибёт.
>>3297514 >Выше 3нф редко бывает нужно на практике Потому что на практике большинство таблиц в 3NF на самом деле удовлетворяют 5NF или 6NF. >одну жирную таблицу вообще дробят на много маленьких и хранят жсоны в базе, потому что так быстрее работает и ниибёт. Что работает быстрее?
>>3297279 спасибо анон, но звуит душновато. Хотя тот же 6NF довольно часто используется, но я б не стал так вопрос формулировать.
Я обычно спрашиваю, как работает жоин на физическом уровне, чем отличается кластерный индекс от не кластерного. Рисовать таблички не заставляю, могу спросить про CDC/SCD.
>>3297691 Зачем? У промышленных субд внутри происходит ебаная магия с патентованными алгоритмами. Алсо сама концепция декларативного sql говорит, что тебе должно быть похуй на реализацию. Вопрос из серии "к чему бы еще доебаться". Туда же вопросы про кластерный-некластерный индекс. Все индексы некластерные, блять, а кластерный только один по id, нахуя уделять ему столько внимания?
Вот есть древовидная структура у меня в базе Ко мне приходит последовательность зависимости от корня к листу. Как проверить что эта последовательность есть в бд? Не понимаю как использовать тут рекурсивный запрос
>>3298381 >>3298400 А тебе не приходилов голову просто сделать запрос WHERE parent_id IN(твоя последовательность)? Зачем тебе вообще здесь рекурсия? Рекурсия нужна чтобы ПОСТРОИТЬ дерево, а утебя дерево на вход подается, нужно только убедиться что ноды из этого дерева в базе есть.
>>3298778 Я вижу два стула. 1. Рекурсивно построить полные пути от ребенка до самого далекого родителя, потом поискать среди полных путей исходный. 2. Разбить исходный путь на пары (родитель,потомок) и сделать джоин с таблицей связей в бд. По идее, второй будет работать быстрее.
>>3298778 Ну ты тугой канеш. Представь что твоя последовательность будет состоять всего из одной ноды. Вот надо тебе найти есть ли в таблице "дед". Как ты будешь эту ноду искать? Дерево будешь рекурсивно строить? Ясен хуй нет.
Ну так твой поиск нескольких нод прекрасно сводится к поиску каждой из этих нод по отдельности. Нам нужно найти что в таблице есть "дед", и в таблице есть "папка", и в таблице есть "внучек". Зачем для этого какие-то рекурсии и деревья?
>>3300601 > Можно жсонами всё хранить на норм ссд, изи. Это тоже база данных. В определении понятия "база данных" нет ни слова о том, что это должна быть клиент-серверная многопользовательская поебота с таблицами, форенкеями, индексами, транзакциями и журналами. > Юзать МуСКУФ в 2к24 - это кринге, чел. Согласен.
>>3300625 Ну, если так определить БД, то тогда да, очевидно никак без БД. Я имел в виду, что в 95% случаев хватит базы данных работающей как бекап оперативной памяти, т.е. очень очень простой.
Так размер этого дерева может быть разным, динамически формировать запрос предлагаете? Или покажите пожалуйста пример, если не сложно У себя я реализовал через возврат путей и поиск нужного
>>3304397 >динамически формировать запрос предлагаете? А можно как-то по другому запрос формировать? Дерево твое как в этот запрос попадает? Статитески что-ли?
Последний раз объясняю. У тебя есть последовательность: 1 <- 22 <- 45 <- 75. Эту последовательность можно представить в виде пар (id, parent_id): (1, 0), (22, 1), (45, 22), (75, 45). Нужно просто проверить что в таблице есть все эти записи. Есть записи - есть последовательность, если какой-то не хватает, то и последовательности нет.
>>3301783 >95% случаев хватит базы данных работающей как бекап оперативной памяти, т.е. очень очень простой Согласен, у нас редис на 200 ГБ и пара петабайт S3. Мы тексты обрабатываем
>>3309162 Big data уже давно стало скверным баззвордом... Указывай конкретные технологии. К слову, в данных ты также можешь админить, только это называется DevOps. Будешь хорошо устроен если разберёшься с K8S и изучишь какой-нибудь Go. Ну или разрабом - учи SQL, Java/Python/Scala, Spark, Kafka, Flink, Airflow, ... В принципе это всё - старый-добрый SQL, только одетый в модные шмотки.
>>3268780 (OP) Объясните мне пожалуйста почему у mysql такая конченая реализация репликации по дефолту? Как будто я блять в какие-то 90-е вернулся. Реплика мастер-мастер, было пару случаев когда ебанули внезапно електрику и когда внезапно ебанул у сервера второе питание. Суть следующая - у этой хуиты слетает каретка sql потока, причем по логам бывает уебывает куда-то за пределы файла. В реальности оно наебнулось на какой-то одной операции, но ты хуй найдешь на какой потому что файл полубинарный. Почему не сделать функцию рекавери слейва с мастера и его локом? Почему не сделать операции построчно в файле и писать вместо позиции каретки в файле как ебланы - номер строки случилась хуйня чтобы эту хуиту можно было дебажить, т.е. сделать операцию и скипнуть ошибку? Я уже молчу что можно было сделать в теории полное автовосстановление по парным/непарным индексам. В мире есть какие-то способы/аддоны как совладать с этой хуйней?
PostgreSQL Есть таблица datetime-цена. Хочу в результате запроса получить в одной строке цену за определённое время пятницы и за определённое время следующего понедельника. Делаю with (Номер недели, цена за требуемое время пятницы), (Номер недели минус один, цена за требуемое время понедельника) select join on номер_недели=номер_недели
Это нормальный способ, или уебанский и есть что-то проще?
Вкатился на джуна аналитиком dwh Возник вопрос. Есть ли какая-то позиция в сфере работы с БД где необходимо просчитывать что-то математически? Используя дискретную математику, реляционную алгебру и прочие разделы математики. Подскажите плиз, если слышали о таком или знаете как двигаться в этом направлении.
>>3321319 Надо план смотреть. Сходу кажется, что ты 2 раза будешь читать таблицу, сначала выбирая пятницу, а потом - понедельник. И потом делаешь join. Возможно, можно сначала сделать фильтр на пятницу и понедельник, чтобы база в один проход выбрала эти данные, а потом с ними работать. Тут можно сделать join, а можно и оконку попробовать прикрутить.
>>3321459 >работы с БД где необходимо просчитывать что-то математически Data science? Там, правда, работы с самой СУБД практически нет, часто данные могут быть в виде файлов, например. Ну и анализ ты будешь делать при помощи библиотек на Python в Jupyter notebook. Возможно, продвинутые аналитики тоже считают что-то математически, не знаю.
>>3321488 Знакомый работает синьором в банке тоже аналитиком. Говорит нужны джуны, работа пизда скучная, но перспективная Написал список тем типа sql, dwh, greenplum, python, что нужно знать За месяц прочитал в инете про все это Взяли туда джуном после скрининга и тех. собеса
>>3321519 Не, я имею ввиду всё-таки использование в БД Я хотел в ds попасть, но я великовозрастный вкатун, которого даже не рассматривают Имел в виду про математическое моделирование БД, оптимизации этих моделей (про подобное краем уха слышал)
>>3321524 Не знаю, о чём ты. Речь про построение модели данных? Звезда, 3NF, Data vault. Этим занимаются архитекторы, по крайней мере выделением общих принципов. Аналитик обычно может разве что разложить бизнес сущности по этим принципам - например, абонент это сущность, а регион это SCD и так далее. Ну и в целом там какой-то сложной математики нет.
>>3321459 >где необходимо просчитывать что-то математически? ...в пайплайнах? Ну очевидно же! У тебя есть некоторый набор данных - логи, xml, pdf, что угодно. Они же блять не сами по себе загрузятся в базу данных? Вначале их надо обработать и что тебе мешает во время обработки добавить своих магических супер-пупер алгоритмов? А потом они уже уйдут в бд, delta lake, отчёты или куда-то ещё дальше.
>>3322213 >хранить изображения в бинарном поле в mssql? А нахера хранить их в базе данных? Какой в этом смысл? Ты конечно можешь хоть всё собрание сочинений Дюма залить туда. Но я исхожу из практических соображений. База данных она же блять ресурсы потребляет. И не абы какие. Все эти индексы, хранение, и прочее это всё стоит денег. Ты же не будешь под бд брать хостинг с hdd? Хороший топовый диск стоит невъебенных денег, около 3 тысяч баксов в месяц за 80K IOPS диск 512 гигабайт. Ну и плюс, это всё надо масштабировать, реплицировать, и так далее. А как быть если из-за твоих картинок запросы медленнее работают? Ну короче, что там такого супер важного, что эти картинки нельзя поместить в какое-нибудь объектное хранилище или обычный hdd-диск?
>>3322213 Никаких подводных. Выносишь картинки в отдельную таблицу Pictures(id,data), делаешь для нее партиционирование на отдельный диск, получаешь консистентность из коробки. С файловой системой ты рано или поздно проебешь бекапы и получишь ситуацию с ссылками на файлы, которых нет.
>>3322222 >А как быть если из-за твоих картинок запросы медленнее работают? Перестать быть дебилом с орм головного мозга. Почитать, как работает бд и почему select * from table - это плохая идея.
>>3322244 Я не он, но не понял. Если для картинок отдельная таблица, то оно не должно напрямую влиять на запросы бизнес-логики и прочего. Если там оно всё в одной таблице, то будет влиять, если только БД не колоночная, которая умеет читать только нужные поля.
>>3322244 Это ответ на другой вопрос. А я спрашиваю ЗАЧЕМ В ПРИНЦИПЕ хранить картинки в бд. Не технический вопрос "сработает ли", а зачем? Хуй с ним, ладно. Пускай ты прав, всё масштабируется, работает, запрашивается. Ииииииии? Что мне мешает не ебать мозги, а хранить только ссылки. За тот вес, который занимает одна картинка я могу... даже не знаю... записать 500 текстовых записей?
>>3322278 Окей. И ради какого-то маааааааленького плюсика, ради отсутствия потенциально битых ссылок можно пожертвовать всем остальным: большую бд сложнее обслуживать, головняк при переезде на другую бд, плюс как ты собираешься раздавать эти файлы из базы данных? Открывать поток на стрим что ли? Если бы это была такая охуенная идея, пол-интернета давно бы хранило в бд. Но почему-то вместо этого выбирают cdn.
>>3322288 А, я мимо проходил, ОП идеи не я. На тему best practice - аргумент так себе, люди в индустрии просто копируют чужие подходы в основном и всё. Тема провокационная. С одной стороны - зачем использовать СУБД? С другой стороны - почему бы не использовать. Реальный ответ тут только в стоимости ресурсов. Железо под шуструю OLTP будет дороже, чем под хранилку картинок, которая может быть медленнее. Но, опять же, думаю, есть варианты настроить хранение изображений на отдельном железе, нужен только толковый админ.
>>3322288 Ты задачу уточни. Тебе нужен цдн с раздачей охулионы терабайтов в секунду? Или нужна консистентность, чтобы важный пдфник с договором не проебали? АСИД - это не маленький плюсих, это охуительный плюсище.
>>3322318 Суть в том, что можно разные таблицы хранить на разных дисках, блобы - на медленном хдд, индексы - на быстром дорогом ссд. Все происходит внутри субд, для тебя это обычный инсерт/апдейт, только с блекджеком и транзакциями. Для хранения пдфников в базе отличная штука.
>>3322299 >зачем использовать СУБД? Действительно. Зачем использовать СУБД, если есть дата лейки для этого. Ну хочешь ты хранить картинки, пдфки - нахуй тебе СУБД? Возьми delta lake, там будет такой же acid. Прогоняешь по пайплайну и делаешь чё хочешь - хочешь нейронки обучаешь, хочешь анализ делаешь. СУБД изначально рассчитана на структурированные данные, там не предполагается, что ты начнёшь пихать емейлы или ещё какое неструктурированное говно в базу.
>>3322307 >важный пдфник с договором не проебали? Смотри выше. Hudi/Iceberg/Delta Lake у них у всех есть acid. К тому же, для договоров имеет смысл использовать блокчейн на базе hyperledger fabric вместо стандартной бд. Я могу привести с десяток примеров таких стартапов: DriveChain, Euroclear, страховая компания Allianz, банк Норвегии и так далее.
>>3322385 Да, сейчас бы вместо одной СУБД развернуть lakehouse на кластере кубера с каким-нибудь S3 или Хадупом, сверху Айсберг, обмазать блокчейном и нейронками. Мы поняли, что ты следишь за баззвордами.
>>3322413 >Мы поняли, что ты следишь за баззвордами. Окей, иди нахуй тогда. Тебе предложили самый простой вариант - постить ссылку, ты недоволен.
ХОЧУ ХРАНИТЬ ФАЙЛЫ В СУБД @ НУ ПОСТЬ ССЫЛКУ @ А ВДРУГ ССЫЛКА БИТАЯ, МНЕ ACID НУЖЕН @ НУ ДАТА ЛЕЙК ТОГДА @ НЕТ ФАЙЛЫ ВАЖНЫЕ @ НУ БЛОКЧЕЙН ТОГДА @ МНЕ НЕ НРАВЯТСЯ ТВОИ БАЗЗВОРДЫ, МНОГО МОДНЫХ СЛОВ ГОВОРИШЬ
1 год работал в отчётности в коллекторском агентстве - MS SQL. 1.5 года работал в DWH в банке риски - Oracle DB/MySQL. 1 год работал в разработчиком в кредитном конвейере в банке - Oracle DB. 2 года работал разработчиком в международном DWH - Oracle DB. 2.5 года уже работаю старшим инженером в банке - Greenplum/Postgresql.
Выгорел просто пиздец, ничего не хочется. Последнее время с петухоном работаю, это радует. Но хочется уйти в какой нибудь Golang. Что посоветуете?
Нихуя вы тут срач развели из-за меня неофита. У меня пара вопросов: 1) Как файл должен проебаться в файловой системе и не проебаться в бд. Если на диске наебнется сектор, то файл наебнеться внезависимости от того как он храниться? Или в бд (например mssql) есть какой-то механизм рекавери? 2) Что по производительности в двух случаях? Насколько я понимаю что файловая система будет быстрее. У меня условная задача может на (всего-то) пару тысяч картинок которые желательно таки не проебывать как и в принципе любой файл.
>>3322891 Меня как раз заебывают аналитики. Мы пилим один из слоев данных и мне приходится из sql-говнокода аналитиков делать пайплайны. Очень рутинные и слабоавтоматизированные приседания.
Часть с airflow 2 как раз самая интересная в работе. И много где катируется, полезный опыт. Даги руками не пишем, кстате, автоматически сделали раскатку из dbt-проекта.
>>3322873 Когда ты хранишь данные в нескольких местах, перед тобой встает проблема консистентности. Пока ты в одной бд, этим занимается сама бд, ты себе мозги не ебешь. Иначе тебе придется заморочиться с распределенными транзакциями, это много лишней работы из ничего. Ты сохраняешь файл на файловый сервер и ссылку в бд, файловый сервер возвращает ошибку таймаут, твои действия? Запись есть в бд, а на фс файла нет, как ты будешь синхронизировать информацию?
>>3322927 Над БД у тебя есть приложение, верно? Приложение пусть проверяет наличие файла. Если отсутствует отсыпает пользователю ошибку и удаляет саму строчку в БД. Либо повесь на переодический процесс. Чтобы синхронизировать файлы и строки в базе. Обычно это не является проблемой.
>>3322945 Вооот. Уже появился демон, который надо написать и отладить. А потом к нему написать ямл и тоже отладить. А потом написать метрики, ты понел. На ровном месте система усложняется просто потому что.
>>3322927 У меня прямо сейчас уже такая хуита - таблица с пикчами это уже по сути сорт оф справочник, то есть в другой таблице хранятся какие-то данные и перечисление айдишек картинок. И при добавлении основной записи (с картинками) сначала добавляются картинки (и опционально чистятся старые), берутся новые айди и добавляются в основную таблицу. Если айди пикч не получены - исключение. >>3322945 >>3322971 Практически все тоже самое будет при работе с фс, никаких демонов здесь не нужно, пускай приложение другим потоком дергает дохлые не рабочие сектора хдд до таймаута фс.
>>3278398 >есть Pandas для питонистов Пандас и перфоманс это смешно, алсо это психическая нагрузка соединять несколько источников через эту библиотеку, когда как в duckdb можно одним sql-запросом поженить csv, паркет, таблицу из постгреса и выплюнуть ее и в пандас, и в поларс, и обратно в базу, и вообще куда угодно.
>>3323121 Да мне перепилить нехуй делать. Вообще мне интересна именно мат часть - насколько я сосу по производительности? Есть какие-то тесты минимальной реализации?
>>3323157 >когда как в duckdb можно А кому он нужен? В серьезных проектах его нет либо его не затащить, т.к. нет экспертизы эксплуатации и разрабов не найдешь. Даже тупо развернуть где-нибудь на вируталке уже проблема т.к. нет нужных знаний и опыта использования
>>3324973 Иногда это целесообразно, но черезвычайно редко. Например, мы у себя в залупе хадупе храним cob_date как стрингу. Ибо это дата партицирования. Так нам удобнее хранить в YYYY-MM-DD. Все в банке знают что это партиция.
Почему нет свежих пиратских версий Aqua Data Studio? Нормальный же инструмент был. Пикрил - рутрекер, а на пиратбэй вообще 0 результатов. Подумал, что софтина загнулась, но нет, на офф сайте версия от 24го года есть.
Может я от жизни отстал и это уже нинужно? Какой сейчас инструмент используют для доступа к различным бд в одной программе, какой-нибудь DBeaver? Нужно PostreSQL, MSSQL, MySQL, Oracle, Sybase - работаю с разными вендорами да
>>3278398 Да их просто заебал хадуп. Исследование данных для ДС должно быть быстрым. Нет заранее составленного плана. Нет алгоритма.
Алсо есть еще один очевидный трюк: если скачать 1/100 данных из прода взятую истинно случайным образом, то механика создания модели и ее результаты будет такие же. Просто ее нужно будет в конце доучить всеми имеющимся данными
>>3278398 > Polars, Dask, Ray, DuckDB, и т.д. Что за нонейм кал? > Кто-нибудь может объяснить мне, какие задачи у этой ебалы? Очень быстро. Очень. Быстро. Можно на одной машине обрабатывать 100к реквестов/сек или даже 500к. Нахуя мне любые другие sql или какие-то монги если они в 100 раз медленнее? Многие запросы на обычных бд бессмысленно выполнять, ибо производительность никакая, конечно это связано с лм нейронками и обработкой бихдаты.
Разделение на микросервисы тоже в тему - огромные БД с огромными возможностями уже не нужны так как раньше, логика разделена, огромным кол-вом говнокода ничего не засирается, быстрота, надёжность, примитивность, все в плюсе.
Жди ещё больше развития этой темы, в будущем нахуй ничего не нужно будет что-то кроме лмдб и аналогов.
>>3327869 Каво, блядь? Сам-то понял что высрал? Всё это работает на обычных "таблицах", на той же лмбд твоих олапов построено чуть больше чем дохуя. И в каждой из реализации, кста, работают транзакции.
>>3327937 >пук Если ты ничего не понял, ещё не означает. что несвязное. Я у тебя спрашиваю, эксперт, тебе надо построить классическое аналитическое DWH, в котором будет ingest, модель данных, datamart слой, куда будут ходить аналитики и прочие BI-щики чтобы писать свои аналитические запросы. Жду от тебя описания решения на основе LMDB.
>>3327941 Просто берёшь и строишь, ты, блядь, совсем даун что ли? Неужели тебе безумно сложно представить как работает векторная индексация в многомерных массивах?
Чел, если ты такой даун что не понимаешь как подобное работает - тебе не стоит вообще об этом рассуждать и что-то там кукарекать про бд. Это не твоё.
>>3327967 >Просто берёшь и строишь Что и требовалось доказать. Я говорю, конкретно описывай решение, компоненты, на каких платформах работают, интеграции с другими системами, стоимость, сроки внедрения. Ничего ты не расскажешь, видно, что ты в этом треде прямо сейчас узнаёшь, что работа с данными - это не только база в микросервисе. Ничего, просвещайся.
>>3328047 Очнись, вкатун, ты маркетинга нажрался. Абсолютно все аналитические запросы отдаются команде которая работает с БД, она и пишет для этого апи. Никакие блщики и аналитики своими руками с БД никогда работают и не будут работать, не мечтай о доступе к бд.
Конечно я понимаю что ты вкатун и никогда с бд не работал, но можешь поверить мне, любые аналитические запросы не занимают больше 5 строк кода.
>>3328283 Позоришься тут только ты, вкатун, фантазируя про великие OLAP системы, которые кто-то годами очень сложно интегрируют, лолд. В реальности почти вся аналитка это полтора запроса к любой бд. Притом эти запросы можно оптимизировать как угодно, в отличии от написанного кем-то говна.
>>3328220 Вкатуна ты в зеркале увидишь. Пока вижу от тебя только общие слова. В следующем сообщение ты описываешь, хотя бы верхнеуровнево, схему DWH на LMDB, c DM слоем для аналитических запросов, или ты обосрался, хотя это и так было изначально очевидно.
>>3328407 Вкатун, ещё раз тебе говорю, слушай внимательно. Если нужна аналитика - ты ПРОСТО берёшь и ПИШЕШЬ на бекенде все нужные запросы к бд. Всё. Просто берёшь и пишешь.
Для тебя это сложно потому что ты вкатун, понимаю тебя, но писать код аналитики в бекенде проще чем работать с какой-то обосранной бд с своим синтаксисом и своими проблемами, которая написана наверняка на другом языке. Всё это нахуй никому не всралось.
И да, вкатун, ты наверное не в курсе, но все dw и прочий шизокал работают поверх обычных субд и все из них могут работать с внешними хранилищами. Просто берёшь и подключаешь kv хранилище к любой OLAP системе. Но т.к. ты в катун, ты даже помыслить об этом не смог, да, ну не фантазируй больше, штош...
>>3328472 >слушай внимательно Так что слушать, ты опять хуйню написал, быкендер. У тебя ограниченный кругозор технологий и дальше своей поляны ты видеть неспособен. >Если нужна аналитика - ты ПРОСТО берёшь и ПИШЕШЬ на бекенде все нужные запросы к бд. Всё. Просто берёшь и пишешь. Вот это ты эксперт. То есть то, что информация раскидана по разным СУБД, а каноничная архитектура подразумевает по базе на сервис, тебя не смутило. И аналитический запрос у тебя по сети через ДБлинки будет тянуть данные за периоды вроде года. Вот так архитектура уровня /pr. Это уж я молчу, что на проекте может быть много разных систем, не связанных между собой, с которых надо тянуть данные. Опять же, если даже предположить, что "эксперт" вроде тебя разрешил делать аналитику прямо в сервисах, то запуск отчётности вместе с пиковой нагрузкой положит твою систему к хуям. >Просто берёшь и подключ Примеры в студию, давай. Вот интеграции CH - там нет: https://clickhouse.com/docs/en/integrations Упс. Ну ладно, давай посмотрим просто FDW для PostgreSQL: https://wiki.postgresql.org/wiki/Foreign_data_wrappers Ох, тоже нет, ну ладно. Хотя и GP тогда тоже пролетает. Ну и так далее. Примеры интеграций в студию.
P.S.: поражает, как каждая web-monkey считает себя экспертом во всём, научившись писать CRUD-сервисы.
>>3328472 > Вкатун, ещё раз тебе говорю, слушай внимательно. Если нужна аналитика - ты ПРОСТО берёшь и ПИШЕШЬ на бекенде все нужные запросы к бд. Всё. Просто берёшь и пишешь.
Ты чо ебанутый? Или у тебя проекты уровня 3 факта, 2 справочника?
У меня только в банке кредитный конвейер это 7 разных баз данных. В каждой базе ориентировочно 10-50 табл. Аналитик просто умрет попробуя это все написать. А кроме КК ещё дохуя чего есть: риски, коллекшен, телефония, операционка, банкоматы, фрод, маркетинг, внутренние сервисы, капитал, гроб, кладбище, пидор.
Макака ебучая, кто вообще делает аналитику на беке?
>>3328493 > То есть то, что информация раскидана по разным СУБД, а каноничная архитектура подразумевает по базе на сервис, тебя не смутило. И что, в чем проблема? > Опять же, если даже предположить, что "эксперт" вроде тебя разрешил делать аналитику прямо в сервисах Что ты несешь, шиз? Всё что требуется для аналитики - простое создание прокси для всех запросов, прокси который к любой БД подключается. > запуск отчётности вместе с пиковой нагрузкой положит твою систему к хуям. Вкатун манямечтает, лол. Даже если не делать отдельную БД никакой проблемы с этим нет, ведь та же LMDB выдерживает 1кк запросов в секунду. Другие бд похуже будут, но всего лишь нужно запросы раскидать по времени. И конечно так мало кто делает, только если отчётность в целом нахуй не нужна и не является приоритетом. > Вот интеграции CH - там нет: https://clickhouse.com/docs/en/integrations АХАХАХ, вкатун, ты ебанулся совсем? Это что по-твоему? https://clickhouse.com/docs/en/integrations/data-ingestion/dbms/odbc-with-clickhouse Может ты англюсик не знаешь, вкатун? Держи на русском https://clickhouse.com/docs/ru/engines/table-engines/integrations/odbc > Ну ладно, давай посмотрим просто FDW для PostgreSQL: https://wiki.postgresql.org/wiki/Foreign_data_wrappers И снова обосрался, ODBC первым пунктом. > P.S.: поражает, как каждая web-monkey считает себя экспертом во всём, научившись писать CRUD-сервисы. Меня поражает твоя непроходимая тупость, вкатун. Ты буквально кинул ссылку и не смог прочитать её. Ты же буквально даун, чел, нахуй ты вкатываешсья вообще? Чтобы над тобой на собеседовании орали всем отделом?
>>3328636 > Аналитик просто умрет попробуя это все написать Аналитикам вообще не выдают никакие доступы к БД, они с продом вообще никак не связаны. Им либо выдают готовые данные, которые они запросили и которые им дали с прода, либо отдельные БД, в которые весь кал с бека отправляется. > Макака ебучая, кто вообще делает аналитику на беке? Ты думаешь что апи для бд не на беке пишется или что? Аналитика по-твоему как-то сама появляется магическим образом или как?
>>3328903 Ты троллишь? Как быть в ситуации когда у тебя дохуялион баз данных? И все эти данные надо как то между собой связывать, агрегировать, строить разные слои.
>>3329081 Просто берёшь и все запросы транслируешь в другую бд, в которую всё это складируется, без транзакций, офк. Это на бекенде обычно делают, ты правильно угадал. Иногда всю бд копируют или составляют всякие хитрые обновления. Вместо какой-то шизоидной DWH и прочей маркетинговой чуши достаточно обычного хранилища kv, подключаются к нему на питоне пишут все аналитические запросы. Пистон и kv бд из-за этой хуйни и взлетели, ибо это гораздо эффективнее чем любые другие подходы.
Эти вкатунские маняфантазии про DW в реальности нахуй никому не нужны, по обыкновению это инициатива всяких шизов и швали из менеджеров которые решили на откатах сыграть.
>>3328894 ODBC - это снадарт драйвера. Такой же, как и JDBC. Тебе нужна ещё реализация под конкретную базу. Вот список драйверов ODBC из Python wiki, там нет LMDB: https://wiki.python.org/moin/ODBCDrivers. LMDB через bindings работает, если что. Ты как-то проигнорировал вопрос про перформанс тяжёлых query с распределёнными по сети источниками. Очевидно, ты не знаешь , что ответить. У тебя твои сервисы будут ещё и как кластер Хадупа, видимо, раьотать. Про solid, ты, конечно, ничего слышал тоже, хотя вроде ожидаемо от webdev. Ну, тут чувствуется тон веб-мастера "интернет-магазины под ключ". >>3328903 >апи для бд Никто не интегрирует потоки данных через web api. Для этого у самой базы есть средства для интеграции, и есть ETL инструменты. Но вообще потоки данных с сервисов сливают через Kafka, как самую популярную шину данных. Ну и в целом,тебе уже всем тредом объясняют, но ты, конечно, давай, ты же прав - а значит можешь сэкономить компаниям буквально миллиарды. Облачные провайдеры просто деньги печатают, а ты знаешь, как проще. Почему ты ещё не новый Матей Захария какой-нибудь - не знаю. >>3328584 Так это прокачивает технический speech. А тупые вопросы всегда самые сложные. Вполне возможно, что твои коллеги находятся на таком же уровне, или вообще не задумываются, а почему бы всё не делать на беке? Зачем нужна СУБД? Просто на работе обычно все больше стесняются.
>>3329145 >Тебе нужна ещё реализация под конкретную базу. Просто берёшь и пишешь, ничего в этом сложного нет, обычный c. Опять же, если для тебя столь примитивные функции сложны и необычны - тебе вряд ли стоит этим заниматься. >Ты как-то проигнорировал вопрос про перформанс тяжёлых query с распределёнными по сети источниками. Очевидно, ты не знаешь , что ответить. Конечно я не знаю как ответить, я даже не знаю что ты хотел высрать. Все тяжелые запросы собраны на одном сервере, распределение микросервисов как раз идёт по тому какие запросы и как часто обрабатываются. > У тебя твои сервисы будут ещё и как кластер Хадупа, видимо, раьотать. Если это потребуется вообще, к 128тб ещё пиздюхать очень долго на микросервисах. У меня не гугл и не амазон, данных всего на 140тб накопилось за три года. > Про solid, ты, конечно, ничего слышал тоже, хотя вроде ожидаемо от webdev. Ну, тут чувствуется тон веб-мастера "интернет-магазины под ключ". Шиза какая-то пошла уже, солид, блядь, лол > Никто не интегрирует потоки данных через web api. Конечно нет, ведь это делают через нахуя тебе палить через что их делают, кек, страдай > Но вообще потоки данных с сервисов сливают через Kafka, Как там в 2015 году, вкатун? Старые статьи читаешь, читай что-нибудь поновее.
>>3329160 >Просто берёшь и пишешь, Ну то есть ты наврал про "известные и простые интеграции в любую OLAP". Разобрались. >и пишешь, ничего в этом сложного нет, обычный c Я же спрашиваю, сроки внедрения, бюджет, архитектура. Ты скромно промолчал. То есть опять пустота. >я даже не знаю Это потому что уровень твоей экспертизы сильно ниже понимания проблематики. Сервисы разделены, а аналитика нужна в одном месте. >Если это потребуется вообще Ну то, что в твоей webdev конторе с таким не сталкивались, не означает в масштабах индустрии вообще ничего. >Шиза какая-то пошла уже Ну, сочетание двух зон ответственности в одном сервисе? Раздельное машстабирование нагрузки, технологий, команды, которые над этим работают? Ошибки аналитики, которую моджно подождать, кладущие critical сервисы? Иентересно, кто нанимает СТО, который одобрит такое. > палить > в 2015 Учитывая историю сообщений, тебе едва ли кого тут удалось заинтриговать, так что можешь оставить своё секретное знание себе. Я же говорю, рынок ждёт твоих откровений, тебе топы сделают отсос с проглотом за такое. Вперёд.
>>3329174 >Ну то есть ты наврал про "известные и простые интеграции в любую OLAP". Разобрались. Не понял, интеграция через ODBC есть, подключение есть, для тебя написать полторы функции на с это как-то сложно? Блядь, даже GPT с этим справится, просто по документации берёшь и пишешь.
Если сложно то ты видимо никогда в целом программированием не занимался и вероятнее всего местный клоун, так что бессмысленно с тобой говорить...
>>3329182 Ну как то ты слился быстро. Челик, проекты в нормальных компаниях - это не просто написать две функции в своём пет-проекте. Если ты будешь там персональные данные передавать, а они у тебя скорее всего так или наче есть, то все архитектурные комитеты, безопасники должны всё согласовать. Тем более на C, где гарантия консистентности данных, отсутствия ошибок памяти? Сколько по времени будет отладка проходить и сколько компания потеряет денег за это время? Кто будет латать дыры security? Слишком много рисков на навыки разработки человека, который не знает, что такое SOLID. Уже даже правительство США рекомендует не писать на C/C++. Ну, у тебя-то проблем точно не будет. Ну ладно, ты протолкнул свой драйвер, СТО отошёл покурить и все согласились. По остальным пунктам что? Нихуя. Ну зато ты на С умеешь писать 2 функции, где ты только такому научился? Может уже закончишь? По твоей штанине на весь раздел уже течёт.
>>3329191 >Тем более на C, где гарантия консистентности данных, отсутствия ошибок памяти? Никто не пишет на с, все пишут на выбранном подмножестве с/с++. >Сколько по времени будет отладка проходить и сколько компания потеряет денег за это время? Мой драйвер занимает 178 строк кода, например. > SOLID Для петухов. > Уже даже правительство США рекомендует не писать на C/C++ Обязательно слушайся. > Может уже закончишь? По твоей штанине на весь раздел уже течёт. Чел, я тебе ещё раз говорю, всё это не нужно и бессмысленно. Сколько бы ты не отрицал реальность, но втои мантры про DW и SOLID (к чему это вообще?) бессмысленны. Никто так не пишет в 2к25 году, кроме промытых корпоблядей с легаси которое никто годами не переписывал.
>>3329257 > не нужно > проигнорировал все неудобные вопросы Я тебя про строки кода спрашивал что ли? Нет. Авторитет твоего мнения на тему того, кто и как пишет уже понятен. Вопрос - долго будешь позориться тут?
>>3329266 ООП-петушок рассказывает про авторитетное мнение, лол.
Слушай, может ты про какой другой СОЛИД высрался? Просто я не понимаю как можно быть таким безумным вкатуном-шизом который про солид кукарекает в треде про бд, лол
>>3329314 Судя по тому, что ты сменил тему и просто кидаешься какашками, можно заключить, что ты признал свою неправоту на тему OLAP на LMDB в сервисах и добавить тебе нечего. Это хорошо. Дальнейшее общение не слишком интересно ввиду твоей зашоренности и высокой степени догматизма, явно слепо унаследованного из определённой кодерской субкультуры. С таким же успехом можно поговорить с нейросетью. Поэтому не мешаю. Замечу лишь, что любому профессионалу очевидно, что и ООП, и ФП, и процедурное, реактивное, аспектно-ориентированное программирование, и OLAP, и OLTP, и библиотечки на C, микросервисы и монолиты - всё просто инструменты, которые имеют свои плюсы и минусы и свою область и специфику применения. Удачи.
>>3329316 Погоди, ты тут несколько постов доказываешь мне как невозможно построить OLAP на LMDB потому что невозможно написать аналитические функции на питоне потому что потому, и я тут догматик? Здоровенные проекции конечно, ничего не скажешь.
Алсо, ещё вспомнил твой обсер с питоном и лмдб, в котором ты увидел новое для себя слово - биндинги, кек, и сразу же обосрался в треде, что-то несвязно кукарекая про драйвер. Забавно, уже даже не обращал внимания на эти высеры вкатуна с DW-шизой в голове
И напомни, ооп-петушок, к чему ты приплёл SOLID? Ты ощутил потребность сказать что-то умное, но забыл снять штаны?
Работаю джуном системным аналитиком в банке Из стека - это greenplum, airflow и питон Сам делаю всякие маппинги и документалку к ним пишу Пока ничего особо интересного Планирую разобраться в разработке, как вообще происходит все etl процессы, архитектура строится, потоки и тд Подскажите как вообще расти как специалист? Планирую лет через 6 стать примерно архитектором данных Может есть ещё какие-то более интересные или активные смежные направления типа MLOps или облачные хранилища Поделитесь плиз у кого опыт есть в этих вопросах или знает чего по этому поводу
>>3329385 >облачные хранилища Нуууу из облачных остались aws glue + athena + redshift. Но в России aws нахуй никому не интересен. Из ажур - synapse, тоже нахуй не упёрся. Databricks - санкции. Snowflake - санкции. Про informatica, talend, alation, collibra тут почти никто не слышал. Остаётся яндекс и опенсоурсное, всякие там апачи и прочее.
>активные смежные направления типа MLOps Это из другой оперы.
>Подскажите как вообще расти как специалист? Книжки читать. O'reilly.
>>3329649 Нет четкого определения что такое SOLID, каждый аффтор несёт свою собственную вариацию. То же шизло выше предлагает применять его не только к коду, но и к БД и его совершенно не смущает что это звучит как бред дошкольника. И это обычное явление в среде поклонников всяких солидов и ооп. Осторожней с этой хуйней, как и с любой другой сверхидеей.
>>3330621 при применение солид к БД согласен, эзотерика какая-то а разве солид - это плохо? вроде позволяет поддерживать/расширять код, явно лучше, чем строчить всё в одном файле? >ооп а со сверхидеей ооп что не так? голанг-разработчик в треде, все ссым на джавистов!? ведь только в джаве ооп это реальная ебля и огромное кол-во спагетти кода
>>3330650 > эзотерика какая-то Эзотерика приятнее будет. Это просто шиза. > а разве солид - это плохо? вроде позволяет поддерживать/расширять код, явно лучше, чем строчить всё в одном файле? Смотря от задач, очевидно. Иногда абстракции хорошо, но чаще это хуета и шиза, интерфейсы ради интерфейсов, типы ради типов. > а со сверхидеей ооп что не так? Абстракции протекают и мешают, очевидно. Вместо того чтобы писать код, пишут тесты на кучу интерфейсов и абсракций. Компонентный подход (для ооп композиция вместо наследования) куда адекватнее в этом плане, но реализация не так проста. > ведь только в джаве ооп это реальная ебля и огромное кол-во спагетти кода Можно на любом языке написать невообразимое макаронное поделие приправленное дерьмищем и аскридами, ооп позволяет это делать. И примеров этому не счесть.
Господа, у меня общий вопрос по быстродействию. Допустим, у меня 2 гигантских селекта, которые я объединяю с union. Для себя в конце каждого на момент запиливания я использую group by, чтобы понять то ли я вывожу, но есть ли смысл группировать в конце каждого селекта, если груп бай все равно выберет нужное?
>>3334406 Что значит "ГИГАНТСКИЙ СЕЛЕКТ"? У тебя большое количество данных или большой результат? UNION удаляет дубликаты и сканирует для этого каждую строку, а UNION ALL просто прилепляет строки вниз существующей выборки.
Аноны, подскажите ньюфагу. Делаю проект (что-то вроде корпаративного планировщика задач для организации из 70 человек). Вся база данных на SQLITE. Есть три таблицы: авторизация (логины и пароли), события календаря и информация о работниках (должность, департамент и т.д.). События календаря будет самой объемной таблицей, так как минимальная длина события - 30 минут.
Как будет правильней: выносить каждую таблицу в отдельный db-файл, или наоборот, сделать один db-файл, а в нем три таблицы? И как будет правильней хранить события - для каждого работника в отдельном файле/таблице, или для всех работников в одной таблице/файле?
>>3335966 > авторизация (логины и пароли) В общем случае так делать неправильно, но предположим, что у тебя лаба или пет-проект, где возможно всё. > Как будет правильней: выносить каждую таблицу в отдельный db-файл, или наоборот, сделать один db-файл, а в нем три таблицы? Правильно в одном файле. Несколько файлов - это баз данных, с несколькими базами данных можешь забыть о транзакциях и ссылочной целостности. > И как будет правильней хранить события - для каждого работника в отдельном файле/таблице, или для всех работников в одной таблице/файле? В одной таблице. Прикинь создавать по таблице на работника, а потом ещё генерировать километровые селекты из-за union по 70 таблицам.
>>3336068 И еще вопрос: какие есть способы обезопасить базу sqlite от взлома? SQlite нет функции доступа к файлу bd по паролю (точнее, они есть, но замороченные)
>>3336194 > Пароли у меня в хэшированном виде, если что. Ну, хотя бы так. >>3336196 В чистом SQLite мало что можно сделать, разве что обезопасить доступ к самому серверу. Файл БД шифровать мало толку, даже если сумеешь это сделать, всё равно основное приложение находится где-то недалеко, ключ просто возьмут из его конфига.
Можно ли делать огромную таблицу со всеми действиями пользователей? То есть такой лог всего всего, на случай, если что то пойдет и не так и придется разбираться что случилось? Можно ли по этому логу гулять по ссылкам на события? Например, сначала пользователь заказал товар, это записалось. Потом через неделю до пользователя доставился товар и он открыл спор по этому товару. Я бы хотел, чтобы это событие хранило идшник события с заказом, чтобы можно было достать историю. Не будет ли проблем, если таких действий много, но при этом сильно далеко в прошлое обращения не уходят?
>>3338550 Норм практика, только партицируй по дате. Только подбери диапазон месяц или день. И навесь индексы на те поля к которым будешь обращаться, но не переборщи, иначе будет запись долгая.
>>3338550 P.S. наверно одного индекса будет достаточно. По id пользователя. Индекс глобальный по всем партициям. Чтобы быстро доставать все действия юзера.
>>3338550 В бухучете так и делается, там каждое движение со счета на счет - это отдельная строка в таблице. Если ожидается прям дохулион записей, подумай о шардировании по userId.
>>3338570 >>3338574 >>3338682 Посмотрел как это в моей дб делается. Делается PRIMARY KEY по паре из атрибута по которому нужно разбивать и ид. И уже не первому атрибуту указывается диапазон. Но там это делает в контесте хранения партишионов на разных устройствах, а не про логическое ускорение. С какого момента стоит париться? Или если в таблице меньше миллиона записей, то можно хуй забить и потом уже когда нибудь это сделать, когда таблица разрастется ?
+ я увидел как можно в запросе указать партишн для поиска. То есть я могу написать запрос который будет искать сначала среди заказов которые были в ближайшую неделю, а потом уже, если не было найдено нужного, искать в остальной таблице. В предположении, что подавляющее большинство нужных строк лежит в этом диапазоне, я смогу не париться о размерах основной таблице, даже если она огромная. В крайнем случае, можно будет такие запросы пачками отправлять, ценой увеличенного времени ожидания пользователей
Еще вопрос возник. А можно ли в одну таблицу уместить все события? Или мне в любом случае надо будет делать 1 большую таблицу где будут храниться только ссылки на события в другх таблицах которые уже описывают структуру конкретного типа событий
>>3338550 Начнём с того, огромную таблицу - насколько "огромную"? Можно в количественном выражении сказать? Это гигабайт? Сто гитабайт? Терабайт данных? Далее, как именно эти данные будут использоваться? Будет ли у вас обнаружение мошенников в реальном времени? Бизнес-аналитика? Обучаете ли вы нейронки на этих данных? У вас работают в компании бизнес-аналитики? Дата сцаенс?
Если 100+ гигабайт данных + в компании есть аналитики и дата сцаенс ---> то дата лейк/лейкхаус + айсберг. Если 1-10 гигабайт данных и компания маленькая ---> обычный postgres.
Вообще, это называется "customer data platform" или "customer 360" за бугром.
>>3338960 Я этим вопросом и задаюсь тут >>3338892 > Далее, как именно эти данные будут использоваться? Я пока писал ответ, подумал, что если есть такая вот единая таблица, то логично с нее все стягивать: список заказов пользователей, номера транзакций при оплате и так далее. Короче все, что должно храниться все время. Набор корзины сюда не входит, но его в целом и не нужно так дотошно трекать. Но почему бы тогда не разбить эту большую таблицу на мелкие. Плюсы следующие - проще структура таблицы, запросы эффективнее, потому то для стягивания истории заказов, мне нужно будет стянуть это только с соответствующей таблицы, не трогая данные с инфой о открытых спорах клиента, истории его платежей и чеков. Но тогда, по идее, задача сводится к базовой в которой не нужно думать о размере таблицы пока в ней ключей меньше чем 100 миллионов. Думаю, что лучше все разбить на разные таблицы с общим ключом event_id, что бы у меня в одном месте была на виду последовательная история события с датами.
>>3338998 Это квадратно-гнездовое мышление. Для 100500 случаев использовать один и тот же подход. Если у тебя аналитика --> можно брать столбцовую бд, типа clickhouse. Если у тебя рекомендации а-ля вы купили синие трусы, вам могут также понравится зеленые --> можно взять графовую бд а-ля Neo4j. Если у тебя временные ряды, имеет смысл взять kibana + logstash + elastricsearch.
То что ты делаешь - это хуяришь всё в одну кучу. У тебя по сути одна бд - она же и швец, и жнец, и на дуде игрец. Реляционные бд не ориентированы на то, что кто-то начнёт хуярить в них временные ряды. Для временных рядов есть специальные бд https://www.influxdata.com/time-series-database/
Короче твой подход - нагружать одну и ту же базу данных разными задачами, пока она не крякнет, не разрастётся до объёмов пока ею невозможно станет пользоваться.
>>3339030 С корзиной я соглашусь. Но в остальном то что не так? Это не временные данные, а те которые должны всегда быть доступны по запросу спустя хоть 10 лет. Что не так то?
>>3338550 У нас на одном веб сервисе на постгресе есть такая "мусорка", куда все подряд записывается. Логи приложения, какие-то жсоны, хмли, даже пдфы. Разрослась до 300кк записей, почти 150гигов. Поиск по индексам до сих пор отлично работает. Но про какой нибудь like можно забыть.
>>3339036 Я уже сказал что не так. У тебя слишком топорный подход. Лично я бы поставил какую-нибудь kafka и слушал изменения в postgres. Когда кто-то что-то покупает, событие выгружается в объектное хранилище с озером данных. Там было бы три папочки - "сырые данные", "обработанные" и "золотые данные", внутри папочки с юзерами и датами. И туда можно лить гугл аналитику, данные из магазина, 1с бухгалтерию, чаты, данные доставки. Данные аггрегируются, очищаются и трансформируются в пайплайне. И на выходе загружается ну допустим в какой-нибудь clickhouse. И от этого можно плясать, уже в кликхаусе я могу узнать допустим когда и сколько раз покупатель заходил на сайт, сколько делал покупок, сколько раз общался в чате, доставила ли товар служба доставки и так далее.
Временной ряд - это просто данные привязанные ко времени. Допустим, термометр считывает температуру каждые 3 секунды и записывает в бд. Или курс акции. Или статус сервера например.
>>3339030 Buzzword driven development уровня петушиных стартапов. Потом охуеешь искать людей, которые со всем этим говном работали на проде. Нормальные люди ставят постгрю и не выебываются.
>>3339157 Ну блять одно и то же... одно и то же... Ноль свежих идей. Как 20 лет назад выучил один подход, так ты его везде и хуяришь. А я плохой, типа посоветовал новый подход. Так может это проблема в тебе, а не во мне. Ты застрял где-то в прошлом и забыл посмотреть на календарь, какой сейчас год.
>>3339300 >Ноль свежих идей С примера по Neo4j орнул. Сразу видно долбоеба, который ей никогда не пользовался. Она блядь не строит граф, а ищет по графу. Сам граф должен лично ты руками собирать. Соберешь неправильно - получишь хуйню. Спойлер: ты неделю будешь сидеть получать хуйню, а потом поймешь что твой юзкейс в принципе в графовую модель не вписывается. Сопутка из твоего примера как раз не вписывается. Там слишком много условий: одни бренды не хотят чтобы их показывали под другими, другие наоборот башляют чтобы быть всегда и везде. А как только пошли условия вся эта графовая залупа валится как карточный домик. Оно хорошо работает когда есть четкая одноранговая связь А - Б, ну то есть почти никогда.
И то не говоря что все запросы на этом ебаном птичьем языке придется самому написать, ручками. А для того чтобы привязать что-то к чему-то надо, внезапно, знать что есть что-то к чему можно привязаться блядь. То есть это чисто вторичная база для вычислений, и должна быть исходная.
Короче ебли с греблей там ебнешься. При этом далеко не факт что результат будет быстрее чем поставить какой-нибудь Apache AGE на постгрес и мозги не ебать.
Какой у вас темп чтения? Сколько за день читаете страниц? У меня со скрипом идет пиздец, на 104 странице и далее, оперативка трещит по швам, отвлекаться на все начинаю
>>3339791 Так а нахуя ты справочную литературу как беллетристику читаешь? Ты бы еще таблицы брадеса по сто страниц в день читал. Пиздец, что отсутствие нормального образования с людьми делает.
>>3339889 Нормально ты сам себя приложил. Если я шитпостер и тролль, то ты тупорылый еблан, который не осилил сто тсраниц текста прочитать. А если я прав, то ты тупорылый еблан, который не умеет работать с учебной литературой и информацией.
>>3339927 Аутист-графоман не ответил ни на один вопрос но продолжает растягивать диалог требуя к себе внимания. Друзей наверное нет, а общение хочется? Плак плак, потребуй еще уделить тебе внимание, маленький
>>3339939 Ну да, это же я прибежал в базотред справшивать как книжки чиатать. А когда мне намекнули что этому базовому навыку обучаются в шкиле, порвался и закатил истерику.
Пора взрослеть. Аноны не твоя мамка. И на твои истерики и ультиматумы что-то для тебя сделать, просто проведут тебе шершавым по губам.
>>3339955 Хуя, графоман пробзделся, наверное что-то интересное написал? Нет - вангую там нет ответов на мои вопросы, поэтому даже читать не буду, лучше лишний раз репортну задрота с ручками-веточками без друзей
>>3339955 Че дебил, ты по факту дебил соснул - дочитал до 136 страницы и там как раз все базируется на первых главах, на базовых структурах в теме про колоночные БД ссылается на ss-таблицы из первых глав.
Так что ты по факту дебил который обосрался. ПО ФАКТУ ДЕБИЛ
Ну и я мать твою ебал и весь твой род за то что мое время воровал, чмошник
один предлагает аналитику собирать через бэкенд другой поциент ему втирает биг дата дрисню. Тот не понимает что за хуйня происходит другой уже ебнулся от калпоративных хранилищ и не может вдуплить чзх
другой поциент спрашивает как он сука быстро читает, как будто в ебаной началке чекает скорочтение ёбаное на что ему другой анон справедливо замечает, но поциент начинает ссылаться к какому-то содержанию этой хуйни с каким то там сука ss(нацист бля что ли?) пиздец - деды воевали так-то
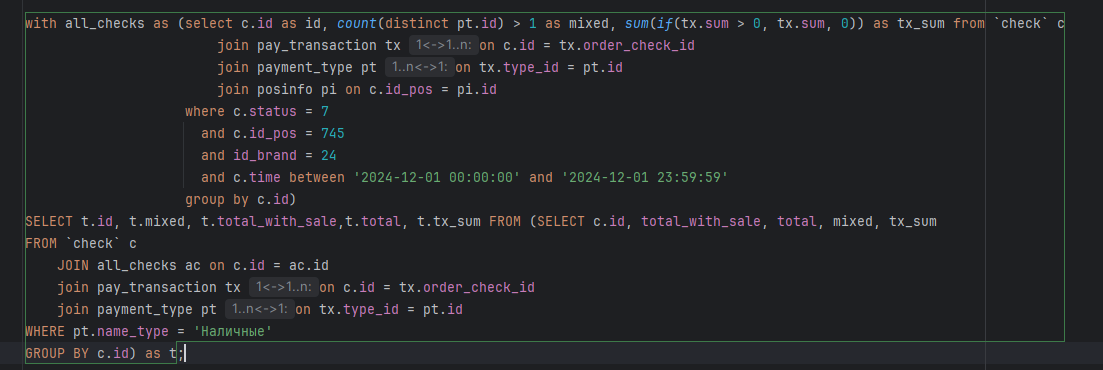
Анон, помогли, пожалуйста, с задачей. Нужно сделать фильтрацию выручки по типам оплаты. Выручка считается по чекам в таблице check. С чеками связаны транзакции, в которых хранится информация об оплате (также стоимость чека хранится в самом чеке). Транзакции могут быть разных типов (наличные, безналичные и так далее). Транзакции хранятся в таблице pay_transaction, тип транзакции - в таблице payment_type. Считать выручку мешают смешанные чеки. Смешанные чеки - это чеки, оплаченные несколькими видами оплаты. Например, наличными и безналичными. Для таких чеков создаются несколько транзакций разных типов. Чтобы определить тип чека (смешанный или простой) я считаю количество транзакций разных типов. Если это число больше, то чек смешанный. Но смешанных чеков в природе не существует. Это просто чеки, оплаченные разными видами оплаты. И наличная и безналичная части этого чека должны идти в соответствующие категории выручки (в категорий налички или безналичного расчета). Как это можно сделать?
Я придумал для простых чеков считать выручку на основании полей check.total_with_discount и check.total. Это правильно. Но со смешанными чеками все сложнее. При подсчете, например, выручки наличными, нельзя просто взять и прибавить стоимость смешанного чека, потому что она общая. Нужно взять из транзакции нужного типа (наличка) количество оплаты и присуммировать к общей выручке.
Как это можно реализовать? Я уже запутался. Логика сложная. Мешает то, что при джойне таблиц с транзакциями строки с чеками дублируются и их приходится группировать, чтобы удалить дубликаты. С агрегаций и группировкой в этой запросе вообще проблемы.
>>3342226 > Выручка считается по чекам Здесь ошибка. Выручка считается по транзакциям. А чеки нужны только чтобы определить список транзакций. Зачем тебе вообще чек, чтобы определить плюсовать сумму в нал или в безнал? Если ты просто возьмешь все транзакции, то часть из них будет нал, а часть безнал. Обе суммы считаются оконной функцией в один проход.
Для начала набросай структуру таблиц и тестовые данные https://dbfiddle.uk/QaP5BhZ0 Без этого все равно говорить не о чем.
Не опасно ли в одной таблице хранить данные от разных пользователей? С одной стороны понимаю, что если id проверяется, то пользователь к чужим данным доступ не получит, но все равно как то стремно, что единственное, что огрничивает пользователя от чтения чужих данных - его ид
>>3343457 Так-то можно продолжить это "стрёмно" и в итоге решить, что для каждого пользователя должна быть своя независимая БД на выделенном сервере. Ограничивает от чтения чужих данных не id, а прямота твоих рук, когда ты пишешь код с реализацией разграничения доступа. К примеру, нельзя доверять id, присланному с клиента, вместо этого надо его брать из пользовательской сессии или из подписанного токена.
>>3343482 > Так-то можно продолжить это "стрёмно" и в итоге решить, что для каждого пользователя должна быть своя независимая БД на выделенном сервере. Но только это никак не улучшает ситуацию. > Ограничивает от чтения чужих данных не id, а прямота твоих рук, когда ты пишешь код с реализацией разграничения доступа. > К примеру, нельзя доверять id, присланному с клиента, вместо этого надо его брать из пользовательской сессии или из подписанного токена. Да, это понятно. Но все равно ошибки случаются. Хотелось бы, чтобы был какой то доп уровень безопасности, усложняющий написание кода с такими дорогими ошбиками
>>3343457 >Не опасно ли в одной таблице хранить данные от разных пользователей? А ты данные ШИФРУЕШЬ? Если да, то почему это должно быть опасно..? И што тогда произойдёт... ну окей... ну кто-то получил данные... там всё зашифровано... иииииии? А если не шифруешь, значит ты сам еблан и полностью заслуживаешь, чтобы у тебя спиздили данные, на твоих клиентов оформили кредиты, вывели бабло в крипту и ты мучался бегая по судам. Ты заслужил хорошую хакерскую атаку, мне тебя не жалко будет, пускай ты красный как помидор будешь решать, стоит ли говорить пользователям об утечке? Неее лучше сделаем вид, что ничего не произошло. Я уже имел дело с такими как ты, пока в жопу петух не клюнет, погроммист не спохватится.
>>3343534 Это на самом деле не прикол. В европе так по GDPR работают. Все личные данные зашифрованы персональным ключем пользователя. И когда пользователь требует всю личную информацию удалить, то вместо того чтобы бегать по всей системе и всем хранилищам ища эти данные, просто выкидывается ключ шифрования. А без ключа остаются обеличенные идентификаторы и зашифрованная тарабарщина.
>>3343534 Ну давай тогда ничего не будем шифровать. Нахуй вообще придумали шифрование - давай все оставим открытым. Потому что какому-то программуле было лень ебаться, лень придумывать схемы как сохранить/восстановить данные если чо, лень читать про шифры. И вообще, самая правильная идея - это положиться на авось. Авось пронесёт. Я же 10 лет работаю и вообще ни разу не ломали! Да кому это надо! Да какое хакерство, камон в 2024-м году лул! Но почему-то данные ШЕСТДЕСЯТ СУКА ПРОЦЕНТОВ российских компаний уже слиты в даркнет. Они также думали АХАХАХ ЛОХИ, да кто нас будет ломать, кому мы нужны. В итоге их и наебали.
Пытаюсь построить конкурентный межпроцессный обмен на sqlite. Организовано так: несколько процессов дёргают 1 файл, расположенный в озу (tmpfs, linux). ПРАГМЫ такие: >journal_mode=WAL >synchronous=0 >temp_store=MEMORY Работает кое-как... Пока до производительности не дошло, но уже сейчас, при каких-то 10fps выскакивает 'database is locked' (который в одном из случаев исчезает после того, как я UPDATE и SELECT в коде поменял местами... что это было?). Но, кроме того, неимоверно растёт -wal файл, который sqlite держит рядом с базой данных. Никакие wal_checkpoint, wal_autocheckpoint, journal_size_limit не помогают. За секунды может нажрать МБ, хотя исходная 20КБ-база содержит 5 записей и одну таблицу. Растёт бесконечно, короче, и ОЧЕНЬ быстро! Есть шансы довести всё это до ума? Это я ещё windows не брал, где нет ОЗУ-шной ФС, и надо что-то городить платформенное... А мне нужно КРОСС обязательно, или хотя бы linux.
Вообще, насколько здраво использовать sql как хранилище переменных, критичных к real-time? Если мне нужно забрать статус определённой, быстро ли будет осуществлён доступ к ней по имени? Типа "SELECT value FROM state WHERE name='position';". Потом fetch всякие.
SQL удобен, потому что мне не только переменные дёргать, но и определённую структуру выстроить, что во всяких redis/memcached не реализовано. Именно переменные для краевого случая я привёл в пример. Кроме того, сам язык SQL предпочтителен как везде и всеми понимаемый, универсальный.
>>3343540 >>3343542 Ебать вы дауны. Вы не вникая в суть вопроса хуйни понаписали которая в голову пришла, чтобы умными показаться. Второму я отвечать не буду даже, первый хоть в нормальном тоне +- адекватную мысль написал, которая все равно не относится к вопросу. Но ему я отвечу. То, что ты предлагаешь, не решает мою проблему. У тебя все равно при запросе от пользователя будет поход в бд ключей, там по ид пользователя достанется ключ и им остальные данные расшифруются. Моя проблема полностью не решилась. Если бд только записывает, а потом возвращает пользователю его данные, то ок - в случае чего он получит мусор. Но если бд еще что то делает с данными, то это не поможет. Если я допущу ошибку и у меня будет криво выбираться id, то бд будет криво расшифровывать и записывать чушь. Это не решение проблемы. Мой вопрос про минимизацию допуска такой ошибки.
>>3343578 Чел, перед тем как вываливать свой гонор ты бы почитал что такое асимметричное шифрование. Приватного ключа у владельца базы может вообще не быть, прикинь? В базе хранится абракадабра, котроая может быть расшифрована только на клиенте. И сохранность приватного ключа это головняк самого клиента. Где он там у него храниться будет: на флешке, на хуешке, в сейфе - хоста базы это не ебет.
Тебя чет как-то во всей твоей "безопасной" схеме не смутило, что если такой тупорогий долбоеб как ты свое жало в таблицу пилит, то данные уже скомпрометированы.
>>3268780 (OP) > Q: Где хранить файлы? > A: Не в БД. Для этого есть объектные хранилища, такие как Amazon S3 и Ceph. Поясните, в чём будет проблема если я как гит насру жиденько файлами в файловую систему, только не по 50 килобайт, а по 500 мегабайт, и отсортирую их по хешам чтобы папки не перегружать, а в бд буду хранить, собственно, хеш?
>>3343590 Ну а какие еще вопросы могут быть у ебаната, который путает базу и приложение. То что ты назваешь "пользователями" это пользователи приложения, а не базы. И доступ к данным регламентирует приложение.
В самой-то базе можно настроить доступ каждому пользователю базы хоть построчно. Только ты коннектишь свое приложение к базе через единственного пользователя, а потом че-то пердишь про безопасность.
>>3343605 >И доступ к данным регламентирует приложение. я это понимаю. но страшно, что на уровне бд нет доп подстраховок. И если я случайно проебался и по какой то причине отдал в бд запрос "выбрать все заказы с дилдаками где id пользователя = uid " чужой uid, то оно так и отправится. Понятно, что данные надо проверять, но от багов никто не защищён на 100%. В связи с этимм вопрос, нельзя ли придумать еще какой то уровень защиты от выдачи не тех данных пользователю?
>>3343607 Почему авторизованный доступ к данным должен на уровне субд проверяться? Это зависит от логики приложения. В одном случае у тебя в приложении данные по пользователям разделяются, а в другом случае по организациям или подразделениям и т. д.. В СУБД должны быть объекты твоей предметной области?
>>3343603 >отсортирую их по хешам чтобы папки не перегружать, а в бд буду хранить, собственно, хеш? Бля это классическая ошибка. Хеши это ненадёжный способ ссылки на файл. Во-первых, у файлов есть метадата. Если ты предположим, открыл файл, у него меняется "last access date" и всё, хеш другой совсем. Тоже самое "created on" - один и тот же файл созданный в разное время имеет разный хеш. Во-вторых, хеши для картинок бесполезны. Две картинки могут быть визуально одинаковы, но иметь разный формат - один jpeg, другой png. И хеши у них будут разные. И в-третьих, тогда получается что у них будут вместо имен файлов хеши. Ну это будет тупо мусорка, файлопомойка, если файлов много, то будешь их миллион лет сортировать.
>>3343947 Ну и нахуя ты пиздишь? Буквально все что ты написал это неправда.
1) Метаданные типа времени создания хранятся не в файле а в ОС. 2) Функции хеширования прекрасно знают что захешировать нужно именно бинарное тело файла. 3) JPEG и PNG это разные файлы. У них не только тип отличается, у них структура хранения информации о пикселях отличается. Это такая феерическая чушь. Все равно что утверждать что все фото Тадж-Махала это дубликаты, потому что визуально одинаковы. 4) Про сортировку тоже хуйня написана. Если книги ставить на полку по одной, упорядочивая по первым буквам названия, полка будет заполнена отсортированными книгами, хотя никто ВСЮ полку никогда не сортировал.
Про хэш можно простой логикой дойти. Есди это работает так как ты написал, то как вообще тогда возможна проверка файла по хешу? Вот на сайте микрософта лежат образы винды и хеши для проверки. Как такая проверка возможна если при попадании этих образов в твою ОС у них creation date проставляется и они "меняются"? А если у jpeg и png одинаковое тело, то нахуй тогда png придумали? От нехуй делать?
>>3344031 Так никто не делает. Исключение какие-нибудь дешевые шаред- хостинги настраивают права пользователя phpmyadmin для кадого клиента, но все клиенты хостинга сидят в одной СУБД. В данном случает подключение phpmyadmin к mysql зависит от пользователя
В остальном везде пользователь для подключения к БД один на приложение или микросервис (или несколько если есть разделение на администраторский аккаунт и само приложение). Подключение не зависит от пользователя работающего с приложением
Авторизация доступа реализуется приложением . Обычная реализация: 1) У таблиц есть owner_id или department_id или аналогичное. Когда пользователь аутентифицирован, в сесси хранится нужный ID для фильтрации данных, он извлекается из сесси и добавляется к каждому запросу в WHERE 2) RBAC 3) Если есть иерархия организация - подразделение - сотрудник, то RBAC проверяется по всей иерархии
>>3345168 >>3345184 sapience solutions входные данные - знание sql учат гринплюму, pxf/gpfdist, airflow, clickhouse, superset это бесплатное обучение, если норм всё - берут на стажировку 50к в москве очно, я к сожалению мухосранск-боярин и поехать не смогу банально жить негде магистратура 1 курс
>>3345246 Хуйня какая-то. Ты еще в Астон блять иди в рабство. Есть же курсы у иннотеха, у неофлекс, еще у кого-то, где можно сразу на норм работу залететь.
>>3346015 А кому щас админы нужны, когда все компашки мигрируют в облако? Ну, разве что кроме госух, которые владеют слишком "важными" данными, поэтому опасно использовать третьи руки. Но и зп в госухе максимум 50к.
Ладно, может ещё не все мигрировали, но это активно происходит. Достаточно взглянуть на кол-во вакансий. Уже через год их останется ~100 шт на всю Россию. Это пиздец какая конкуренция там. И пиздец как мало работы. Либо ты становишься DBOPS/DevOps, либо пиздуешь на мороз жаловаться на несправедливость.
Это я к чему? Не надо катиться в ходячий труп, это все равно что хачкель учить.
>>3346623 Да хуй знает. Я в аналитики качусь. А ты куда хошь. Если тебе админство по душе, то и там наверное найдёшь работу. Думаю переход займёт ещё 3-5 лет. Если за это время успеть стать хотя бы мидловым или даже синьорским админом, то проблем с работой точно не будет. Другой вопрос, а как стать-то таковым? В девопс/сисадминстве-то понятно, там много инфы есть. А по дба по сути пара толковых книг всего. Тут надо 100% высасывать опыт у своих старших коллег, иначе не прокачаешься нихуя и так и останешься джуном. А джунам в будущем работы не будет в дба.
>>3346893 Хуйню не неси, дурачок, люди обучаются и нормально находят работу в дате. Блять что на форумах, что на ютубе такую хуету несут люди, которая вообще не соотносится с реальностью, я не перестаю ахуевать
>>3347516 легко читается + хорошо расписано, всё таки не индусами написана есть ОГРОМНЫЙ МИНУС - базируется на mysql по большей части, хотя другие диалекты тоже представлены постгре нет я не с нуля правда, может поэтому хорошо читается
>>3347535 есть задания но крайне немного, но САМАЯ ЛУЧШАЯ ПРАКТИКА НА ПЕРИОД 2025 ГОДА - https://karpov.courses/simulator-sql почти единственная бесплатная хуйня, карпов вообще нормальный мужик с нормальными курсами но платно нахуй надо 150 мега-годных задач похожих на реальные, есть теория (но лучше из несокльких источников черпать) у него ещё по матану есть бесплатный курс, тоже норм
Как ответственный человек, я хочу делать бекапы данных, однако, для меня критично, чтобы после каждой операции записи в бд, ее копия также изменялась на втором диске, чтобы в случае, если 1 диск наебнется, я мог со второго загрузить бд и повторно такую же схему настроить. Какая бд умеет в такое? Или мне нужно иначе дублировать операции записи на 2 диска средствами ос? Но я не хочу целые диски дублировать, а только дб - максимум, раздел. Советы?
>>3347620 Через ZFS можно настроить реплицирование только БД. Но ZFS работает на уровне файловой системы, а не на уровне логических транзакций базы данных, как это делают встроенные механизмы репликации в СУБД.
Например, для PostgreSQL репликация через WAL (аналог binlog в MySQL). Можно ещё использовать логическую репликацию, если нужно обновлять данные только отдельных таблиц.
Репликацию можно сделать синхронной и асинхронной. Синхронная обеспечивает, что транзакция будет завершена только после подтверждения записи на реплике. Асинхронная такого не гарантирует, поэтому в момент сбоя данные на 1 диске могут не успеть обновиться. Зато такой вариант быстрее. Выбирай по задачам.
>>3347632 Мне нужна синхронная репликация, желательно на уровне логических транзакций. Я еще нагуглил cockroachdb. Выглядит супер круто и удобно, однако там предполагается, что всегда должен быть консенсус и если он все таки нарушился, то восстанавливаться нужно из бекапа. А это мне не очень подходит, потому что 1) как я понял, там бекап это скорее что то, что руками запускается раз в сутки, а бекапить на другой диск после каждой транзакци оно не умеет 2) если все таки без бекапов а через консенсус делать, то нужно поднимать минимум 3 ноды (иначе если 1 наебнется, то пизда всему кластеру), что для меня излишне
Погуглил. Понял, что можно не выебываться и взять postgresql. Там транзакции и wal есть. Правда мне кажется странным, что уровень изоляции транзакции задается явно для каждой транзакции, а не глобально, но ладно. Может я пока еще не нашел способа явно задать, а это реально. Теперь по поводу wal. Можно 2 диска через mdadm в рейд объеденить и туда лог писать. Тогда, если 1 диск накроется, со второго можно будет восстановиться. Однако есть "но". Я боюсь, что в реале диске (особенно ссд) ломаются чуть сложнее чем просто "был идеальный диск с 100% целыми данными, а потом резко mdadm увидел, что диску пизда и перестал всё писать". Вдруг mdadm будет считать здоровым диск на котором уже данные начали херится? Тогда, когда у меня один наебнется окончательно, я охуею, когда начну читать данные со второго диска и увижу, что там половины данных нет. Такого не может быть?
>>3347659 >Понял, что можно не выебываться и взять postgresql. Правильно понял. Постгря - это охуительный комбайн с охуительным комьюнити, там есть все. Если чего-то нет, это скоро появится, как когда-то было с jsonb. Пока небинарные долбоебы тащат в проекты всякую новомодную хуиту, нормальные люди ставят постгрю и спокойно работают.
Какую субд выбрать под соло-разработку коммерческих сайтов, руководствуясь лицензионными соображениями?
Постргю, как слышал, тяжелее администрировать, зато полностью свободная и полно инфы по ней. Только фичи продвинутые мне не нужны. Мускл - непонятная лицензия, но в остальном кажется тем, что надо. Простая, ничего лишнего. МариаДБ вроде как лишена недостатка второй, но комьюнити маленькое и хз в каких моментах может всплыть не 100% совместимость с библиотеками фреймворка. Стремновато.
Оракл не пристанет с требованием плотить, если в закрытых проектах с прибылью юзать мускл?
Хватит хуйнёй страдать, братиш. Ты слишком много времени тратишь на сомнения. Просто бери постгре и всё.
Я так понял, у тебя что-то не шибко крупное. Для простых задач можно использовать минимальную настройку, и норм всё будет. Инфы по ней полно, всё настроишь с полпинка.
>>3348531 Я не понимаю откуда вы берете эти "настройки"? Из статей 2007 года? Какие нахуй настройки? Че ты там настраивать собрался? Ставишь контейнер с последней версией, прописываешь доступы и погнал. Настройщики ебать.
>>3268780 (OP) Бля, какой пиздец (про книгу кабаны, клеппман) - ОШИБКИ В ГРАФИКАХ + всратый перевод в некоторых частях, если вбить то же предложение в гугл транслейт - то появляется человеческий текст.
Книги короче проще через гугл прогонять, чем читать такой наеб
КОМУ ВАШИ БД ВСРАЛИСЬ-ТО???? ВСЕ УШЛИ В ОБЛАКА ДАВНО! НИКТО ИЗ ВАС БОЛЬШЕ НЕ ТРЕБУЕТСЯ! СБЕРБАНК РАЗРАБОТАЛ НОВУЮ СИСТЕМУ КРУЧЕ 1С И SAP, А ВЫ ВСЕ ЛОХИ!!!!!!!!!!!!!!
>>3348584 > КОМУ ВАШИ БД ВСРАЛИСЬ-ТО???? ВСЕ УШЛИ В ОБЛАКА ДАВНО! Что, БД в облаке перестала быть БД? > НИКТО ИЗ ВАС БОЛЬШЕ НЕ ТРЕБУЕТСЯ! Анон с двача и раньше был никому не нужен. > СБЕРБАНК Это который настолько не доверяет чужим облакам, что скорее потратит очередной миллиард деняк на содержание своих дата-центров, чем развернёт даже самый бесполезный сервис у вендора? > РАЗРАБОТАЛ НОВУЮ СИСТЕМУ КРУЧЕ 1С И SAP Но сам при этом не перестал юзать ни 1С, ни SAP.
Указал зп ниже 60к, даже так не взяли, хотя написал что опыт работы с бд есть. Ну и как мне вкатиться в ваше DBA? Или по возрасту кикнули — 29 лвл. Типа слишком старый и ещё и на ждуна хочет, лох какой-то. Так что ли блять??
В ответе мне написали "Большое спасибо за интерес к вакансии! К сожалению, сейчас мы не готовы пригласить вас на следующий этап. Ценим ваше внимание и будем рады получать ваши отклики на другие позиции."
Или может сразу в девопс катиться тогда? Там и вакансий побольше. Я так-то уже много по PostgreSQL прошёл, жалко как-то поворачивать назад. Какие мысли, кочаны?
>>3349251 >Указал зп ниже 60к, даже так не взяли Если думаешь, что можешь перебить зарплатой - то нет. Всегда найдётся чел дешевле тебя, готовый работать ну хоть за еду, ну хоть за отзыв. У нас в стране дохера чмошников, готовых за опыт унижаться.
Там уже было дохера претендентов и отказать могли из-за чего угодно. Не надо рефлексировать. Отказали и отказали, на автоматизме закрыл вкладку и пошёл дальше искать работу. Всё. Нечего обсуждать. Если ты будешь рефлексировать по каждому поводу "а почему?", "а как?", то и в 35 лет ты также будешь безработным.
>>3349271 >Там и вакансий побольше. Плохому танцору всегда что-то мешает. Если так сливаться, то никакая вакансия тебе не подойдёт. Представь, что я хочу стать музыкантом, беру в руки гитару и после первой неудачи говорю "ой чёто гитара слишком сложная, лучше попробую виолончель". Потом c виолончелью тоже не получилось... лучше попробую баян. И так меняю 10 инструментов. По малейшему чиху, чуть в ноту не попал. Также и ты.
>>3349289 Так чё там искать, всего 100 вакансий на всю Россию. А там где требуют опыт от 1 года, я очкую откликаться. Мне нужен человечек изнутри, чтоб чётко описал рабочие процессы. Тогда может и удастся наебать систему. Хотя потом чекнут трудовую и ещё посадят за пиздёж.
Ладно. Уже праздники на носу, поздно думы думать. Буду пока линуксы и сети подучивать, чтоб расширить пул вакансий к февральской лавине. Хотя мне БД ближе по душе.
Вот кстати! А что если откликнуться к ним же, но через месяцок и накрутить нууу, скажем, 7-8 месяцев попыта? А чё, вроде уже и не такой пиздёжь получается, т.к. учусь как раз полгода. Ну да, не коммерческий опыт, но практический зато! Всё как они хотят блять.
Главное дойти до тех. собеса, чтоб блеснуть знаниями своими охуевшими. И зп демпить не буду, сразу напишу тыщ 80, чтоб они все там с обалдевшими лицами сидели!!
>>3349309 Ой не пизди пожалуйста. Вакансий не 100, а 344. Сними нахуй все флажки. Сними флажок "без опыта". Сними флажок "стажировка". Удали из поиска все лишние приставки. Оставь только "dba". Вот так и ищи.
Если очкуешь откликаться - то не откликайся. Более борзый чел без задней мысли откликнется, получит твою работу, будет копить опыт, а ты будешь хуй сосать и стесняться дальше.
Требовать они будут на параше. Кто они блять такие, не наняли а уже требуют омегалол. Забудь это слово "требуют". Пока вы контракт не подписали - они просто какие-то левые люди с улицы. Они максимум могут высказывать пожелание.
Повторно откликаться? Да нахуй они нужны! Пошли их нахуй и всё. У них не такая высокая зарплата чтобы ходить унижаться. Если бы у них была 500 тысяч рублей в месяц, тогда это имело бы смысл. А 60к можно заработать курьером или бомбилой, взять шаху и начать бамбить! И не надо проходить никаких собеседований.
>>3349251 DBA полумертвая тема. Или мертвая для вкатунов. На огромный проект дай бог требуется 1 DBA. Иногда такого нанимают просто на аутсорсе. Работа стрессовая, надо чинить базы при падении, восстанавливать всякое говно из бекапов. Пиздец конечно.
>>3348571 >>3268780 (OP) Это нормально что в каждом графике такой пиздорез? + Этот перевод, в англ версии написано простым текстом просто и понятно, а тут нечеловеческим языком. + Гугл переводит так же по-человечески.
>>3349932 Есть форматы хранения строковые, а есть колоночные. Колоночный умеет читает отдельные колонки. С ним можно делать широкие таблицы. Строковый читает по строкам. С ним, в прицнипе, тоже можно делать широкие таблицы, ведь сейчас не 1985 год. Но, возможно, ты захочешь использовать колоночный процессинг для такого. В классичсеких РСУБД обычно принято делать нормализацию данных по модели и использовать join. Что будет работать быстрее - я бы проверял на конкретных примерах. Если данных мало - то "для себя" можешь делать как хочешь, а для кого-то - как "правильно".
>>3349932 It depends. Если у тебя колонки VARBINARY(MAX) и разработчики дебилы с орм головного мозга, то лучше большие колонки вынести в отдельную таблицу, иначе база ляжет на SELECT * FROM table. Если это обычные колонки уровня дата рождения сумма начисления, тогда все в одну.
Если запросы в основном на чтение и схема меняется редко, можно все в одной таблице (меньше джойнов=быстрее чтение). Если схема часто меняется и много запросов на запись, лучше разделить, шоб минимизировать риск аномалий.
>>3349986 >Если запросы в основном на чтение Если он без индекса будет читать, разве не будет замедления от того, что будет читаться вся большая строка и потом из неё выбираться поле фильтрации? А по хешу джойны с маленькими словарями быстро пройдут.
Опять же, в случае денормализованных данных надо обновлять все строки. Недостаточно просто в словаре поменять статус, например - надо во всей базе его обновлять вручную.
>>3349986 >>3349980 >>3349981 Дополняю инфу. XML данных примерно 60 мб, импортируется один раз в год в лучшем случае, но запросы должны на вывод должны работать быстрыми. Никакого ОРМ нет и не будет. Поля текст UTF8 и числа.
>>3349988 Раз у тебя данные редко загружаются, то красиво будет разложить данные по схеме, 3NF или звезда, а потом сделать по ним те же matview с нужными данными под чтение, можно ещё индексы на них накинуть для быстроты.
>>3350582 Ну во первых serial генерится базой. То есть чтобы присвоить идентификатор какой-то сущности в коде нужно сделать запрос в конкретную базу и дернуть конкретную последовательность.
А если эта база на другом сервере вообще? Создавать апи по выдаче идентифкаторов? Использовать временные идентификаторы? Причем идентифкатор нужен сразу, а сохранение данных в базу это вообще последний этап. Не факт что там вообще до сохранения в итоге дойдет.
Сквозной гарантированно уникальный идентификатор, который можно сгенерить вне зависмости от базы, в любой точке кода решает большинство вопросов. Его можно и как ключ идемпотентности использовать и на клиенте генерить. И вообще UUID это тоже число, только большое. Короче WIN-WIN. Serial поля для первичного ключа нахуй не нужны.
>>3350706 Нихуя жирного. Если у тебя базенка на две таблицы, в которую пишут полтора человека в год, оно может и не очевидно что какие-то проблемы могут быть. Но во всех более-менее крпных проектах, которые я видел рано или поздно внедряли UUID'ы.
Пытаюсь создать кластер postgresql в дебиане. Делаю pg_createcluster -u postgres -g postgres -d db-dir -p 1234 17 new_cluster Оно вроде создается, но папка db-dir пустая. Почему там нет кучи файлов конфигов?
Может есть какая то книжка в которой бы был пример как настроить логическую репликацию для serialiazable trtansactions, чтобы они и синькались полностью? Я уже устал доку читать. Я понял, что нужно настроить реплику с sync on, но настраивать заебался.
>>3268780 (OP) Дайте советов мудрых как задрочить SQL, чтобы собесы на раз-два проходить и в работе не лажать? До этого только ковырял ноусиквель бдшки и работал со всякими редисами и прочими монгами
>>3353236 я настроил по гайду индуса с ютуба. когда реплика жива все ок. я уронил реплику, попытался вставить значение в таблицу. вставка зависла, а при отмене вот такое соообщение Cancel request sent WARNING: canceling wait for synchronous replication due to user request DETAIL: The transaction has already committed locally, but might not have been replicated to the standby. COMMIT
И при select я вижу результат. Это не то что нужно. Оно не должно вставлять, если вторая нода не подтвердила получение. synchronous_commit установлен в remote_apply, так что я не понимаю почему он коммитит транзакции. Как фиксить?
Пишут, что нельзя отменить? Чеее нахуй? А смысл тогда синхронных коммитов? Я специально это настраивал на случай, если диск навернется один, чтобы все на втором было.
На какую работу можно вкатиться умея только в SQL-запросы, ну максимум бэкапы/репликацию? Опыта в этой области не было, лишь айтишное образование и скромный опыт работы эникеем. Вакансий с гулькин хуй, непонятно чем там вообще люди занимаются. Вообще сомневаюсь, что это перспективная тема и что я не останусь у параши потратив время и силы на схуэль. Если есть кто опытный - просвятите, как вкатились, какие задачи решаете на работе и стоит ли овчинка выделки.
>>3278398 >где люди так или иначе работают на жирных ноутах и модельки локально обучают Ну я обучал модельку решать капчу, которая генерируется популярным классом для PHP. Но код тормознутый. Соответственно, я у себя на компе запускаю скрипт в PHP CLI в 8-16 процессов, они генерируют пачки, скажем по 1000 капч, потом это все складывается в SQLite, потому что из PHP удобно складывать в него и потому что база хоть и простецкая, но лок поддерживает, можно в нее складывать из нескольких процессов, если не по одной строчке, а пачками. Дальше я выгружаю этот файл SQLite на Google Drive, который монтирую из Colab'а, открываю из питона эту SQLite-базу и обучаю на колабе собственно модельку. мимо шел, не шарю в ваших бдшках на самом деле
>>3278398 >Если же надо большие данные - есть жирные реляционные БД >жирные реляционные БД СУууууука! Аж передёрнуло! Этот кадр вообще видел цены на бд в облаке? Всего-то минимум 5к рупь/месяц плотишь за самый дешманский кластер)))) Я представляю сколько будет стоить ЖИРНАЯ реляционка.
>>3354104 В техподдержку наверное. Ну с айтишной вышкой можешь попробовать dba, думаю шансы высоки найти работу. Правда надо знать немного больше, чем ты написал. Ну ещё можешь в 1С вкатиться, т.к. 1С это по сути тупо sql, но на русском.
>>3354205 Видишь, сычушь, поднять базу через докер ран постгре:латыст это только начало. Ее еще нужно правильно скофигурить и обслуживать. Удачи поднять базюльку на виртуалке, которую тебе потом хэкнут скрипткидди
>>3354205 >А нахуй это надо? Это типа для тех что не в состоянии базу на обычном хостинге поднять? Налог на тупость? А хуле ты думал, все эти dynamodb, и решения типа sqlite на efs - это всё от хорошей жизни? Дохуя таких умных приходят, советы раздают - ну тип прост без задней мысли арендуешь жирную реляционную бд за 100к/месяц и не паришься))) Ого, я даже не знал что так можно! Обязательно воспользуюсь для моего хобби-проекта. Или есть же вот kurwa vps за $1,5 чё ты не пользуешься?))) Ага щаз блять, только перепишу миллион строчек кода и сразу уйду на kurwa vps. Посчитать даже допустим во сколько обойдётся решение на базе polars/dask/ray/duckdb и допустим редшифт или оракл, там цены начинаются от $0.5 в час. Это в районе $360/месяц или $4320/год. И это без учёта остальной инфраструктуры. Одно дело, что etl отработал и ты его удолил, а другое - когда бд всегда висит и с тебя каждый час бабки снимают.
>>3354350 >Нахуя арендовать ДБ? >Дохуя таких умных приходят, советы раздают - ну тип прост без задней мысли арендуешь жирную реляционную бд за 100к/месяц и не паришься)))
Как SAP data services выучить? Первый раз с этим работаю. Могу трогать только на работе, но там уже все настроено, тысячи таблиц, jobs, процессов автоматических настроено и вообще много всего. Курсы какие-то вижу только за тысячи долларов, а на работе приходится что-то там делать, страшно что-то случайно удалить или не то загрузить. В принципе немного потыкаясь понимаю базовый функционал, хочется что-то поглубже, но боюсь учиться на готовой архитектуре уже в продакшене.
>>3355224 При том, что в современном мире админят бд именно девопсы. Девопс это три в одном — разраб, админ бд + админ сервера. Ну ещё иногда выполняет роль надсмотрщика, а ещё иногда бывает занимается не только настройкой мониторинга, но и сам мониторит, потому что работодатель решил сэкономить на инженере мониторинга.
Поэтому девопсы получают сильно выше зп. Так ведь я ещё забыл, что девопсы часто бывают on-call по кд. Поэтому я думаю, что им даже мало платят, должны х2 как минимум платить. То есть грейд синьора должен начинаться от 1кк/мес как минимум!!
>>3355450 Ну пенсионерам придётся подстраиваться под рынок IaaS и переквалифицироваться в DBAaaS. Ещё 2-3 года и усё, пиши прощай, без работы останутся, хех. Я не со зла ведь говорю, а наоборот, дружелюбно предупреждаю.
Это все равно что быть фронтендером из 2005 и фронтендером из 2025 — две большие разницы.
>>3355545 Хуй с яишенкой сравнил. Это две разные профессии. Девопсины вообще кроме ямлов и сетей нихуя не знают. То что сасы услуги бд предоставляют не делает двопсов автоматически дба. Про разделение труда слышал?
>>3355560 Только вот кабану выгоднее нанять тиму девопсов и бОльшую часть задач по DBA спихнуть на облачного провайдера, чем нанимать и 2 тимы: девопсов и дба. Поэтому рано или поздно на всю страну останется 3-4 банка и госухи (зп на уровне кассира, так что даже не рассматриваем как работу), где будут тимы дба отдельные и усё.
Кароче неча тухнуть в своём болоте доисторическом. Надо двигаться вперёд. Ну или побыстрее нафармить себе на хаты и стать рантье!))
>>3355580 Ну если кабан долбаеб и считает что это выгоднее, то это его личные проблемы. Пусть еще к проктологу+стоматологу сходит, чтобы жопу и зубы у одного врача полечить. Выгодно же!
>>3355449 >>3355545 >ASS Справедливо если у тебя базенка с 5 таблами и пишутся туда 2-3к строчек в день. Высоко нагруженный OLTP уже нужно чисто постгрес или другую хуйню тонко настраивать.
А уж про OLAP базы я не говорю. Тот же ванильный гринплам иди подними не в ДЦ, а в облаке. Ага, хуйца соснешь. Так ещё собрать его нужно из исходников и настроить нужно так чтобы не падал.
Анон какой клиент юзаешь?Раньше ставил всегда пхпмаиадмин,тут понял что заебался его постоянно ставить,пердолится с конфигом и конфигом сервера еще.Решил поставить альтернативу и что-то нету ничего годного.ГПТ спросил - хуергу мне насоветовал.Вот смотри скрин.Это лютый пиздец.Кто то кроме меня это запускал?Кажется что даже разраб это не запускает.Сука блядь,антон посмотри на третью строку меню.Блядь,белый шрифт на белом фоне,блядь серый шрифт на сером фоне.Это пиздец.Не нашел как поменять этот всратый внешний вид.Кароче есть че а?
>>3355736 >DBeaver А интерфейс такойж как на пике?Или ты как то поменял? Так то вроде не плохое ПО,все быстро встало и завелось без проблемом.Но шкура у него ,просто иди нахуй сказала.
Прошлый раз я задавал этот вопрос очень давно, я где-то на почте себе пост сохранил и найти теперь не могу. Кажется, если память не изменяет аноны сказали дрочировать до пункта Data Integrity and Security
Как считаете до этого пункта Data Integrity and Security нормально будет?
Мне как нубу не понадабятся на начальном этапе хранимые процедуры и функции?
>>3356244 Я так и знал, что ответа не будет. Всё. Ладно. Буду дрочироваться до пункта Data Integrity and Security. Кажется прошлый раз до этого пункта на двоще сказали. Я просто сохранил текст того поста с ответом, да найти не могу нигде.
>>3356250 Твой вопрос имел бы смысл если бы ты к сертификату готовился, а после получения сертификата тебе было бы похуй что останется в голове. Твоя же задача понимать что ты делаешь когда решаешь задачу, понимать как сделать задачу, как ее декомпозировать на мелкие задачи.
Поэтому тебе надо начать писать код. У тебя не получится. Надо гуглить и снова и дальше писать. Надо постоянно держать в голове решаемую задачу. А не список вопросов которые ты "должен" зазубрить/
>>3356253 Ладно, извините, пожалуйста, просто у меня очко горит, хочу быстрее вкатиться, я ж с 2к16 года начал учить штмл цсс жс вебпук и до сих пор не вкатился. Вот я и подгораю неистово, полыхает у меня. Извините, пожалуйста.
Читаю как работать с JDBC. В доке написано, что если я делал запросы внутри транзакции и у меня вылетело исключение, то мне обязательно нужно сделать явно rollback, потому что иначе не понятно какие изменения были закоммичены. Вопрос - какого хуя? Разве не смысл транзакции в том, что пока я не вызвал коммит, ничего не закомичено? Пока это выглядит так, будто если у меня программа упала во время выполнения транзакции, то дб останется в поломанном состоянии. Или как это работает?
>>3356378 Конечно же, ничего само не закоммитится, если явно не закоммитить (ну или неявно через какую-нибудь спринговую прослойку). Вероятно, там имелось в виду, что надо внимательнее обрабатывать ошибки, вдруг у тебя в методе делается 10 апдейтов, на восьмом апдейте свалилось, но эксепшен по какой-то логике проигнорировался, и часть выполненных апдейтов закоммитится, приводя данные в несогласованное состояние.
As mentioned earlier, calling the method rollback terminates a transaction and returns any values that were modified to their previous values. If you are trying to execute one or more statements in a transaction and get a SQLException, call the method rollback to end the transaction and start the transaction all over again. That is the only way to know what has been committed and what has not been committed. Catching a SQLException tells you that something is wrong, but it does not tell you what was or was not committed. Because you cannot count on the fact that nothing was committed, calling the method rollback is the only way to be certain.
The method CoffeesTable.updateCoffeeSales demonstrates a transaction and includes a catch block that invokes the method rollback. If the application continues and uses the results of the transaction, this call to the rollback method in the catch block prevents the use of possibly incorrect data.
>>3356259 Тебе нужны таблетки от рефлексии, сходи к психотерапевту. Мне помог тритико, я перестал анализировать и рассуждать "а надо ли?" или "другой стек выглядит интереснее... попробовать ли?". Ну и в целом стал немного овощем, что меня на самом деле спасло.
Но кому-то он и не помогал, а только хуже делал. Как повезёт.
>>3356259 >я ж с 2к16 года начал учить штмл цсс жс вебпук и до сих пор не вкатился Когда пишешь реальные сука проекты, с реальными задачами, то учишь только то что нужно здесь и сейчас. А когда ставятся абстрактные цели, то и вкатываются по 10 лет. Давай сегодня криптографию выучим? А, ну давай. Давай сети выучим? Давай. В итоге, учишь учишь учишь учишь, а выхлопа нет никакого. В айти нет недостатка информации, можно бесконечно вариться в каких-то гайдах, книгах, курсах. Но в итоге, у тебя нет ни портфолио, ни проектов.
>>3354205 > поднять базу > поднять зукипер > поднять забикс > настроить алерты > настроить бэкапы > периодически докидывать ноды и ставить обновления > нанять девопса который будет этим заниматься и автоматизировать Если тебе хватает базы в докере, это всё конечно нерелевантно.
>>3356562 А где это все настроено? Че-то есть большие сомнения что за пять косарей, тебе дадут ручного клоуна, который тебе под постгрю зукипер поднимать будет.
Не убедительно, по прежнему звучит ка кналог на тупость.
Добрый день уважаемые форумчане. У меня такой вопрос. Вот читаю я про устройство/различия между Postgres и MySQL. Пишут что раньше (сейчас якобы эта граница фактически нивелирована) Pgs "в основном" применялась для аналитики данных, а MySQL для онлайн транзакций. На чем это основано и в чем принципиальная разница между этими двумя сферами применения? Какие особенности внутреннего устройства/дизайна способствуют этому?(Процессы vs потоки, индексы и т.д.)
>>3357961 Heap-таблицы становятся транзакционными благодаря архитектуре PostgreSQL, которая: — Реализует транзакции через MVCC, сохраняя несколько версий строк. — Использует WAL для обеспечения долговечности и восстановления. — Гарантирует атомарность, согласованность, изоляцию и долговечность (ACID) операций над таблицами.
>>3358737 Одна книга ничего не решает. Даже написанная маэстро. Даже если толстая. Даже если это "всеми признанная классика". Это всё равно одна книга. Чтобы нормально вникнуть в тему, нужно хотя бы книг десять.
>>3358755 Я перед трудоустройством в 2013 г. прочитал 7 книг по теме, плюс не полностью ещё около 10 (вычитывал только нужные темы). Оглядываясь назад, могу сказать, что сделал всё правильно. Работы на тот момент было не так много. Если бы я проебал возможность, то я бы проебал возможность на очень долгое время, а может и навсегда.
Так что советую минимум 5-7 книг прочитать, иначе тебя жестоко попустят высокоуважаемые коллеги.
Приветствую вас Уважаемые Форумчане. Подскажите как лучше реализовать следующий функционал: необходимо выдавать текстовый документ по поисковому запросу. В базу надо загрузить много файлов txt, проиндексировать каждый из них, ну и хранить и выдавать по запросу. Вопрос такой, как хранить сами файлы? 1)OID (я так понимаю это просто ссылки на BLOB), выглядит симпатично. Смущает скудная инфа по тематике в интернетах, что наводит на мысль, что редко применяется. 2)BLOB не вижу разницы разницы с первым вариантом, только лишняя еботня с конвертацией их text --> bytea. 3)ссылки на файл. Пугает ибо кажется будут проблемы с репликацией. Или может я изначально не правильный подход выбрал, тогда как лучше сделать?
>>3268780 (OP) А где ньюфажные вопросы задавать? Ну типа на сколько таблиц дробить запись, чтобы не было повторяющихся полей? Про структуру базы? Как не наступить себе на хуй, если потребуется добавить полей?
>>3358737 Ни насколько, чел. Это вообще не про базы данных. Это такой сборник шизовысеров "по мотивам" и "записки на передовой". Да и в целом книги нужно прорабатывать с составлением конспектов и разбором всех примеров на практике, а не просто читать как художку
>>3359798 Для MVP сойдёт. Как альтернатива JSON/JSONB в постгре.
А для более сложных проектов можно юзать гибрид, когда основные данные хранятся в нормализованных таблицах, а дополнительные (временные, логи) или редко используемые данные хранят в полях типа JSONB. Или вообще в NoSQL базах.
>>3359891 К большому сожалению видел. Я работал на проекте где на eav была построена вся система. Система обслуживала крупные госики и нагрузки соответствующие. Меня заебало делать кеш на каждый чих и я свалил оттуда.
>>3359895 Сам себе может и не плох в качестве доп. инфы, но делать делать точно не стоит, как описал выше. Нейронка не предупредила о рисках. За это большой минус.
>>3359922 Лел, так EAV по определению работает быстрее, чем нормализованная база. Нормализация как раз за счет гарантий консистентности жертвует производительностью. Сдается что ты либо пиздишь, либо это был не EAV.
>>3359532 я сам ньюфаг если что делаю так: - гуглю схемы БД по нужной мне схеме, хуярю код (ORM | Sql) - паралльельно читаю/изучаю теорию (по необходимости)
читать по этой теме (нормализация, оптимизация и т.д.) не практикуясь, так себе затея..
>>3359934 Бля, я секунд десять пытался понять что за хуйню я прочитал. От формулировки, до содержания. Зачем еав будет работать быстрее? Зачем? Его блядь че уговаривать надо? Первая нормальная форма? Она ведь про множественные значения. Еав это третья форма, он соответтвует первой и второй. Долбятся в одну и ту же таблицу? Это че дверь какая-то, в неё долбиться?
А потом я понял что это просто бессмысленный набор слов и со мной произошел пикрелейтед.
Раз уж упомянули гринплам, как правильно в нем с партициями работать?
Вот есть табличка с партициями по дате, я если новую хочу добавить, я должен ADD PARTITION ебануть на эту дату, а потом заливать инсертом данные в мастер-таблицу и оно сам там расплывется или как?
>>3360884 Для джуна вообще хватит уверенного sql/python и знание что такое execution_date в airflow 2.
>>3360861 PARTITION RANGE нет в GP. Поэтому да, сначала добавляешь нужную партицию alter table ... add partition и потом инсерт данных. Возможно у самых новых проприетарных GP есть нормальная работа с партициями. Мы сидим на GP который основан на PostgreSQL 9.6 там все через жопу с партицированием.
>>3360972 >PARTITION RANGE нет в GP. Поэтому да, сначала добавляешь нужную партицию alter table ... add partition и потом инсерт данных Понял, благодарю за ответ.
>>3360972 >Для джуна вообще хватит уверенного sql/python и знание что такое execution_date в airflow 2. ну у вас в жёлто-чёрном явно не так, у вас ДРОЧЕВО ояебу и 100-этапные собесы наверное мимо магистр 1 курс в поисках работы
>>3361157 Лол, вообще я по образованию математик Прикладная Математика и Информатика. Самая ложная математика в DE это расчет времени выполнения запросов в плане запроса. То есть умножение и сложение цифр.
>>3361170 А мы и джунов то не берём. Как то год назад один джун был нужен, помню у него спрашивали только за sql + python. Сейчас берём только мидлов/сеньеров.
>>3361175 Да хз, руководству нужны уже боевые единицы. Нет времени на раскачку обучение джунов.
>>3361186 Конечно же plpgsql. plpython в GP исполняется только на мастер-ноде. Эту ноду очень легко перегрузить в хранилище. Станет узким местом. А вот plpgsql умеет в сегменты. По крайней мере нам так сказал DBA, я не проверял. Да и нахуй не надо.
>>3361313 Ну dba пишут свои процедуры. А мы de - свои. Вот недавно писал для аналитиков процедуру которая 2 таблы сравнивает и выдает подробный результат какие столбцы разошлись.
>пока не сильно Думаешь я сильно? Так по примерам из тырнета пишу, чатгпт иногда привлекаю. Все таки мое основное это петухон. Да и я сеньер, у меня уже задачи где кода меньше. Сходить, узнать, сделать задачу другому отделу, собрать требования, согласовать и т.п. Хиккой не получится быть, надо ебашить в социоблядство.
Не могу людям односложно ответить на вопрос, "кем работаешь?" У меня новая работа, тут занимаюсь налаживанием процессов ETL, автоматизация, разбираю бэкенд в SAP BODS, AWS, клауд миграция, SQL Management Studio, смотрю на кубы в Visual Studio еще делаю дашборды и аппликации в PowerBI и отчеты в Visual Studio. Как бы вы это назвали? DE? DB Administrator? На что больше похоже?
>>3361499 DE. Либо менее употребляемое DBD Database Develop.
Кстати, года так до 2017 в этой стране точно не было определения всеми этому. Кто как называл. Report Developer, OLTP/ETL Developer, SQL Developer. Все это объеденило Data Engineering.
Приветствую вас Уважаемые Форумчане! Вижу, что крупные компании часто используют OracleDb. В чем преимущество этой базы данных для по сравнению, например, с Ps/MySQL? - Развитый процедурный язык PL/SQL - В целом Oracle более надежная, отлаженная и т.д. - что то другое?
>>3362173 Хинты есть которые действительно работают, поддержка от оракла и куча коробок завязана на Oracle DB. Плюс возможности для DBA для той же трассировки.
Ну и раньше до гойды были возможности купить коробку на PowerPC с процессором IBM и операционкой AIX. С уже установленным ораклом. Там на 1 ядро можно было делать дохуялион потоков. Таким образом интелы сосали со своим гипертрейдингом. Оракл мог любой говнозапрос обработать.
>>3362183 > Там на 1 ядро можно было делать дохуялион потоков. как распараллелить бд (прием запросов) на множество потоков? или этим сам Oracle+AIX занимается? к примеру у меня открыт порт. На него хуячат запросы. БД создает поток(MySql/Oracle) или процесс(в Postgres) для каждого запроса? или требуется дополнительное ПО? вы тут пишите про всякие airflow/hadhoop и прочее, это для этого и требуется?
В википедии написано: "Для упрощения тестирования, независимости бизнес-логики приложений от СУБД существует подход, в котором СУБД выступает лишь в роли хранилища, с минимальным количеством хранимых процедур или полном отказе от них". Какая в целом тенденция сейчас? Бизнес-логика описывается на уровне back-end приложения на (python, C#, Go) или основной функционал стараются перенести на обработку самой Бд?
>>3362225 Смари, братиш ёп, сейчас типа в тренде больше вхуяривать бизнес-логику на уровне бэкенда, а базы юзают просто как тупое хранилище данных — так проще масштабировать и поддерживать приложение. Но если у тебя, допустим, хайлоад или нужно жёстко оптимизировать производительность, то логично часть функций перенести в БД: в хранимые процедуры, триггеры и.. короче, всё, что можно выполнить быстрее прямо на стороне СУБД. Такой гибридный подход тоже норм заходит, особенно если данных дофига и их надо агрегировать. Но чисто для общей тенденции — кодить логику на питоне, го, шарпе и т.д. сейчас типа стандарт. Ты, главное, юзай этот подход с головой, а хранимые процедуры оставляй для реально нужных штук, а не ради флекса, понял?
А при чём тут микросервисы? Да при том, что в этой архитектуре каждый сервис отвечает только за одну фичу и может юзать вообще любую базу, хоть PostgreSQL, хоть Mongo, хоть что угодно. Поэтому всю логику фигачат в бэкенд, чтобы сервисы были независимые и могли спокойно масштабироваться. Если бы логику вхуячили в базу, то пришлось бы тащить за каждым сервисом конкретную СУБД, а это ёп костыли и проблемы с поддержкой. Короче, для микросервисов тупая база(когда база используется только для хранения данных, а вся логика обработки и проверки лежит на приложении, без хранимых процедур, триггеров и всяких сложных SQL-фишек) — это вообще мастхэв, а вот в монолите гибридный подход ещё живёт и даже иногда превалирует.
>>3362195 Пердолинг в ssh. Вот буквально сегодня делал rm -rf по определённым файлам с определенной датой создания. Ибо их там дохуя накопилось и админы начали на меня наезжать.
Неделю назад выяснял какие права нужны в линухе, чтобы этот файл можно было удалить, файл создан другим пользователем. Вот кстати, давайте без гугла ответьте, проверьте себя.
Как-то вот вызывал api через bash внутри ci/cd. Навалял небольшой скрипт.
Ещё встречал абсолютно мудацкие интеграции, когда система коннектится по ssh и кладет файл с отчетом. Ебаное Легаси, надо было писать генерацию таких файлов.
>>3362203 Сама по себе лютая БД работает не в однопотоке. Особенно если запрос из 20 джойнов. В каждую таблицу надо сходить, статистику по каждой табле получить, построить план запроса и только потом выполнять сам запрос. В тех же ораклах как то развлекался вставляя хинт +parallel(4) и замерял насолуьо лучше или хуже стало.
Airflow это оркестратор вообще, посредственное отношение к БД имеет. По сути это очень мощный визуальный cron. Hadoop просто один из видов хранилища.
>>3362289 >что думаешь, микросервисы - будущее? или хуйня для усложнения/ухудшения? Микросервисы - это настоящее. БУДУЩЕЕ за НАНОсервисами и ИИ. Деплоится будет не сервис, а одна-единственная функция которая может допустим читать из БД, но не может ничего писать. Это всё будет общаться по шине сообщений, гибко фильтроваться и деплоиться кодом.
>>3362289 Эта хуйня для попильных стартапов, которые никогда не выйдут в прод. Микросервисы позволяют нанимать литерали любых васянов с любым стеком, а не собирать команду полгода. Когда микросервисы попадают на прод, начинаются дичайшие боль и страдания. Посмотри выступления челов с Авито, они сожрали ебаный океан говна.
>>3362225 Современная тенденция писать логику на бэке, так проще отлаживать. Хранимки сейчас - это просто sql, написанный в одном месте, а не размазанный тонким слоем Queryable говна по всему коду. Ты открываешь код хранимки и сразу видишь всю логику. Триггерами не пользуются, а то охуеешь собирать этот пазл.
>>3362447 Амазон огромный, там дохуища всего. Магазин и AWS работают на обычных классических серверах с конкаренси, никто не будет переписывать такие титанические проекты под очередной модный пук.
>>3362233 >>3362233 >>3362233 >>3362295 >Неделю назад выяснял какие права нужны в линухе, чтобы этот >файл можно было удалить, файл создан другим пользователем. >Вот кстати, давайте без гугла ответьте, проверьте себя.
>>3362295 а так ты про командную оболочку, я думал про язык bash я вместо питухона везде bash юзую для абсолютно любой задачи (даже самой изощренной) можно скрипт написать. да синтаксис с ебанцой, но функционал ебейший зато
Нужно отрисовать модель имеющейся БД в MySQL Workbench. Есть тип данных в качестве идентификатора uuid. В воркбенче его нет. Как лучше обозвать тип uuid?
вообщем в последнее время я фулстек-инженер-сделай-то-то. опишу задачу и сразу же как я планирую ее реализовать. Есть Ps-бд, в нее переодически добавляются данные. При добавлении записи напишу триггер, который в случае если (пользователь/время/и т.д.) удовлетворяют условию --> данные заносятся в отдельную таблицу-логов. Затем эти логи в удобоваримом виде нужно захуячить в файл (txt сойдет), чтобы кабанчик в любое время мог их глянуть. Загвоздка(для меня) как логи перенести в файл... Я могу через триггер сразу и в базу и в файл писать? Сам я планирую написать bash/cron скрипт который раз в час будет эти данные из базы вынимать и писать в файл. Так сойдет для сельской местности?
>>3363983 Чел. В постгре есть встроенный механизм логгирования запросов и вообще всего что нужно в файл. Буквально первая строчка в гугле. Какие нахуй триггеры.
Что учить, чтоб работать с sql/бд? Кем вообще можно с нуля стать без вышки и опыта? И чтоб без кодерства как такового. Ну ладно, максимум SQL, но чтоб без настоящих языков программирования.
Как ваще дела обстоят с этим? Конкуренция на уровне QA?
>>3364252 SQL и есть настоящий язык программирования. Тьюринг полный. На нем можно даже 3д объекты рендерить https://dbfiddle.uk/WUAioX22 А если добавить PL/SQL, то вообще все что угодно можно написать.
>>3364310 всё так, аналитик - не инженерная специальность, аналитику платят за знание бизнеса/бизнес процессов, для него SQL это инструмент, а не сфера его деятельности
>>3364329 В целом да. Но как обязательный навык SQL почти всегда. Те аналитики которые не умели в SQL это прям жалкое подобие недоспецов. Видел таких, которые знали предметную область, но банально не умели в элементарные запросы.
>>3364548 Нужно для анализа разных выборок, когда одного фиксированного условия нет, и сидишь, комментируя однострочными комментариями пару десятков условий, записанных через AND. В приложении, конечно, смысла в этом ноль.
>>3364310 >Чистый SQL это аналитика только. Чем вообще эти аналитки занимаются? Вот реально кабанчик сидит и принимает стратегическое решение о развитии бизнеса на основе анализа данных? Типа на собрании, кабанчик встает такой: "Сегодня Аналитик предоставил отчет где видно, что продажи товара N упали на 30%. Значит надо инвестировать в рекламу! Спасибо тебе аналитик, будешь премирован!" Обычно бизнесмены (средний точно) и так в курсе как идет их бизнес без всяких аналитиков.
Понятно, что в каком-нибудь крупном бизнесе (банк или сеть шаурмичных) это еще востребовано.
>>3364757 > Вот реально кабанчик сидит и принимает стратегическое решение о развитии бизнеса на основе анализа данных? Абсолютли. Особенно в крупных компаниях. Ещё есть такое понятие как Data Driven Organisation. Все решения должны быть на основе данных, а не потому что у манагера-самодура пятка зачесалась.
> "Сегодня Аналитик предоставил отчет где видно, что продажи товара N упали на 30%. Значит надо инвестировать в рекламу! Если серьезно, то именно так и происходит. Когда в коллекшене банка работал, то делал отчётность по эффективности отделов. Им за мои отчёты вставляли пиздов. Типа тут хули так мало, а тут вообще пиздец? Стратегическое видение тоже должно быть подкреплено данными.
> Обычно бизнесмены (средний точно) и так в курсе как идет их бизнес без всяких аналитиков. ИП Кабаны даже смотрят метрики если они есть. И отчёты по выручке той же. Считают чистую прибыль все кто хочет управлять.
>>3364548 На самом деле у тавтологии есть полезное применение. Это такой способ сказать "ну или не делай ничего".
В этом примере https://dbfiddle.uk/yR14AVU7 анон просил функцию, которая может принимать null, но возвращать при этом нормальный результат.
Если в функцию приходит null, получается выражение c.email = c.email , оптимизатор распознает тавтологию, отбрасывает условие фильтрации и выводит весь список.
>>3366044 В этой стране сертификаты признаются только в госконторах, где бумажки всегда в приоритете над реальными умениями. Получил вышку - молодец, вот тебе 40к, закончил магистратуру - молодец, вот ещё 20, получил сертификат из утверждённого списка - ещё плюс 10, можешь гордиться зарплатой 70к до вычета. А в остальных компаниях без разницы, где ты обучался, лишь бы умел хорошо делать рабочие задачи.
>>3367811 Очевидно что ты пишешь какую-то микро хуйню. Писал бы настоящие мощные пятиэкранные запросы, которые выполняются по несколько часов - умер бы от недостаточного поступления крови в мозг.
читал тут статью про Hash Join, в целом все понятно, но смутил комментарий под статьей: "Мораль сей басни такова: не пытайтесь угадать, хватит ли памяти под хэши. Нужен быстрый и частый join по полям, особенно текстовым? Сделайте отдельную колонку с хэшем. Ну а если не частый - хотя бы CTE с хэшем."
как это будет работать? Ведь функция-хеширования выдает индекс для bucket (в случае хеш-таблиц). Вот есть у меня таблица с текстовыми полями, другая тоже. Если я создам отдельный столбец хешей для каждого из текст.значений, то все равно это будет рандом и всю таблицу придется один хер последовательно сканировать в случае JOIN.
Аноны, подскажите. Будет ли разница в производительности между этими двумя запросами, при условии что джоинов у меня не 2 как в примере а штук 10?
select from t1 left join t2 on t1.id = t2.par_id and (now() between t2.start_dt and t2.end_dt) left join t3 on t1.id = t3.par_id and (now() between t3.start_dt and t3.end_dt)
with now_time as ( select now() as nt ) select from t1 left join now_time nt on true left join t2 on t1.id = t2.par_id and (nt.nt between t2.start_dt and t2.end_dt) left join t3 on t1.id = t3.par_id and (nt.nt between t3.start_dt and t3.end_dt)
Т.е. я хочу чтобы now() вызывался 1 раз, вместо n-ного кол-ва раз. Или оптимизатор в любом случае оба запроса поймёт одинаково и разницы не будет?
>>3369659 Ты бы лучше думал как от лефт джойнов избавиться. Я бы сделал что-то вроде: SELECT FROM t2 WHERE par_id IN(t1 ids...) and (now() between start_dt and end_dt) UNION ALL SELECT FROM t3 WHERE par_id IN(t1 ids...) and (now() between start_dt and end_dt) А дальше или: GROUP BY par_id или INNER JOIN t1 или вместе. Главное избежать наматывания LEFT JOIN'ов. У тебя же выборка в геометрической прогрессии растет. Одна исходная строка умножается на строки в первом джойне потом умножается на строки во втором джойне. Некоторые ОРМ, которые все таблицы через LEFT JOIN объединяют, уже на пятом джойне могут выборку в несколько гигабайт дать.
>>3369659 этот анон прав для твоей задачи лучше использовать UNION. плюс для эффективной работы JOIN тебе необходимо грамотно подобрать индексы для столбцов слияния. Судя по всему на примере твой задачи Ps будет использовать nested loops (алгоритм вложенных циклов) для каждого соединения.
P.S. сам только вкатываюсь, но уже хочу выступать в роли эксперта.
у меня есть две простых одинаковых тестовых таблицы(TAB1, TAB2) на 100 000 строк каждая. TAB2 содержит внешний ключ на TAB1 по столбцу id. create table TAB1(id SERIAL PRIMARY KEY, b text, c boolean); create table TAB2(id FOREIGN KEY (a) REFERENCES TAB1(id), b text, c boolean); Опыт №1 заполняю все столбцы обеих таблиц рандомным/неупорядоченными значениями. Делаю JOIN оптимизатор выбирает NESTED LOOPS. Опыт №2 теперь заполняю id в обеих, упорядоченными значениями(1,2,3,..) делаю JOIN ON TAB1.id = TAB2.id оптимизатор применяет уже HASH JOIN, хотя по теории и как я ожидал он должен делать MERGE JOIN. Почему так? для опытом использовалась СУБД PostgreSQL
>>3370413 Все я понял. Создай таблицы и напиши запросы в фиддле, и тогла вместо твоих охуительных историй все смогут увидеть реальный эксплейн и написать тебе нормально правильный запрос, который гарантированно делает то что нужно. Вместо того чтобы работать в ебаной угадайке хиромантом.
>>3369917 хз, сейчас очень много желающих вкатиться, на вакансии джунов каждая мелочь может сыграть значение. И я не думаю, что вышка такая уж мелочь, на которую не обращают внимания.
>>3370525 Помню когда устраивался на текущую работу принес им копию своего диплома бакалавра, ибо оригинал был в универе. Я тогда в маге учился.
Через год получит диплом маги. Спрашиваю, ну шо а диплом диплом магистратуры вам нужен? А мне хрюша говорит: а зачем? Я в ахуе был. Крупный банк если что.
приходиться ли вам работать с таблицами от 1млрд. записей? если да то можете привести примеры? и еще вопрос, какой средний размер таблиц вам встречается на практике?
>>3372083 я почему спрашиваю, сам вкатываюсь в БД (из другой сферы) сейчас тестирую (параллельно читаю теорию) через EXPLAIN различные запросы: индексация, join и т.д. но использую для опытов маленькие БД на (100 000 x 12 байт словно). вот чтобы максимально видеть как это происходит в реальности, хочу имитировать реальные (условно) бд
Прочитал тред по диагонали. Подскажите плиз, спросить больше не у кого.
Я простой экономист, делаю маленькие селекты на sql server. У меня не то чтобы много свободного времени, да и скрипты на sql это в целом 5% моего времени. Просто есть рабочий кхд, на котором можно тренироваться. Какие курсы/учебники я могу подрочить, чтобы выжать из sql server максимально много.
Чисто программистские роли мне не интересно. Просто хочется писать скрипты круто. Мой текущий уровень - базовые джойны, cte, tvf.
Вот 10 лет лет в БД, а чисто по аналитическим SQL не одной книги не назову. Лично я навык запросов надрочил когда отчёты разрабатывал пачками в неделю. Тупо практика и разные задачи. Там же на практике обучился оптимизации.
>>3374090 >оптимизации как это делается? типа как тут анон выше писал. вместо накрутки джоинов использовать UNION where. Но условно такой подход не для всех таблиц применим. Или это больше про хинты? Можешь привести пример из практики
>>3374805 Самое распространенное если у тебя много сложных cte/подзапросов сделать из них временные таблицы. Можно в целом даже постоянные сделать и на основе этих таблиц уже посчитать то что тебе нужно.
Вообще нужно план запроса смотреть. А там уже определять где у тебя отстаёт. Но достаточно базу знать: меньше left join, больше временных табл вместо подзапросов, оконные функции замедляют запросы. Ну и порядок джойнов сначала джойнишь из больших табл и далее меньше. И не забывай про индексы и партиции, если они есть.
Читаю статью из wiki(ru) про OLAP "Например, все клиенты могут быть сгруппированы по городам или регионам страны (Запад, Восток, Север и так далее), таким образом, 50 городов, восемь регионов и две страны составят три уровня иерархии с 60-ю членами. Также клиенты могут быть объединены по отношению к продукции; если существуют 250 продуктов по 20 категориям, три группы продукции и три производственных подразделения, то количество агрегатов составит 16 560 (????). При добавлении измерений в схему количество возможных вариантов быстро достигает десятков миллионов и более."
как они получили число 16560? агрегат это же все по чему мы можем объеденить кол-во (продукт категории etc)
>>3374090 Понятно. Ну ладно, я просто думал можно будет какнибудь задоджить трату 10 лет( спасибо, что поделился ресурсом, посмотрю
>>3374803 ну вот например, я комментарии почистил и чуть сократил
create or alter view dm_deposit_effrate_catalog as with t as ( select distinct tehproduct, period_interest from [staging_area].[dbo].[bnkdeposit] where period_interest is not null and period_interest != '0' and len(period_interest) - len(replace(period_interest, '^', '')) > 1 ), t1 as ( select row_number() over (partition by tehproduct, period_interest order by (select null)) as rn, tehproduct, period_interest, value as staging_value from t cross apply string_split(period_interest, '^') ), t2 as (select tehproduct, period_interest, case when rn % 2 = 1 then cast(staging_value as float) end as days, case when rn % 2 = 0 then cast(staging_value as float) end as rate, rn from t1 ), t3 as (select t2.rn, t2.tehproduct, t2.period_interest, t2.days, lead(t2.rate) over (partition by t2.tehproduct, t2.period_interest order by t2.rn) as shifted_rate from t2 ), t4 as ( select tehproduct, period_interest, days, shifted_rate from t3 where days is not null and shifted_rate is not null ), t5 as (select tehproduct, period_interest, sum(days * shifted_rate) / sum(days) as effective_rate from t4 group by tehproduct, period_interest ) select distinct t4.tehproduct, t4.period_interest, round(t5.effective_rate,4) as effective_rate from t4 join t5 on t4.tehproduct = t5.tehproduct and t4.period_interest = t5.period_interest
>>3374896 Мне вот всегда интересно было, почему как доходит до базы на людей нападает какая-то ебанутая дизлексия. Они как будто соревнуются как бы по ебанутее назвать колонки и таблицы. Ну какой нахуй period_interest? Какой нахуй rn? Ну тебе самому не впадлу разгадывать эти ебаные шарады в виде т3?
Вот с этого >when rn % 2 = 1 then cast(staging_value as float) end as days >when rn % 2 = 0 then cast(staging_value as float) end as rate я просто охуел.
Короче прото бля земля пухом тому кто попытается разобраться в этой хуите. Я хуй знаю для кого это написано, но не для людей точно.
>>3375080 дядь, ты таблетки забыл принять или чего? во-первых, я написал, что сократил и убрал комментарии, у меня все расписано, что какая строка делает, да там впринципе и так понятно во-вторых, меня специально никто ничего не учил писать, я только книжки читал в-третьих, если ты не понимаешь, может это из-за того, что ты неочень? конкретно это место, разбивает по rn символы из period_interest между знаком ^, чтобы я мог отдельно взять дни и ставку и потом нормально посчитать эффективную ставку в-четвертых, ну если ты знаешь как правильно надо делать, почему вместо попыток обосрать свои штаны, ты не скажешь, как правильно надо делать? в-пятых, я не путаюсь в-шестых, я не программист в-седьмых, я с телефона писал
>>3375208 >period_interest >staging_value Ты в реале такими же фразами общаешься? И таблицы в базе у тебя тоже "т3" называются? Я даже спрашивать не буду какого хуя в одной колонке куча какого-то говна, которое парсить надо.
Причем тут программирование вообще? У тебя проблема назвать вещи своими именами? dm_deposit_effrate_catalog у тебя кто-то буквы спиздил что-ли? Причем там походу вся база такая. Сначала угадай по названию поля нахуй оно надо, а потом охуей от того что там в действительности лежит.
>>3374896 ну если в среднем ты тратишь 5% времени на это и нет желания задачки щелкать читай про индексы и оптимизацию запросов на том же хабр там много (уже) циклов статей про это, но на примере Postgres... так же есть статьи по администрированию и прочее
вы для всех таблиц создаете кластерный индекс? если не для всех то по какому критерию определяете, что для это таблицы нужен класт.индекс, а не просто btree? я так понимаю, что если таблица в осоновном служит для чтения данных, то можно ее "кластериозовать". если транзакционная таблица (много вставок, удалений), то достаточно будет какого-нибудь некластерного индекса (btree, hash etc.)
самофикс понял, что вопрос не совсем корректный. как я понимаю такие БД как MySQL и MS Server автоматически кластеризуют таблицу, как правило по первичному ключу в то время как Ps фактически не поддерживает кластерный индекс
>>3378564 ну как минимум для более быстрого чтения данных. Например в MySQL (InnoDb) по умолчанию данные кластеризуются (хранятя в btree кучками вместе с индексами).Сами индексы и данные будут храниться вместе на диске (в Ps наоборот отдельно). Это как минимум увеличивает кол-во чтений с диска при обращении к данным. В PostgreSQL по умолчанию данные хранятся в Heap (упрощенно плоский список, строки друг за другом подряд в файле).При необходимости можно кластеризовать таблицу ручками, но при добавлении новых они уже не будут кластеризоваться по индексу. Значит опять надо это делать самому или через cron. P.S. если, что я только сегодня про все это читал. Так что лучше сам изучи тему, я могу ошибаться.
>>3379040 Если есть Airflow то тебе надо понять суть что такое execution_date. Как оно работает. Как следующая дата выставляется. Как работают даты в airflow вообще на разных градации: час, день, месяц.
Если есть Greenplum то разберись с дистрибуцией. Heap, AO. Партиции. Хранилища вообще строятся через жопу, без индексов, без not null.
Есть есть Hadoop то почитай про файлы. Про внутреннее устройство кластера.
>>3379040 был в такой ситуации вкатился на работу с нулевым опытом, сразу на мидла++ совет дам тебе один только один: Сразу ставь себя в коллективе как положено! кто будет выебыватся, дерзи в ответ, хоть это и лид/ген.дир, похуй. по факту это никак не повлияет на тебя (внезапно!). потом тот же лид подходил извинялся и все уже было норм. но будешь давать макать себя, тебя будут макать всю дорогу и с зп тоже макать. Успехов!
>>3379040 Тебе будут много всякого объяснять, веди записи в нотпаде. Это тебе в моменте будет казаться, что это ерунда и ты все запомнишь. Нихуя. А потом, если будешь переспрашивать - это будет только всех бесить.
>>3379040 все будет хорошо. первые два дня самые тяжелые но главное не забудь в пятницу проставиться! не скупись на поляну, если че домашнее нормальное неси.
Крутил рулетку 1С, DBA и DevOps. Выпало 8 раз подряд DBA и после этого 1 раз DevOps. Ну на самом деле я хотел до 3 крутить. Потом ради интереса крутил - подумал, может баг какой, но нет.
В общем, буду вкатываться в DBA. Даю себе ровно 5 месяцев - до середины лета. Если я low-iq-лох, то так тому и быть — я приму этот факт и пойду работать на дноработу.
Я пишу это, чтобы весь мир знал о моих намерениях!!! Ну и ещё обоссыте, если не трудно. Хотя ладно, не надо. Во мне больше нет сомнений. Но если хотите, то пишите, что вздумается. Хотя можете не писать, я сюда снова зайду только через 5 месяцев. Но если хотите, то пишите, я вас не останавливаю. Вопрос лишь в том, хотите ли вы тратить время на сообщение, которое оставят без ответа? То-то и оно! Вдумайтесь!
Гопота настаивает, что DROP COLUMN foo - это жирная O(n) операция, требующая эксклюзивный лок на всю таблицу. Тем временем в мане постгреса по ALTER TABLE написано вот это: >The DROP COLUMN form does not physically remove the column, but simply makes it invisible to SQL operations. Subsequent insert and update operations in the table will store a null value for the column. Thus, dropping a column is quick but it will not immediately reduce the on-disk size of your table, as the space occupied by the dropped column is not reclaimed. The space will be reclaimed over time as existing rows are updated. Нихуя не понимаю, где правда.
>>3381439 Правда в том, что тебе это не нужно знать, пускай ИИ за тебя всё решает, он же тебя и заменит одним из первых. Просто представь своё ебало, ты не веришь ОФИЦИАЛЬНОЙ ДОКУМЕНТАЦИИ и переспрашиваешь у какого-то бота.
>>3382143 Ну откуда-то же он это взял. Кроме того, из доки это тожн неочевидно - операция, пробегающая по всей таблице, тоже может быть "быстрой", если у тебя там баснословные сто тыщщ записей и кто-то дёргает её аж целый раз в секунду - это вообще относительное понятие. А как это работает под капотом остаётся только догадываться - исходники постгреса не смотрел, да, и не пизди, что ты их смотришь каждый раз, когда возникают вопросы.
У меня сейчас выбор: после универа пойти работать в гос НИИ со средней зарплатой, но где всем пофиг что ты делаешь или через стажировку в банк, где, как я понял из треда, тебя будут выматывать постоянными созвонами и дедлайнами, но будут много платить. Что посоветуете? Есть аноны кто работал в около гос секторе?
>>3400146 Хотел предложить банк, но после того как увидел слово стажировка фу, нахуй! могу посоветовать только НИИ. Поработай там, наберись опыта и стажа. Потом иди в частный сектор.
сап двощ, че какие варианты развития в сис. анале есть? сам рн мидл сис анал. По стаку питон, сиквел, пост, рест, могу в баш чуть чуть, раст+го учу. Ща миграцией одной хуйни занят на другую хуйню.