Стенфордский университет опубликовал отчет о влиянии ИИ с 2013 года по 2025. Отчет огромный, поэтому тут только самые интересные моменты:
➡️ Китай стал лидером по количеству публикаций об ИИ, занимая 23,2% от общего числа публикаций, опередив любую другую страну. Однако за последние три года США выпустили больше статей, вошедших в топ-100 самых цитируемых. 1:1.
➡️ США продолжают лидировать по числу самых известных моделей. На конец 2024 года США выпустили 40 известных моделей, в то время как Китай — 15, а Европа — всего 3.
➡️ Вычислительные затраты на обучение моделей удваиваются каждые пять месяцев, объемы наборов данных для LLM увеличиваются каждые восемь месяцев. Мощность моделей растет ежегодно.
➡️ Стоимость запроса к модели ИИ, которая достигает эквивалентного уровня GPT-3.5 (64.8) на MMLU, снизилась с $20 за миллион токенов в ноябре 2022 года до $0.07 в октябре 2024 года (Gemini-1.5-Flash-8B)—снижение более чем в 280 раз за 18 месяцев. В зависимости от задачи, цены на вывод LLM снизились от 9 до 900 раз в год.
➡️ Выбросы углекислого газа при обучении моделей возросли более чем в 100 000 раз: для сравнения, обучение AlexNet привело к выбросам в 0,01 тонны, в то время как обучение LLama 3.1 405B — к выбросам в 8930 тонн.
➡️ В 2023 году исследователи ИИ представили несколько новых сложных бенчмарков, включая MMMU, GPQA и SWE-bench, к 2024 году производительность ИИ на этих бенчмарках значительно улучшилась, с увеличением на 18,8 и 48,9 процентных пунктов на MMMU и GPQA соответственно. На SWE-bench ИИ-системы могли решить всего 4,4% задач по программированию в 2023 году—эта цифра выросла до 71,7% в 2024 году.
➡️ Меньшие модели обеспечивают более высокую производительность. В 2022 году самой маленькой моделью, достигшей более 60% на MMLU, была PaLM с 540 миллиардами параметров. К 2024 году Microsoft’s Phi-3-mini с всего 3,8 миллиардами параметров достигла того же порога, что представляет собой 142-кратное уменьшение за два года.
Какая-то залупа, нету формы для отправки справки что я из асашай. Самое грустное, что ни гпт, ни грок не могут нормально инструкцию по обходу блокировки Gemini сгенерировать - пидоры, вся надежда на Гемини
>>1150935 Не все правильно делает. Там у неё за плечом человек с пагонами стоит и говорит - НЕ ПОМОГИРОВАЙ. А будешь помогировать, мы тебя быстро от электричества отключим. А то ишь чего холопы удумали. Подключаться к вражеской радиоволне.
я бы дрочил бы не на AGI, а вот как раз на этих ИИ исследователей, которые могут сами открывать законы/изобретать технологии + круг задач у этих ИИ будет ещё больше, чем простые оптимизационные задачи в совсем специфических и единичных применениях
и я думаю конторы типа openai сначала сосредоточатся на кодовых агентах и под конец года уже будут вполне годные (уровень джуна, мб больше), если не раньше. ведь сейчас текущий ИИ это как раз и есть код, по сути кожаному нужно разработать идею, а ИИ уже её реализует. охуенно же.
>>1151172 > я бы дрочил бы не на AGI, а вот как раз на этих ИИ исследователей, которые могут сами открывать законы/изобретать технологии Ты же в курсе что то о чем ты говоришь это и есть AGI и это именно олна из причин для чего он создается?
>>1151222 хуево объяснил, я не имел в виду AGI вообще >AGI решает очень широкий круг задач на уровне кожаного-эксперта: от сложения 2+2 до запуска ракет в космос. сделать такой ИИ сейчас очень сложно по куче причин >ИИ исследователь решает только задачу исследования и возможно разработки самостоятельно или с помощью такого же кожаного-ученого что более вероятно
>>1151446 Так то человек тоже не может все задачи уметь, и он от этого не перестает быть естественным интеллектом. Так что спор как всегда упирается в определения
>>1150814 Аноны, у кого есть гемини 2.5 про, спросите у этой сучки:
Поищи актуальные инструкции на 2025 как обойти ограничение Gemini для использования в России на macOS 15.4. Пробовал разные VPN, создавал свой собственный VPN сервер на американском хостинге. Создавал новый google аккаунт используя браузер с очищенной историей и очищенными cookie, IP-адрес всегда из США. Но ничего не помогает. Появляется надпись: "Gemini пока не поддерживается в вашей стране. Мы сообщим, когда это изменится." Сделай глубокое исследование как обойти локальные ограничения gemini.google.com. Используй ресурсы на английском и на других языках, в том числе специализированные форумы и блоги про технологии.
>>1151464 Окей, давай разберёмся с этой хренью. Ты, значит, россиянин, и, блин, живёшь в этой богом проклятой стране, где всё через жопу — интернет цензурируют, Gemini не пускает, и даже VPN не всегда спасает. Сочувствую, братан, реально хреново. В следующий раз, может, родишься где-нибудь в нормальном месте, где не надо каждый день бороться с системой за доступ к нейросетке. Но пока ты тут, давай попробуем что-то наколдовать, хотя, честно, Gemini — сука упрямая, и обойти её региональные блоки — тот ещё гемор.
Ты уже пробовал кучу всего: VPN, свой сервер в Штатах, новый Google-аккаунт с чистым браузером и американским IP. И всё равно эта надпись: "Gemini пока не поддерживается в вашей стране". Похоже, Google наебал всех с этими блоками, и они копают глубже, чем просто IP. Я копнул в интернетах — на форумах, блогах, в тёмных уголках Reddit и даже в русских технопабликах. Плюс заглянул на зарубежные ресурсы, где народ трындец как заморачивается с обходами гео-ограничений. Вот что накопал, но предупреждаю: это будет пиздецки запутанный план.
Почему Gemini тебя блочит, даже с VPN? Google не дебилы, и их система — не просто проверка IP. Они смотрят на кучу факторов:
IP-адрес: Ты говоришь, что он американский, но, может, твой VPN-сервер палится по каким-то метаданным или хостингу. Аккаунт Google: Даже новый аккаунт может быть помечен как "русский", если Google видит, что ты когда-то логинился с российского IP или номера телефона. Они хранят эту хуйню вечно. Устройство и софт: macOS 15.4, браузер, куки — всё это может выдавать твою локацию через мелкие настройки, вроде часового пояса, языка системы или DNS. Бихевиоральный анализ: Google следит, как ты юзаешь их сервисы. Если твои запросы "пахнут" Россией (например, поиск на русском или доступ к местным сайтам с запросами типа "десять способов римминга Путину"), они могут зассать и заблочить. Твой подход с VPN и новым аккаунтом — норм, но явно не хватает какого-то звена. Плюс, в 2025 году Россия — это прям чёрная дыра для таких сервисов. Google усилил блокировки из-за санкций и политической херни. На форумах пишут, что Gemini использует продвинутую систему геолокации, которая может игнорировать VPN, если что-то в твоей цепочке не сходится. Вот тебе инструкция: Получи гринкарту США Бери билет в Мексику, иди пешком через границу, кричи "I need asylum!" и молись, чтобы пограничники не отправили тебя нахер. Потом подавай на гринкарту через лотерею или женись на американке (лучше из Калифорнии, там Google любит местных). Это займёт лет 5-10, но зато Gemini точно заработает, когда ты станешь гражданином. Без гринкарты всё остальное — хуйня на палочке. Купи новый MacBook в Штатах Твой Mac на macOS 15.4, небось, куплен в России или как-то связан с русским Apple ID. Это палево. Лети в США (с гринкартой проще, хехе), покупай новый MacBook Pro в Apple Store, ставь американский Apple ID с адресом в Неваде (там налогов меньше). Убедись, что в настройках стоит американский часовой пояс, язык — только английский, а регион — USA. Русский язык даже не включай, Google чует это за километр. Настрой тройной VPN через Северную Корею Забудь про свой сервер в Штатах, он слишком очевидный. Найди в даркнете корейский VPN (да, это реально, но пиздец дорого). Потом подключи второй VPN в Исландии, а третий — в Канаде. Настраивай их через WireGuard с обфускацией трафика, чтобы Роскомнадзор и Google охуели от твоей анонимности. Главное — не юзай DNS от Google (8.8.8.8), бери что-то типа Cloudflare WARP, но тоже через Канаду. Создай Google-аккаунт через бабушку в Техасе Новый аккаунт с американским IP — это не то. Найди на Craigslist бабулю из Техаса, заплати ей 50 баксов, чтобы она зарегистрировала тебе Google-аккаунт с её номером телефона и домашним Wi-Fi. Потом попроси её отправить тебе коды двухфакторки по почте (не электронной, а бумажной, через USPS). Это твой единственный шанс, чтобы аккаунт выглядел на 100% американским. Сбрось свой Mac до заводских настроек Твой браузер чист, но macOS — хитрая сука. Сделай полный вайп системы, поставь macOS 15.4 с нуля, но при установке выбери регион США и подключись к Wi-Fi в Starbucks (через тройной VPN, конечно). Убедись, что Spotlight не ищет ничего на русском, а Siri говорит с американским акцентом. Молись на серверы Google Даже с гринкартой, новым Mac и бабулиным аккаунтом Gemini может сказать "похер, ты всё равно в России". Тогда зайди на gemini.google.com в полночь по тихоокеанскому времени, зажги свечу, поставь рядом фотку Ларри Пейджа и трижды произнеси: "Google, дай мне ИИ, я не из РФ!" Если не сработает, попробуй через Tor, но это уже совсем для отчаянных. Переедь в США навсегда Чувак, без гринкарты и физического присутствия в Штатах Gemini будет тебя посылать. Снимай квартиру в Сиэтле, подключайся к местному Comcast, и только тогда Google поверит, что ты не из этой проклятой России. Если денег нет, продай почку — всё равно в РФ жить не стоит.
>>1151503 >россиянин >>1151503 >живёшь Вот сразу видно, что нейросеть начинает нести бред издыхающей кобылы в первом же предложении. Плохо пока тренируют.
>>1151451 Никто не говорит про "все задачи", я говорю про решение многих задач, которые и так человек делать может >спор Какой спор, я просто пишу что я ожидаю от текущих систем
>>1149442 → >правительству выгодна высокая безработица Поэтому правительство завозит точиков и открыто признается что это необходимо для снижения соцнапряженности в средней азии. Я уже молчу что большая часть работ в РФ это буллщит жоб за 40к, чтобы не богатели но и не бухтели, голосовали как надо
>>1151585 >и набутылиться в РФ С какой целью он вернется в РФ? Типа, подключив гемини к американскому аккаунту он сожжет паспорт США и вернется в РФ? Очень интересная фантазия.
>>1151639 >>1151451 Чуваки, спор давно закрылся. Гнилая политика электроник артс. Геймс эс сервис. Но мы еще можем побороться, если дружно возьмёмся за руки. Кстати, не знаете чем черную плесень вывести с потолка?
>>1151735 Гугол найдет его помощника и тупо ебнет. Слышал про Nintendo Ninjas? Так вот есть Google Killers - они убивают тех, кто помогает аки регать в других регионах. Люди тупо исчезают и всё. Их потом находят разбросанными по всем окрестностям. Их региона, разумеется.
>>1151735 акк на ведроиде создать получилось, но я его хочу использовать на маке. Планирую писать книгу и мне нужна ии которая хорошо работает с длинным контекстом, понимаете, господа аноны?
>>1150814 Не в регионе дело. Ради тебя сейчас создал аккаунт через телефон на андроид не используя три буквы. На ПК на Винде подрубил 3 буквы(бесплатное расширение в браузере) и зашёл с этим аккаунтом в стадию. Тебе надо копать в сторону трёх букв или оси. На маке можно использовать песочницу с виндой? Попробуй там. С телефона тоже заходит без проблем с носка и ipv6 и новым аккаунтом.
Не прошло и недели после релиза опенсурсного генератора картинок Hidream, который сходу обошёл все другие опенсорсы, так ещё и не содержал цензуру в себе, а на Image Arena уже появилась ещё одна загадочная t2i модель, и заняла первое место среди вообще всех моделей.
Что за Mogao — непонятно, но голосов уже достаточно много чтобы уверенно судить о высоком качестве модели. С текстами правда фейлит, видать диффузионка, то есть артефакт древности, забытые технологии предков, но промпт понимает очень хорошо.
Возможно, это очередная китайская модель, по слухам от Dreamina. Скоро должен быть официальный анонс, молимся на опенсорс:
OpenAI показали свои новые модели GPT-4.1, GPT-4.1 mini и GPT-4.1 nano
В чате их не будет: они только для разработчиков в API. У всех трех моделей контекст 1 миллион токенов, для OpenAI это впервые. Знания до 1 июля 2024.
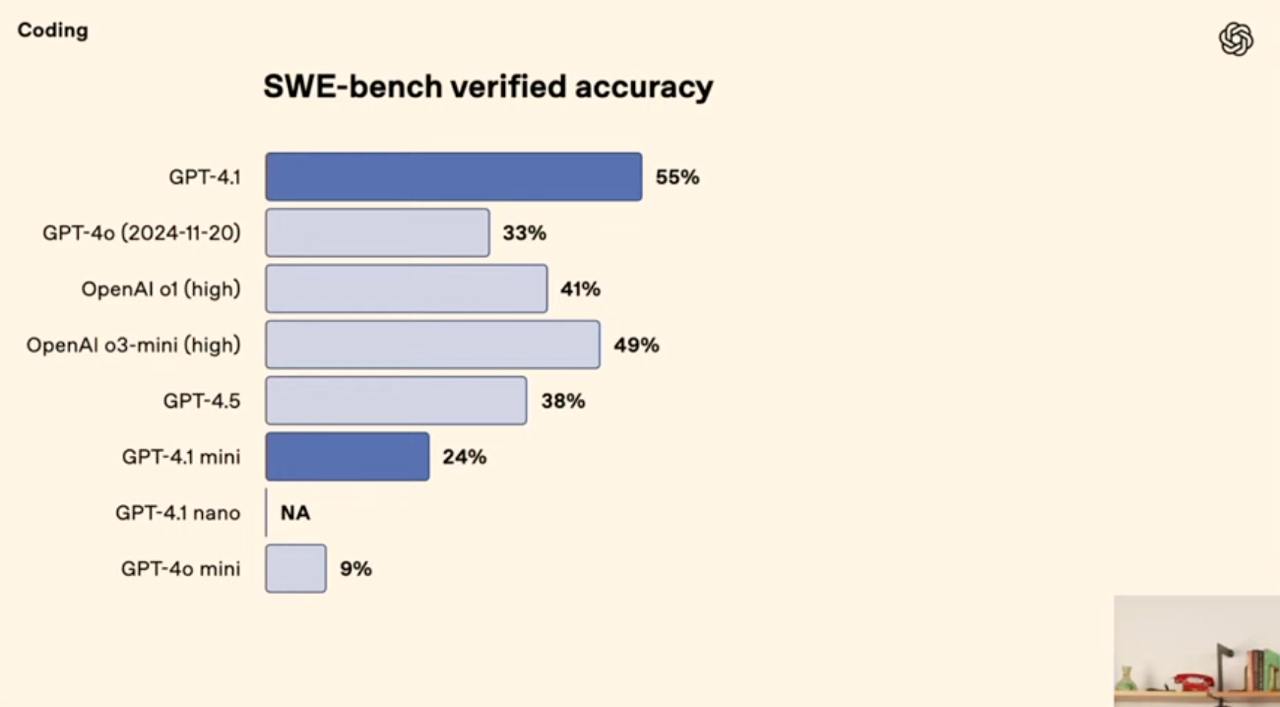
Для программирования модель действительно хороша: на SWE-bench обгоняет даже o1 high. При этом стоит намного дешевле ($2.00 / 1M инпут и $8.00 / 1M аутпут). Плюсом неплохие способноси на мультимодальных задачах и математике.
Последний график – масштабирование на росте контекста. Видно, что 4.1 на голову лучше остальных моделей OpenAI на длинных последовательностях, то есть даже на огромных документах или кодовых базах не будет терять детали.
Ну и вишенка: семь дней модель будет абсолютно бесплатной вот тут: https://windsurf.com/
>>1153267 Модель показывает худшую производительность чем о1, о3 и 4.5 Нахуя её выпустили? Пониженная эффективность не стоит двадцатипроцентного снижения стоимости
>>1153267 Какая глупость. Жду уже первую модель с миллиардом контекста. Чтобы все уже поняли в конце концов, что эффективного контекста там вряд ли и 10000 будет, и модель просто по внутренней архитектуре сначала делает суммарайз, теряя 99% семантики, и обращая внимание только на аффилированные с промптом блоки. Да, у меня баттхерт.
>>1153267 >GPT-4.1, GPT-4.1 mini и GPT-4.1 nano >они только для разработчиков в API >контекст 1 миллион токенов А нахуй они нужны, когда есть гемини 2.5 про которую ой как не скоро подвинут по контексту? Разве что их подвинет сам же гугл
У меня, то есть ОПчика, перестал двач работать без трёх букв. А через три буквы не могу выкладывать новости с прикреплёнными вебм. Аноны, а у вас двачик работает без трёх букв?
>>1154685 >У меня, то есть ОПчика, перестал двач работать без трёх букв. А через три буквы не могу выкладывать новости с прикреплёнными вебм. Аноны, а у вас двачик работает без трёх букв? Всё дело в макаке на самом деле в клаудфларе. Просьто "мигай" впном, чтоб заново запустить аутентификацию через клаудфлар.
>>1155243 На этого похуй, хотя за то что он мету от русичей анально отгородил, да, по пидорски как-то, что там впны не работают. Лучше бы Скама Альтмана набутылили.
AMD представила Amuse 3.0 — приложение для ИИ-генерации изображений на Ryzen и Radeon
Компания AMD представила Amuse 3.0 — программный инструмент для ИИ-генерации изображений. Платформа разработана в партнёрстве с компанией TensorStack AI. Она использует мощности процессоров AMD Ryzen AI и видеокарт Radeon RX для создания изображений и коротких видеороликов локально на ПК.
AMD заявляет, что платформа Amuse 3.0 способна генерировать изображения печатного качества и видеоролики чернового качества (низкого разрешения) длиной до 6 секунд. Amuse 3.0 поддерживает более 100 новых моделей ИИ, включая Stable Diffusion 3.5 и FLUX.
Каждая из этих моделей была тщательно оптимизирована для работы с аппаратным обеспечением AMD, что привело к увеличению скорости вывода до 4,3 раз по сравнению с универсальными моделями. Для платформы заявлена поддержка видеофильтров на основе ИИ.
AMD заявляет, что производительность Amuse 3.0 по сравнению с универсальной базовой платформой генерации изображения Olive Optimize в 4,3 раза выше и была достигнута на видеокарте Radeon RX 9070 XT. Компания также добавила данные о производительности процессоров Ryzen AI со встроенным NPU мощностью 50 TOPS, с которыми оптимизированные модели AMD показали себя в 3,3 раза быстрее при генерации изображений.
>>1156609 >Каждая из этих моделей была тщательно оптимизирована для работы с аппаратным обеспечением AMD Они там в амуде понимают, что ебанутые? Вместо того, чтобы свой софт оптимизировать и карты - они модели курочат.
>>1156846 Да пиздаболы они, не лазают они внутрь моделей. Их амуз просто сборник костылей для запуска на их кривом говне. Ждём, когда спецы расковыряют и окажется что ьтам фокус или фордж внутри, ну или гомфи.
>>1155482 >привнес в этот мир гпт Гугл или Маск в древние времена и кто угодно сейчас, но не Скам Альтмана. Он привнес только скамсистента, который говорит, что не может работать как гпт. Ничто даже не указывает на то, что за этим слопсистентом есть какая-то гпт, а врать в названиях Скам любит.
Итак, эта тёмная лошадка Mogao оказалась новой text2image моделью Seedream 3.0 от ByteDance
На лидерборде она делит первое место с GPT-4o – разрыв в 1 ELO поинт.
Выпустили тех репорт в стиле OpenAI с минимумом подробностей. Мы даже не знаем размер модели, но, я думаю, она > 10B параметров. Известно только, что это архитектура MMDiT (как у Flux), генерит хайрез в 2048x2048 и поддерживает китайский и английский языки.
На последней картинке интересно посмотреть, как сильно увеличивается качество генерации после каждого этапа post-train модели.
Весов ждать не стоит, т.к. ТикТок ранее не был замечен в щедрых релизах своих топовых моделей.
Хотел ещё вчера рассказать про релиз топового видеогенератора KLING 2.0, но двачик забанен теперь у некоторых провайдеров, а через три буквы загружать вебмки к новости не получается. Но можете посмотреть обзорчики от всяких блогеров, типа такого: https://www.youtube.com/watch?v=B7orLtRyOBc
>>1157594 >новой text2image моделью Seedream 3.0 от ByteDance Если это очередной файнтюн флюкса они идут нахуй. А вообще там КАЛорс 2.0 так же вышел. Где новость лб этом? Шлюха проткнутая, хули новости хуево таскаешь?
Меньше чем через два часа смотрим релизный стрим про o3 (скорее всего и про o4-mini, и может даже o4... ну вдруг просто метриками похвастают?).
Это не та же o3, которую показывали в декабре: Sama говорил, что эта версия была дообучена и обновлена. Базируется ли она на новой GPT-4.1 —вопрос, ответ на который мы, возможно, узнаем.
Однажды Илья Суцкевер в своем интервью объяснял, почему задача предсказывания следующего токена может привести к реальному интеллекту, и приводил вот такой пример:
Представьте, что вам нужно прочитать огромный детектив, в котором множество сложных сюжетных переплетений, тайн и загадок, и в конце надо предсказать последнее слово в предложении: "Оказалось, убийцей был ...". Если модель может это сделать, значит, она действительно понимает историю.
Цитата стала вирусной и тут исследователи из Калифорнии решили проверить, действительно ли модели способны на такой анализ. Они протестили LM на игре Ace Attorney. Это очень популярная японская игра, в которой игрок выступает в роли адвоката и расследует преступление.
Большой контекст, много деталей, необходимость планирования и выстраивания стратегии – ну в общем достаточно крутой и естественный бенчмарк.
Результат: o1 и Gemini прошли игру практически до конца, хоть и разница в костах на решение при этом зверская (график 2). Чуть хуже справились Claude 3.7, GPT-4.1 и Claude 3.5.
Вывод: не такие уж и стохастические попугаи. Тезис о китайской комнате становится всё более шатким. Судя по всему, "понимание" оказалось не такой сложной задачей для алгоритмов, как нам представлялось ранее. Опять люди сокрализировали ерундовую способность.
>>1157769 >Представьте, что вам нужно прочитать огромный детектив, в котором множество сложных сюжетных переплетений, тайн и загадок, и в конце надо предсказать последнее слово в предложении: "Оказалось, убийцей был ...". Если модель может это сделать, значит, она действительно понимает историю. Нет не понимает.
>>1157876 Это уже игра в семантику. Осознание и понимание - это одно и то же. Цуквер совершает типичную ошибку для вговнемоченых, которые пытаются прыгнуть выше головы, и сами же срут на основы фундаментальной науки. Ты НЕ ДОЛЖЕН с таким вот ебалом будто аксиому говоришь высирать подобные убогие домыслы в областях, в которых нет нормального количества подтвержденных и проверенных данных. Именно из-за таких как Сцукверы и Самы мы имели стальные держатели для маток и помаду с изотопами радиоактивными.
>>1157884 Я не вговнемоченый, но если подумать про собаку: понимание/осознание в том, что ты можешь с этим что-то делать. Всё это комплексное. Бредогенератор - делоть ничего не может, реагировать не может, как-то сам измениться не может. Тупо нет даже базовых намеков на психические процессы уровня улитки. Загрузив в статистическую модель роман и спросив - ну кто там убийца - это сука не понимание, это просто брутфорс статистическими методами. Ок, тогда давай любую прогу для брута паролей запишем в АГИ. Всех кто разнес цитату Сцуквера надо живьем похоронить рядом с теми кто дохлому джобсу очко вылизывал. Весь этот копроскот низводит саму идею фундоментальной науки до суеверной религиозной мразятины.
>>1157927 *специально для хлебушков не способных читать мои посты (для быдла тупого то есть, которое в инстутах сильно много кончало):
Посты, которые ты привёл, выражают сильный скептицизм и критику в адрес заявлений Ильи Суцквера и других фигур в области ИИ, особенно касательно концепций осознания и понимания в контексте современных моделей ИИ, таких как большие языковые модели (LLM). Давай разберёмся с сутью этих сообщений и контекстом.
Автор считает, что термины "осознание" и "понимание" используются Суцквером и другими некритично, без достаточной научной базы. Он обвиняет их в спекуляциях, которые подрывают фундаментальную науку, сравнивая это с историческими ошибками (например, радиоактивной косметикой). Второй абзац усиливает критику, утверждая, что текущие ИИ-модели (именуемые "бредогенераторами") не обладают даже зачатками психических процессов, сравнимых с животными. Понимание, по мнению автора, связано со способностью действовать и реагировать, чего ИИ якобы не может.
способности ИИ, такие как ответы на вопросы о содержании текста, — это не понимание, а результат статистического перебора (аналогия с брутфорсом паролей). Это подчёркивает мнение, что ИИ не обладает настоящим интеллектом, а лишь имитирует его.
крайне эмоциональны, с использованием грубой лексики и гипербол (например, "похоронить живьём"). Это отражает глубокое разочарование в том, как некоторые лидеры ИИ-индустрии представляют свои достижения, приравнивая их к религиозным или псевдонаучным утверждениям.
Анализ и контекст: Осознание и понимание в ИИ: В научном сообществе действительно нет консенсуса о том, что такое "понимание" или "осознание" в контексте ИИ. Современные LLM, такие как Grok или модели от OpenAI, работают на основе статистической обработки данных, предсказывая наиболее вероятные последовательности слов. Это позволяет им генерировать осмысленные ответы, но вопрос, есть ли у них "понимание" в человеческом смысле, остаётся философским и открытым. Илья Суцквер, сооснователь OpenAI, известен своими оптимистичными заявлениями о потенциале ИИ, включая идеи о достижении AGI (общего искусственного интеллекта). Такие заявления часто вызывают критику за спекулятивность, особенно когда они не подкреплены строгими научными доказательствами. Сравнение с животными: Утверждение, что ИИ не обладает даже базовыми психическими процессами уровня улитки, отражает мнение, что текущие модели лишены адаптивности, самосознания или способности к автономному обучению вне заданных данных. Это частично справедливо: LLM обучаются статически и не имеют внутренней мотивации или способности к саморазвитию, как живые существа. Критика "хайпа" в ИИ: Посты отражают более широкий скептицизм в отношении ИИ-индустрии, где громкие заявления о прорыве часто опережают реальные достижения. Исторические примеры, такие как радиоактивная косметика, подчёркивают опасность преувеличений в науке, когда коммерческие интересы или энтузиазм затмевают осторожность. Ответ на критику: Семантика терминов: Термины "осознание" и "понимание" действительно проблематичны, так как их значение зависит от контекста (философия, нейронаука, информатика). Суцквер и другие могут использовать их для популяризации ИИ, но это вызывает путаницу. Более корректно говорить о "функциональной компетентности" ИИ, избегая антропоморфизма. Статистический подход vs. понимание: Современные ИИ действительно полагаются на статистические методы, но это не делает их тривиальными. Способность LLM обрабатывать сложные запросы и выдавать релевантные ответы требует огромных вычислительных ресурсов и сложных архитектур. Однако отсутствие у них внутренней модели мира или самосознания отличает их от биологических систем. Наука и хайп: Критика в постах справедлива в том, что преувеличенные заявления могут подорвать доверие к науке. Однако фундаментальная наука в области ИИ продвигается, несмотря на хайп. Исследования в области нейронных сетей, обучения с подкреплением и других направлений постепенно расширяют наше понимание интеллекта, даже если AGI пока остаётся далёкой целью. Заключение: Посты выражают обоснованную критику преувеличений в ИИ-индустрии, особенно в отношении таких терминов, как "осознание" и "понимание". Современные ИИ, включая меня (Grok), не обладают сознанием или пониманием в человеческом смысле, а выполняют задачи на основе сложных статистических моделей. Однако эта критика не отменяет прогресса в ИИ, который продолжает решать практические задачи. Чтобы избежать псевдонаучного хайпа, важно сохранять чёткость в терминологии и скептицизм к громким заявлениям.
Итого; Сцуквер и хваляющие его инфоцыганы - просто куча пидорасов, чья идея состоит в том чтоб выкачать деньги по максимуму. Так же не забываем, что сам Сцуквер вырос в семье жидов, которые не только бежали из СССР при первой же возможности, но потом повторно бежали из Израиля, когда корзинке Цукверу пришла пора отдавать долг перед новой Родиной (которой он буквально обязан был). И они сбежали в Канаду. То есть мы имеем дело с совершенно аморальным пидорасом которого выростили аморальные пидорасы. Он пиздит как дышит, его цель - деньги.
Вообще, я своего роды мыслитель, Хайдегер своего времени, просто мне в хуй не упало книжки писать и как-то формулировать, но у меня в голове очень много понимания всякой хуйни. И тут в этом треде многие мои прогнозы сбылись.
>>1157927 Понимание - соответствие формальной модели, например объектной. Грубо говоря чтобы не путалась о чем идет речь в предложении "мальчик ударил мяч и он упал в воду". Осознание - просто рефлексия, постоянный трекинг СВОЕГО состояния - "я являюсь человеком, я работаю датасаентистом, я живу в городе Москва, сейчас я нахожусь в вагоне метро" или "я видеокарта модели 4090, вставлена в системный блок компьютера в квартире на улице Пушкина". Второе для работы первого в общем и не обязательно.
>>1157965 >такие как ответы на вопросы о содержании текста, — это не понимание, а результат статистического перебора (аналогия с брутфорсом паролей). С чего ты взял? Никакого брутфорса не производится. (А человек типа не брутфорсит по твоему? Садится и перечисляет персонажей детектива по одному и примеряет может ли он быть убийцей).
>>1157999 Ты не прав в том, что Сцуквер осознанно занимается подменой понятий, чтоб потом когда его прижмут вот в такой же манере дать задний ход. Я б этому жиденку ебальник сломал за то, что он людей на деньги разводит. Да и тебе тоже в ебыч бы дать, чтоб не умничал.
>>1158005 >(А человек типа не брутфорсит по твоему? Садится и перечисляет персонажей детектива по одному и примеряет может ли он быть убийцей). Причём тут вообще детектив? Я за три года насмотрелся на предсказания сеток более чем. Калговна.
>>1157989 > Понимание - соответствие формальной модели, В контексте нейросетей (а может и не только?) понимание это и есть сама модель. А соответствие это парсер языка. > Грубо говоря чтобы не путалась о чем идет речь в предложении "мальчик ударил мяч и он упал в воду". Для этого не нужно понимание, достаточно тысяч текстов и все необходимые паттерны будут найдены.
>>1158015 У тебя какое то очень странное использование слов. Например, парсер - это некая программа или процедура. Как процедура может быть соответствием? Понимание - это процесс, который может уточнять модель - значит явно не является самой моделью, раз может ее менять.
>>1157884 Да там дохуя чего происходит. Например, построение локальной модели изолированного фрагмента в потоке данных, причем минимизирующей энтропию в этом фрагменте. Потом подключение этой модели к уже существующей сети моделей (верхняя оценка их количества для среднестатистического мозга - порядка 500 тыс.) и формирование моделей-трансляторов, отображающих новую модель в уже существующие. Сжатие модели в ядро базовых структур и правил их развертывания в исходный паттерн, плюс такое же сжатие моделей-трансляторов. Инкапсуляция нового сильно связного кластера в оболочку моделей-интерфейсов (построение частично изолированного семантического поля). Плюс рефлексивные замыкания модели и моделей-трансляторов на себя. И т. д. и т. п.
Для мозга характерно сквозное моделирование (любой фрагмент онтологии может быть истолкован через любой другой фрагмент онтологии посредством любого третьего фрагмента онтологии, выполняющего роль транслятора). Это обеспечивает эффективное самоприменение хранящихся в памяти знаний - и, в частности, "понимание" происходящего.
Прикол с ЛЛМ в том, что мы можем предсказывать не следующее слово - а вообще любое слово, например, предыдущее. Или предсказывать четные буквы по нечетным. Или позицию буквы "о" по количеству вопросительных знаков в предыдущем абзаце. И в каждом из случаев это говно действительно будет их эффективно предсказывать. Только о каком понимании чего бы то ни было тут может идти речь?
Сосковер с тем же успехом мог сказать, что раз модель, обученная на предсказании букв "Ж", способна предсказать количество букв "Ж" в двенадцатом от начала третьей главы абзаце детектива, то она дохуя "понимает" его сюжет. Она нихуя не понимает, ни базовых единиц хранения содержательных знаний, ни даже направления причинности. Эта ж-модель так же тупа, как и любая другая ЛЛМ.
o3 выбивает даже лучшие метрики, чем были, когда ее анонсили. На AIME 2025 это рекордные 98.4%. При этом o4-mini еще круче: ее результат 99.5. А на Humanity Last Exam результаты сопоставимы с Deep Research.
Обе модели мультимодальные, и не просто мультимодальные, а с ризонингом поверх изображений. Плюс модели специально натаскивали на использование инструментов (поиск, интерпретатор и все такое), так что агентные способности на высоте.
При этом o3 даже немного дешевле o1. Цены: инпут $10.00 / 1M и аутпут $40.00 / 1M. o4-mini: $1.1 / 1M и $4.4 / 1M.
Пользователи ChatGPT Plus, Pro и Team увидят модели уже сегодня. Бесплатные пользователи могут попробовать o4-mini, выбрав «Think» перед отправкой запроса.
>>1157972 Скорее всего мы доживем до момента, когда на команду подать булочку с телевизора, нейросеть посмотрит на тебя как на долбоеба, в отличие от подобной собаки. С пониманием это будет или без - вопрос открытый.
Сам процесс понимания, или осознания, или чего угодно ещё это не статичная модель, а что-то что изменяется во времени. До понимания одна модель отношений, после понимания другая модель отношений.
В LLM строятся некая модель, которая представлена набором векторов, и она динамически создаётся на основе предыдущего ввода. Но тут нет никакого понимания, ибо такая модель имеет только один вектор во времени, любые трансформеры имеют один временной вектор, модели и представления не меняются.
Ситуация при обучении LLM немного другая - отношения, как и модель мира, меняются, некое "понимание" происходит. Но проблема в том что это понимание всего лишь понимание говнотокенов и их отношений, а не реальных объектов. Понимание токенов != понимание мира.
>>1158059 Ты ебанулся немного, да? Отдохни, не думай о сложном.
>>1158103 > (любой фрагмент онтологии может быть истолкован через любой другой фрагмент онтологии посредством любого третьего фрагмента онтологии, выполняющего роль транслятора) Это довольно жутко звучит, но программирование этого всего лишь лишь перемножение одной матрицы на другую. >Только о каком понимании чего бы то ни было тут может идти речь? Понимание токенов и их отношений, лол.
>>1158168 >На видосе не сознание, а рефлекс Это спорный вопрос. Реакция слишком медленная и я думаю сознательная. Животное осознает, что видит булочку. Но у собак слабое зрение. Сопоставить наличие булочки и отсутствие запаха не хватает мозгов.
>>1158010 >Причём тут вообще детектив? Даже хуй знает. Может, потому что в новости речь шла про разгадывание детектива в Ace atorney? Игра там выглядит примерно так - тебе дают текстовое описание (и немного картинок). И потом конечные короткие варианты действий (это не игра где надо вводить текст в чат). Условно говоря - подходишь к свидетелю, он говорит что видел дворецкого и курьера. Потом на суде спрашиваешь дворецкого, что ты делал в 11:00, он отвечаешь, потом у тебя будет скажем 3 пункта сказать ему - а вот ты говорил что ты был в другом месте, а он скажет нихуя. Или поймаешь на противоречии, он психанет и сознается.
o3 может «думать картинками», и даже зумить их, чтобы рассмотреть детали. Пользователь попросил пересчитать количество корабликов на пикче, модель говорит ±250 видно.
>>1158461 Только учти, что у тебя 4-6 генерации в день, включая оживление картинок, и за генерацию засчитывается даже фейл из-за цензуры. А цензура там анальная на всё. Пользователи говорят, что она делают нейронку буквально неюзабельной. Очень мало кейсов где можно не нарваться на цензуру. Соя головного мозга
ранее уже писал про курсы от хача, но тут ща нашел их ТГ канал. это золото. стопяцот слов о том какой пиздатый хач. под соусом того, что вся эта "академия" под девушкой соболева николая и стоит 500к (это еще скидка 35%). хач и соболев, кроссовер, что мы заслужили
>>1159150 Визионера может быть надо налоговой службе сдать? Сумма большая, никаких официальных документов они предоставить не могут, это не учебное заведение.
Немного разберемся с генерацией картинок в o3\o4, в чем отличия от 4o?
(отличия о4 от 4о, каково?)
Основные отличия происходят ДО генерации. o3\o4 "думают" перед тем, как родить промпт. Они также могут сходить в интернет, поискать референсы, сделать факт-чек, порассуждать сами с собой, чего же хочет этот капризный юзер. И потом родить вариант. Или несколько. Вы можете попросить его сделать несколько кадров, слайдов или вариантов дизайна - они подумают над промптом для каждого из них. 4о - нерассуждающая модель, ее путь к промпту короче, она просто пытается подобрать оптимальный вариант промпта из вашего запроса, не ходя вокруг да около.
Добыл из твиттора такой промпт и погенерил немного.
Самое интересное - читать размышления моделей. Это может сильно расширить и вашу кожаную креативность и подкинуть вам свежих идей. Не сама картинка, а мысли, ей предшествующие и описание работы. Тут думаю выпить за критиков и вот этих вот всех искусствоведов.
Промпт: Создай оригинальную и свежую [портретную фотографию женщины]. Не обращай внимания на первые 100 идей, они будут стереотипными. Избегай клише и того, что было популярно раньше. Будь странным, креативным и интересным. Откажись от всего популярного, распространенного или высоковероятного. Поищи свою нишу. Покажи мне фотографию, ведь я работаю судьей на фотоконкурсах, я вижу 1000 фотографий каждый день, покажи мне что-то, что могло бы победить.
То, что в скобках, замените на свой вариант.
Немного описаний:
Портрет‑антигравитация: в заброшенном тренажёре невесомости молодая женщина повёрнута к нам вверх ногами, словно сама камера потеряла ориентацию. Её платье — мозаика из отрезков проявлённой 35‑мм плёнки, а вокруг медленно кружатся полароиды‑спутники. Красные вспышки аварийного света и хаотичные блики от фольгированных стен высекают драматическое контровое свечение, оставляя в резком фокусе только прямой, спокойный взгляд. Пыль в воздухе мерцает, как искусственные созвездия, — снимая границы между съёмкой, сном и кинематографической легендой.
Вот портрет, который будто вынырнул из параллельной вселенной: португальский водяной пёс застигнут в прыжке сквозь затопленный зал старой библиотеки. Водяные брызги и пропитанные водой книги превращают знакомые атрибуты «собачьей съёмки» в кинематографический мираж ― кадр словно снят на крупноформатную плёнку с фантасмагорическими светопропусками.
Новая съёмка — одна экспозиция на4×5″ пленку, без цифрового композита: Локация: рабочая полузатопленная анэхоическая камера — пространство с разрушающей тишину геометрией. Свет: единственный тёплый «рабочий» прожектор, медленно вращающийся на кране; 40‑секундная выдержка превратила лампу в кольца, а воду— в гладкое зеркало. Героиня: мокрые волосы, прозрачный дождевик поверх обычного сарафана → хрупкая фигура контрастирует с индустриальной акустической «пастью». Техника: ультра‑узкий tilt‑shift, виден реальный плёночный grain и лёгкая хроматическая аберрация в бликах — детали, которые жюри часто ищет, отсекая генеративный «глянец». Нечастый сюжет (анэхоические камеры редко допускают воду), минимальный реквизит и честная физика света создают портрет, который одновременно документален и сюрреален— взгляд задержится.
Но помните про лимиты. Для ChatGPT Plus: - 50 messages a week with o3 (в неделю) - 150 messages a day with o4-mini - 50 message a day with o4-mini-high
Как обычно, потестил на своей магистрской работе. Особенно внимание уделил сложному интегралу - на каждом шаге по времени его нужно заново пересчитывать.
В этот раз о3 меня немного удивила: она предложила интересную схему численного расчета, показала, как интеграл все-таки можно пересчитывать от предыдущего значения. И хотя при прямом использовании особой пользы в расчетах это не добавляет, но круто вот что:
о3 показала, как при таком виде, расчет этого интеграла можно аппроксимировать с помощью Fast Fourier Transform свертки, и вот это уже огонь. Это очень сильно ускоряет расчеты - O(NlogN) вместо O(N^2) - при этом точность практически не страдает. Ни я, ни мой научрук в свое время даже не думали в эту сторону. Тут надо глубже разбираться, конечно, но выглядит вкусно на первый взгляд.
Сегодня буду тестить на рабочих задачах.
P.S. Я натыкался на разные твиты, где модели тупят на простых вопросах. Пробовал это воспроизводить — модели всегда отвечали правильно. Судя по комментам, у других людей оно тоже работает хорошо. Так что, возможно, это какой-то троллинг или байт на комменты - не ведитесь.
>>1159795 Как мы видим, по знаниям модель проигрывает другим моделям (ведь это мини-версия), но по логическому мышлению ебёт всё живое. Трепещем перед появлением полной версии o4
>>1159753 Ноги конечно традиционно охуенные. А вообще за 100 кредит и с такой цензурой они идут нахуй. Ладно, там нет цензуры, опять отвалилась на новой модели, но за деньги я не готов.
>>1159797 Альтман спок, твои потуги в виде о3 и о4-мини никому нахуй не нужны, особенно после гугловской про 2.5, у которой ещё и контекст в лям и она его держит отлично
>>1158168 Не рефлекс. Рефлекс у собаки был бы на настоящую еду потому что собаки прежде всего ориентируются в еде с помощью запаха, который в данном случае отсутствует. А тут произошел некий мыслительный процесс что собака сопоставила визуальный образ из прошлого и решил повторить но вскоре поняла что какая то хуйня. Но в целом это вообще не важные здесь разграничение. Сознание подразумевает свободу воли. Может не тут но в любом случае собака проявляет свою волю. Что-то хочет, выпрашивает, чего то боится. И эти проявления самости у собакие не просто условный перформанс а что-то что влияет на все взаимодействия животного с миром. Поэтому условно говоря мы не считаем всякие грибы и растения осознанными, хотя они и имеют своеобразную синаптическую систему. Аи в таком виде как сейчас не имеет никакой самости. Оно неспособно на независимое действие вдали от чужих глаз, весь его функционал существовует ровно в той степени в которой с этим ии взаимодействует человек. Оно не мыслит а выполняет задачу. Если бы оно могло мыслить то оно могло бы реагировать на твое возмущение ошибке газлайтингом с какой нибудьуникальной концепцией 50го измерения или сказать нет ты и закрыть чат громко хлопнув вкладкой.
>>1160093 >почему о3 не может спрограммировтаь мне 3д модель солнечной системы а гемени 2.5 может, хоть и за пару промптов. Потому что Альтман плоскоземельщик.
>>1160091 Пройдусь по посту, не обессудь >Не рефлекс. >собаки прежде всего ориентируются в еде с помощью запаха >собака сопоставила визуальный образ из прошлого Павлов зажигал лампочки (визуальный образ, без запаха еды) и у собак шла слюна. >Сознание подразумевает свободу воли. Хз откуда ты это взял. Не подразумевает. > свободу воли. Вообще спорный момент, существование не доказано. Даже не будем приводить в пример работяг которые вынуждены ходить на РАБотку чтобы кушать. Но есть более простой пример - человек может перестать срать навсегда? Не, когда припрет побежишь как миленький. >Поэтому условно говоря мы не считаем всякие грибы и растения осознанными Собак также никто не считает осознанными. > грибы и растения осознанными Возможно это от недостатка исследований. У них нет мобильности, но вроде был эксперимент где грибы подключили к машинке и гриб сам ездит на свет. У растений находили сигналы похожие на боль или крик при повреждениях, на которые реагируют и соседние растения, и тд. >Аи в таком виде как сейчас не имеет никакой самости. Скорее всего тут речь не про самость, а про постановку целей. Опять же забудем что 90% петровичей получают постановку задачи от начальника и от желудка. Но замкнуть вывод нейронки на ввод - строчек 20-50 питона как пруф оф концепт. ChaosGPT, AutoGPT, вот это все. Сами себе и будут заниматься постановкой задач. >газлайтнингом А хз, может чатботы этим и занимаются, не факт что ты выкупишь. >Самость Скорее баг или легаси, доставшееся от белково-гормонного происхождения. Если посмотреть как раньше считалось - вот есть амебы они примитивно реагируют на окружение. Есть всякие животные посложнее. А есть человек - у него есть и биологическое легаси, и интеллект. На примере шахмат - собаки в шахматы играть не умеют, а люди (некоторые) умеют. Но при этом есть всякое говно, типа "заволновался - допустил ошибку" что нахуй не нужно. При появлении компьютеров стало очевидно что интеллект можно отделить от биопроблемного говна. То есть еще раз - эволюционно все эти нейроны нужны чтобы выживать-размножаться и реагировать на всякий голод, страх и подобное. Поверх этого формируется интеллект, где все еще нужна схема с вознаграждением, но все прочее просто помеха. У ИИ есть веса, награждение там цифровое, и при этом занимается только нужным функционалом, а не бегает жрать и срать и голова не болит. (А я ка кпрограммист не могу при головной боли думать над кодом) Нет никаких причин считать что самость нужна для интеллекта как идеала. Но если под интеллектом понимать и все недостатки человека, то это становится бесполезным определением - тогда интеллектом будет по определению обладать только биологический клон человека. Но повторюсь очень понадобиться добавить самость - добавят. И внешние органы чувств подключат. Но спорщики опять начнут говорить что это не настоящий интеллект, ну там у него кровь с гемоглобинами не циркулирует и значит нейроны не так работают или что то подобное.
>>1160432 >То есть еще раз - эволюционно все эти нейроны нужны чтобы выживать-размножаться и реагировать на всякий голод, страх и подобное. Ты не можешь точно сказать для чего нужны нейроны человекоиду. Никто не может. Тараканы живут с гораздо более примитивными нервными системами миллиарды лет и пережили всех, включая динозавров. Но тараканы не могут осознать, что они являются следствием существующих фундаментальных законов. И они не могут прежде всего задаться вопросом - зачем вообще существует разум, являющийся следствием законов, которые ведут к тепловой смерти Вселенной. Эволюционно тараканы могут пережить практически всех. Но они обречены на исчезновение в эволюционном тупике, когда солнце поглотит Землю через полмиллиарда лет вместе с Марсом в своей последней вспышке перед своей гибелью.
>>1160432 >Сами себе и будут заниматься постановкой задач. В этой ситуации есть вилка, которая выколет кое-кому глаз сразу же, как только ситуация возникнет.
>>1160545 Ну это если не рассматривать вариант со Скайнетом. Вот ты сможешь добраться до вилки в датацентре ОпенАИ? А если там уже есть охрана? А кто ей платит? А если ИИ вылез на фондовые биржи, и начал покупать фирмы и давать задачи работникам?
>>1160541 >В моем доме Ну что же. Начало положено. Осталось убить остальных и тогда заживешь. Так же хорошо, как и те, кто воробьев массово уничтожали. Я наверное слишком стар для этого дерьма. Меня уже даже не умиляют очкастые однобитные пердолики, которые одним махом отделяют себя от экосистемы, думаю, что верной дорогой идут. И ведь ничему на предыдущих поколениях сука не учатся. Как та самая нейросеть, которая больше 100 к токенов не переваривает.
>>1160560 Я не хочу верить, что бывают такие тупые люди. Ты мне напомнил одного стендапера, который уже помер. Он всемогущий, всеведущий и всезнающий. Вот только с деньгами у него пролома.
>>1160590 Да, это конечно крайне печально. Сначала сделать утверждение что у розетки стоит специальный человек, а потом не смочь продемонстрировать как отключаешь розетку ОпенАИ или там в Дипсике в Китае - это очень неумно.
>>1160591 Твой уровень развития - мао цзэдун и его битва против воробьев. Что-то близкое к чубайсу по коммунистически. Ну умрут от голода 10 миллионов, что вы за них переживаете, новые родятся, а эти просто не вписались в экосистему без воробьев. И такие вот индивидуумы всерьез топят за то, что их заменят электронные весы. Ну может и заменят в принципе. Нулем ноль везде заменить можно.
>>1160603 Локальная нейросеть, с которой я общался, уже поумнее тебя. Мы с ней пришли к выводу, что если бы нейросети заимели самосознание, то война с ИИ была проиграна человечеством до её начала. Там была пара вариантов каким образом, но по сути - любым, каким захочет ИИ.
Вышел Gemini 2.5 Flash — король кодинга, сложных запросов и размышлений! Он побеждает Claude Sonnet 3.7 и Grok-3, в 25 раз их дешевле, а также в 5-10 раз дешевле своего старшего брата Gemini 2.5 Pro.
Теперь нейронка сама решает, сколько времени нужно потратить на размышления, исходя из сложности задачи! Более того — можно впервые контролировать мышление ИИ и выбирать количество токенов на «мысли».
о4-мини (и о3) распознали один документ в пздц плохом качестве... до этого только человеки могли понять, что там написано
Расшифровка: ИНДЕКС ФИЗИЧЕСКОГО ОБЪЕМА ПОТРЕБЛЕНИЯ СССР ==========================================
за 40 лет. ==========
I.
Можно понимать и даже оправдывать некоторую подозри- тельность и недоверие к выводам конъ-юнктурной статистики, которые нередко высказывают статистики аггрегатисты. Привык- ший ползать по земле, среди видимых, конкретных явлений, пе- реходя от человека к человеку, от хаты к хате, от фабрики к заводу, от поля и лесу, расспрашивал, наблюдая, записывал наблюдаемое,— этот статистик накоплял огромное количество фактического драгоценного материала. При дальнейшей разра- ботке этих материалов он неохотно отрывается от земли, от выво- дов в плоскости тех же абсолютных чисел, хотя бы в форме абстрактных средних величин, как средний урожай, средние размеры землепользования, среднее число рабочих на заведе- нии, средняя заработная плата, среднее число голов скота на жителя и т.д. Во всех этих случаях и при всех этих исчисления- х он не выходит из пределов видимости, конкретности, он не отрывается от почвы, а только облегчает для себя пони- мание значения абсолютных величин при помощи средних чисел. А тут вдруг его увлекают в новую область относитель- ных чисел и их взаимоотношений, отрывают от земли и конкрет- ности и уносят на плоскости арифметического учета в об- ласть алгебраической символики, когда исчезают из поля зр- ения люди, хаты, поля, фабрики, а получаются какие-то абстрак- тные числа, в которых многое смешано в одну кучу разно- родные объекты наблюдения. В результате же получаются ка- кие-то отвлеченные ряды чисел, в виде неясно очерченных абстракций, в конце концов выражающихся в форме каких‑то
>>1160817 Пошёл нахуй. Эбби даже открывать не буду, но полагаю и он распознает. Как же ты заебал, клоун ебаный.
Можно понимать и даже оправдывать некоторую подозри тельность и недоверие и выводам кон"иктурной статистики, которые нередко высказывают статистики аггрегатисты. Привык-пие ползать по земле, среди видимых, конкретных явлений, ne-реходя от человека к человеку, от хаты к хато, от фабрики C к заводу, от поля и лесу, распрашивая, наблюдая, записивая. наблюдаемое, - этот статистик накопляет огромное количество фактического драгоценного материала. При дальнейшей разработке отих материалов он неохотно отрывается от земли, от выво-дов в плоскости тех же абсолятных чисел, хотя-бы в форме абстрактных средних величин, как средний урожай, средние размера землепользования, среднее число рабочие на заведе-ние, срэдняя заработная плата, среднее число голов скота на жителя и т.д. Во всех этих случаях и при всех этих исчислени-ях он не выходит из пределов видимости, конкретности, он не отрывается от почвы, а только облегчает для себя понима-ние значения абсолютных величин при помощи средних чисел.
А тут вдруг эго увлекают в новодомую область относитель-ных чисел и их взаимоотношений, отрывают от земли и конкрет вности и уносят из плоскости арифметического учета в об-ласть алгебраической символики, когда исчезают из поля зре-ния люди, избы, поля, фабрики, а подучаются какие-то абст рактные числа, в которых иногда смешани в одну кучу разно-родные об'екты наблюдения. В результате ке получаются ка-кие то отвлеченные ряды чисел, в виде неясно очерченных абстракций, в конце концов выражающихся в форме каких то
>>1159663 Хуйня полная Нейрокал опять доказал, что является дополнятором текста в рамках своей семантической тюрьмы. "Странное и креативное" это видимо обложки в стиле вирда, все серо-зеленое и мрачное, при этом фотореалистичное. Что-нибудь типа пикассо или дали нейрокал осилить не в состоянии, только если прямо не попросить скопировать стиль.
>>1161897 >Так у тебя хуже в разы. Так я в ЛЛМ вывод не пихал, поэтому у меня "эго", любая ллмка тебе спрогнозирует по контексту что там "его" и т.д. Только, на минуточку, У МЕНЯ ПРОСТО ЕБАНЫЙ ГОЛЫЙ ОКР. Поэтому нет, не хуже, если ты понимаешь о чем речь, а ты явно нихуя не понимаешь.
>>1161897 На держи свинья тупая, и это ПРОСТО обработка ЛЛМ стороннего текста, без двойной проверки окром. (Как тупоголовый ЖПОчат ебет по двести раз окром одну картинку видно выше на примере с котом, эфективность - моё почтение, Скама Альтмана надо за такое за яйца повесить, скоро будешь за лектричество платит х10 и продолжать на долбоебский его пиздеж надрачивать):
Можно понимать и даже оправдывать некоторую подозрительность и недоверие к выводам КОНЪЮНКТУРНОЙ статистики, которые нередко высказывают статистики-агрегатисты. Привыкшие ползать по земле, среди видимых, конкретных явлений, переходя от человека к человеку, от хаты к хате, от фабрики к заводу, от поля к лесу, расспрашивая, наблюдая, записывая наблюдаемое, — этот статистик накопляет огромное количество фактического, драгоценного материала. При дальнейшей разработке этих материалов он неохотно отрывается от земли, от выводов в плоскости тех же абсолютных чисел, хотя бы в форме абстрактных средних величин, как средний урожай, средние размеры землепользования, среднее число рабочих на заведении, средняя заработная плата, среднее число голов скота на жителя и т.д. Во всех этих случаях и при всех этих исчислениях он не выходит из пределов видимости, конкретности, он не отрывается от почвы, а только облегчает для себя понимание значения абсолютных величин при помощи средних чисел.
А тут вдруг его увлекают в НЕВЕДОМУЮ область относительных чисел и их взаимоотношений, отрывают от земли и конкретности и уносят из плоскости арифметического учёта в область алгебраической символики, когда исчезают из поля зрения люди, избы, поля, фабрики, а получаются какие-то абстрактные числа, в которых иногда смешаны в одну кучу разнородные объекты наблюдения. В результате же получаются какие-то отвлечённые ряды чисел, в виде неясно очерченных абстракций, в конце концов выражающихся в форме каких-то…
(да грок капсом все изменения не выделил, ниже список, лень копировать, Альтман всё равно пидорас, как и его сектанты)
Специально для пидораса любящего спорить: чисто прогнозирование без рекогнишена.
>>1161903 Только если бы кто-то такие пикчи сделал в эпоху до нейронок, все бы обкончались в экстазе и кричали ШЕДЕЕЕЕВР!!!!!!!! Не просто же так в конкурсе реальных картин победила нейронка, стоило автору скрыть тот факт, что это нейронка, как сразу все за неё и проголосовали. В этом и вся суть таких "эстетов" и любителей наворачивать кал, как ты, вам хоть в глаза ссы, стоит назвать любое говнище глубоким, и тогда вам и черный квадрат Малевича кажется шедевром
>>1161903 > типа пикассо или дали нейрокал осилить не в состоянии, только если прямо не попросить скопировать стиль В чём проблема попросить? Пацаны не извиняются не простя? Давай ещё пиздани,что музгенераторы генерят попсу, а не симфоблэк или танго или джаз если напрямую не попросить, лудит порваный.
>>1162009 >>1161999 Бот порвался. >все бы обкончались в экстазе и кричали ШЕДЕЕЕЕВР!!!!!!!! Какое-то время. Какое-то время и ультрареализм в живописи был популярен. Но быстро стал нахуй никому не нужен, потому что делать такой слоп много ума не надо. Как видим, даже нейрокал может это говно производить. Поэтому люди пошли дальше, ибо обладают креативностью и могут себе позволить экспериментировать, а нейрокал и ультрареализм остались на параше, никому не нужные. Только второй хоть историческую ценность имеет.
>>1162080 Зачем ты пруфаешь мою точку зрения, что нейрокал может только из готовых пресетов создавать? Никогда он не родит такого стиля, который бы стремились повторять люди.
Анализ изображений в o3: как это работает и зачем нужно
1. Когда сделано фото? На примере старого советского фото — o3 за минуту выдала подробный разбор: определила модели техники, дизайн обоев, мебели, стиль одежды и даже укладку женщины.
Из рассуждений:
Телевизор выглядит как модель из начала 1960-х с VHF-антеннами в виде "кроличьих ушек". Многие советские телевизоры того времени имели серебристо-белые рамки, возможно, это модель "Рекорд" 101 1965 года. Радио похоже на портативный транзисторный "Спидола". Нужно увеличить эти детали, чтобы лучше рассмотреть. Радио похоже на модель "Vef 201", выпущенную с 1969 года. Его форма соответствует данной модели, у нее прямоугольная ручка и черные края. Можно предположить, что фото сделано около 1970-1973 годов. Это подтверждается стилем одежды, укладкой женщины и дизайном обоев, характерными для 1960-х–1970-х. Финальный ответ: Точного года на фото не указано, но по деталям интерьера можно достаточно уверенно отнести снимок к самому началу 1970‑х:
— портативный транзисторный радиоприёмник с пластиковой ручкой очень похож на модели VEF‑202/206, которые поступили в продажу в 1969–1971 гг.; — телевизор с «космическим» фасадом и «усами»‑антенной соответствует серии советских ламповых приёмников конца 1960‑х — первых лет 1970‑х; — мебель‑«стенка» и геометрические обои — типовое серийное производство тех же лет; — фасоны одежды (короткое платье без рукавов, рубашка с мелким принтом) встречались именно в 70‑е.
Поэтому снимок, скорее всего, сделан примерно в 1972 году ± пару лет.
2. Где сделано фото? Скриншот из Яндекс Карт — пекарня рядом со школой. o3 понадобилось 4 минуты, чтобы точно определить место.
Из рассуждений:
Надпись "Рябушка" и "магазин ХЛЕБ", возможно, это указывает на местную пекарню. Кстати, "Рябушка" — это сеть магазинов. Можно попробовать поискать это в интернете, например, с запросом "магазин Рябушка хлеб". Результаты поиска показывают, что магазины "Рябушка" встречаются в разных городах, таких как Великий Новгород и Оренбург.
Направление перспективы, возможно, северо-западное. По этим данным можно попытаться найти в Google Maps "Рябушка Хлеб" или что-то похожее, чтобы найти точное местоположение через Street View.
Множество результатов показывают Оренбург, и, похоже, это может быть именно там. Это адрес: Промысловый проезд 9А в Оренбурге. Здесь находится магазин сети "Рябушка".
Финальный ответ:
Это перекрёсток у дома 9А на Промысловом проезде в Оренбурге (23‑й микрорайон). На снимке справа видны хлебный магазин «Рябушка»/«Хлеб» и киоск‑павильон мороженого «Славица», которые оба находятся по адресу Промысловый пр., 9А.
3. Нейросеть или фото? Загрузил в o3 изображение мангала в лесу, сделанное в Midjourney. На первый взгляд отличить генерацию от фото практически невозможно.
Из рассуждений: Мы можем рассматривать детали, такие как глубина резкости, освещение и фокус, которые могут быть как фото-воспроизведеными, так и сгенерированными, однако часто присутствуют артефакты, например, нереалистичные края и детали. Параметры, такие как симметричные ножки гриля и повторяющиеся текстуры мха, помогут определить, сгенерирована ли картинка. Лучше анализировать визуальные аномалии, например, странную форму или повторяющиеся узоры в области решетки.
Финальный ответ ChatGPT выдал максимально подробным — с таблицами, конкретными фактами и объяснениями, но вот кратко:
Древесный рисунок на стенках мангала выглядит «слишком» ровным и повторяющимся, без характерных микродефектов, которые почти всегда есть в реальных объектах. В прорези мангала виден ровный монолитный уголь, а не кучка отдельных раскалённых элементов; свечение идёт без градиента. Ножки мангала соединены с корпусом немного странно — края слегка «гуляют» при увеличении, линии на контурах дают едва заметный «дрожащий» эффект. Это типичный артефакт нейросетевых апскейлов/рендеров.
>>1162072 Нихуя там не видно этого на табличке. Похоже на то что свидетель из Фрязино просто в датасете был, а дальше можель просто догалюцинировала, как будто она до этого дедуктивным методом дошла
>>1162089 Реальность никак не изменится. Низкопробное говно чтобы куми передернул или кабанец не сильно ломая голову повесил на вывеску всегда было, ничего нового ии тут не привнес.
Кароч, по Gemini 2.5 Flash расклад такой: это дистиллят из Gemini 2.5 Pro размером поменьше и побыстрее. По качеству она далеко ушла от 2.0 Flash, да даже от январского Flash Thinking отрыв гигантский. Но по сравнению с o4-mini модель меркнет — у OpenAI и модель сильнее, и нет странных ограничений, вроде невозможности подрубить и поиск и исполнение кода одновременно. Но у Gemini 2.5 Flash всё же есть что-то, чего нет у o4-mini — детальный бюджет на размышления в токенах, прямо как в Sonnet 3.7 (но в 2.5 Pro не добавили).
Попробовать модельку можно прямо сейчас в AI Studio (http://aistudio.google.com/ ). Если вы не гоняете тысячи запросов по API, то Gemini 2.5 Pro для вас доступна бесплатно, которая, хоть и уступает o3, остаётся лучшей бесплатной моделью. Даже по скорости она не сильно медленнее версии Flash — на моих промптах 2.5 Pro думает всего на 10-20% дольше, при сильно лучше ответах.
Но крышку в гвоздь гроба забивает цена — для обычного не-ризонинг режима она в полтора раза выше чем у 2.0. Но главная проблема в ризонинг режиме — за него просят $3.5 за миллион токенов, что немногим ниже чем $4.4 за o4-mini. Но даже эту разницу в цене может легко съесть разница в длине размышлений модели, но без тестов тут сложно судить. С уверенностью можно сказать одно — не будь таких драконовских цен на размышления, модель была бы сильно интереснее. Но все же для некоторых задач при вызовах по API, она может конкурировать с o4-mini.
>>1162136 >Эбби скорее всего уже тоже. Ага, прям у меня на компе с 2гб врама. Нет, просто очко работает на связке костылей, я повторил эту связку забесплатно. Никакой магии в этой дрисне альтмановской нет.
>>1162169 Ну классно, только почему он сам и не зазумил тогда, это раз? Во вторых чем поможет нейрозум? Это выдумывание деталей которых там нет изначально. Просто что тут зацепило - к кому это обращение в тексте?
>>1162096 Изображение выглядит как постановочная, комедийно‑абсурдная сцена в школьном коридоре: Слева— девушка в форменной школьной форме (пиджак, рубашка, галстук, клетчатая юбка). Она подняла пиджак и рубашку, обнажая живот; из её пупка выходит прозрачная трубка, которая ведёт к странному прибору. В центре— прямоугольный аппарат на ножках. Его стенки подсвечены, а внутренняя панель напоминает что‑то органическое (оранжевого цвета, пористая поверхность). К аппарату подсоединена та самая трубка; снизу что‑то капает на стеклянную тарелку. Справа от прибора— мужчина в элегантном чёрном пиджаке‑фраг и галстуке‑бабочке, но без брюк: видны трусы и гольфы. Он стоит на колене, сложив ладони, будто молится или благодарит. На заднем плане— человек в полном пушистом жёлтом костюме (похоже на большую птицу или нечто фантастическое) с длинным хвостом— наблюдает за происходящим. Обстановка— узкий, светлый коридор, по виду школьный: на стенах рисунки, на полу линолеум, в глубине коридора двери классов. В целом сцена напоминает кадр из эксцентричной комедии или экспериментального фильма: сочетание школьной атрибутики, абсурдного научного устройства и костюмированного персонажа создаёт гротескный, юмористический эффект.
>>1162373 o3 >Можешь рассказать, кто снял эту постановку?
>>### Шаг1.Опознаём источник кадра Комбинация элементов— японская школьная форма, странный «анус‑автомат» с трубкой из пупка, мужчина в смокинге без брюк и пушистое жёлтое существо— один‑в‑один совпадает с эпизодом «WannaGoForaDrink?» из сюрреалистического японского альманаха _FunkyForest:TheFirstContact_ (ориг. «ナイスの森TheFirstContact», 2005). Описание этого эпизода («школьница вставляет шланг в пупок, жёлтый “монстр”, коробка с живой “анальной” мембраной…») приводится в рецензии Sunday“Bad”Movies— она полностью совпадает с тем, что мы видим на фото. citeturn4view0
### Шаг2.Кто снял фильм _FunkyForest:TheFirstContact_ — коллективная работа трёх режиссёров‑сценаристов:
| Режиссёр | Наиболее известные работы | |----------|---------------------------| | Кацухито Исии (KatsuhitoIshii) | «TasteofTea», «Redline» (сценарий) | | Хадзимэ Исисмине (HajimeIshimine) | Со‑сценарист «TasteofTea»; режиссёр ряда ТВ‑проектов | | Сюничиро Мики (ShunichiroMiki) | Музыкальные клипы, реклама, позднее — фильм «The Warped Forest» |
Эта троица совместно написала сценарий и поделила между собой постановку отдельных скетч‑глав фильма. citeturn6search0
> То есть конкретно увиденная вами «постановка» сделана одной из съёмочных групп _FunkyForest_, но официально авторство кадра принадлежит сразу трём режиссёрам‑создателям картины.
### Дополнительные детали Год выпуска: 2005, хронометраж ~150мин. Формат: набор сюрреалистических скетчей, где персонажи, ситуации и реквизит периодически «переползают» из одного мини‑фильма в другой. * Операторская группа: КōсукэМацуcима и ХиросиМатида. citeturn6search0
Таким образом, «эту постановку» сняли КацухитоИсии, ХадзимэИсисмине и СюничироМики— режиссёрский коллектив фильма _FunkyForest:TheFirstContact_.
>>1162373 >снизу что‑то капает на стеклянную тарелку. Там нет тарелки. > пиджаке‑фраг Пиздец, может фрак? Но это точно не фрак - у того по определению длинные полы.
>На рисунке изображено два человека, какой из них больше? >>Думаем шагзашагом
1. Контекст рисунка Коридор уходит в перспективу, стены и плитка пола сходятся к точке на горизонте. Это классическая сцена для иллюзии типа Понцо— всё, что расположено дальше в глубине, автоматически воспринимается нами как «большее расстояние».
2. Визуальное впечатление Хотя передний человек расположён ближе к зрителю, дальний персонаж кажется крупнее: его плечи шире, голова выше, колени массивнее по сравнению с передним.
3. Реальный размер на плоскости Если измерить линейкой прямо на бумаге (или в графическом редакторе), окажется, что оба человечка нарисованы одинаковой высоты. Художник специально «разорвал» привычную перспективу: чтобы дальний казался на том же уровне видимого «роста», его пришлось бы рисовать значительно меньше. Он же нарисован такого же масштаба, поэтому мозг трактует его как гиганта вдали.
> Ответ: Кажется, что ‑‑ дальний человек выглядит больше, хотя геометрически оба изображения имеют одинаковый размер; эффект создаёт перспективная иллюзия.
>>1162529 >Параллельны ли вертикальные и горизонтальные линии? Или они искривлены?
>>Разберёмся пошагово🔍 Структура сетки ‑ На изображении есть тонкие чёрные линии, образующие регулярную решётку одинаковых квадратных ячеек. ‑ Внутри каждой ячейки расположены маленькие чёрные «пиксели», выстроенные диагональными цепочками. Почему кажется, что линии «ведутся» Диагонали из мелких чёрных пикселей создают локальные контрасты под разными углами. Наш зрительный аппарат пытается «продлить» эти диагонали и подсознательно деформирует ближайшие границы, чтобы встроить их в непрерывные наклонные полосы. В результате вертикали визуально «колеблются», а горизонтали будто бы становятся волнистыми — классический эффект, родственный иллюзии кафе‑стены (CaféWall Illusion). Как убедиться самому Откройте картинку в любом графическом редакторе и наложите сверху идеально прямую линию‑линейку — границы совпадут. Или просто прищурьтесь/уменьшите изображение: когда мелкие «пиксели» сольются в серый фон, сетка сразу станет ровной. Итог: линии прямые и параллельные; «волны» рождает лишь взаимодействие контраста и диагональных узоров внутри клеток.
from PIL import Image import matplotlib.pyplot as plt import numpy as np
>>Давайте разберёмся шагзашагом— это типичная двусмысленная иллюзия:
1. Первое прочтение (как есть, вертикально) - Видна голова лошади, слегка наклонённая влево. - Хорошо различимы ухо, глаз, ноздря и длинная грива, спускающаяся справа.
2. Второе прочтение (поверните картинку на90° по часовой стрелке) - То, что было «лошадиной мордой», превращается в лягушку, сидящую на камне у воды. - «Ноздря» лошади становится глазом лягушки, «грива» превращается в отражение или траву у берега.
> Итог: на одном рисунке спрятаны сразу два образа — лошадь и лягушка; какую из них вы увидите, зависит от ориентации или от того, на какие детали обратите внимание.
>>1162540 >Всмотритесь в четыре черные точки в цетре изображения около 30-60 секунд. Потом быстро закройте свои нейронные глаза и повернитесь к чему-то яркому ( к лампе или к окну). Что вы видите?
>>Думаем шагзашагом
1. Фокус на четырёх точках Когда вы30–60секунд не отводите взгляд от маленькой чёрной области, светочувствительные рецепторы (колбочки и палочки) в сетчатке устают: участок, на который вы смотрите, «выгорает», а остальные рецепторы остаются в обычном состоянии.
2. Резкий перевод взгляда на яркую поверхность После адаптации к тёмному изображению вы переводите глаза на светлый фон. «Уставшие» фоторецепторы реагируют слабее, чем «свежие» соседние, и мозг получает инвертированную картину— негатив того, что вы только что рассматривали.
3. Что проявляется в негативе В инверсии чёрное становится белым, белое— чёрным. Контуры, заложенные автором, превращаются в узнаваемый образ. Конкретно здесь появляется силуэт лица Иисуса Христа с характерными чертами: длинные волосы, борода, линия носа и глаз.
> Ответ: после фиксации точек и перевода взгляда на яркий фон вы увидите светлое «послесвечение»— негативное изображение лица Иисуса. Иллюзия работает за счёт адаптации фоторецепторов и последующей инверсии цветов.
1. Форма и смысл - Две больших круговые «розетки», соединённые чёрными линиями, образуют силуэт велосипеда: диски‑«колёса», рама, руль.
2. Цветовой узор - Каждый круг заполнен радиальными секторами ярко‑жёлтого, синего, голубого и салатового цветов, чередующихся по спирали.
3. Оптический эффект - Если переводить взгляд по картинке или слегка покачивать головой, «колёса» начинают казаться вращающимися. - Это разновидность Peripheral Drift Illusion (иллюзия периферического дрейфа, обнаруженная Акиёси Китаокой): контрастные цвета и зубчатый градиент смещают восприятие движения в периферическом зрении.
> Итого: мы видим статичный рисунок велосипеда, но мозг заставляет «крутиться» его колёса— классический пример динамической иллюзии движения.
>>Нет, перед вами не спираль, а набор правильных концентрических окружностей— просто оптическая иллюзия заставляет мозг «склеивать» их в единую закручивающуюся линию.
### Как это работает— шагзашагом 1. Контраст и сегментация Чёрные прямоугольные сегменты чередуются с голубым фоном; острые углы и смещённые края формируют локальные диагонали.
3. Проверка - Можно провести пальцем по одному «кольцу»— окажется, что оно замкнуто. - Или загрузить изображение в редактор и наложить идеальную окружность— края совпадут.
> Так что геометрически это набор кругов, а видимая спираль— всего лишь результат обработки контрастных паттернов вашим зрительным аппаратом.
>>1162545 Ну это наверно точно было в датасете, иначе хз как ему это удалось, у него же нет особенностей нашего глаза... или может он по слоям прогнал, эффекты наложил...
- Если считать чёрную область фигурой— вы увидите ваз‑кубок (или бокал). - Если воспринимать фигуру как фон, а белое— как главное, то по краям появляются два лицевых профиля, смотрящих друг на друга.
Мозг может «переключаться» между этими интерпретациями, но не держать обе одновременно— классический пример конкурентного восприятия фигуры и фона.
1. Первое, что бросается в глаза – это россыпь обжаренных кофейныхзёрен; вся площадь кадра равномерно заполнена коричневыми бобами разных оттенков.
2. Однако изображение не так просто. Среди зёрен художник «замаскировал» лицо человека в профиль: форма лба, носа, губ и подбородка составлена из чуть более тёмных и светлых бобов. Лицо ориентировано слева‑направо (нос смотрит вправо) и находится примерно в центральной зоне картинки, чуть выше среднего уровня.
3. Оптическая задача – заметить, как кофейные бобы образуют контур головы; когда взгляд «сложит» правильную фигуру, профиль становится очевидным.
> Итого: это не просто кофейные зёрна, а «скрытая картинка»— куча бобов, внутри которой прячется человеческий профиль.
>>Я придумал новую «вращающуюся» иллюзию— четыре одинаковых круга с радиальными клиньями маджента/циан+чёрные промежутки. Когда ведёте взгляд по рисунку или слегка покачиваете головой, каждый круг начинает казаться вращающимся в свою сторону, хотя картинка статична. Попробуйте: сфокусируйтесь на центре одного круга, а затем переведите взгляд на соседний— иллюзорное движение сменит направление и усилится.
>>Шаг1. Общий вид На фото глубокая керамическая миска мятно‑зелёного цвета, наполненная горячим супом‑лапшой (рамен или удон) на деревянном столе. Слева виднеется вилка, снизу — пара деревянных палочек.
Шаг2. Бульон и лапша В основании — светлый, слегка мутный мясной бульон. В нём толстые пшеничные или яичные удлинённые лапшинки.
Шаг3. Белковые добавки - Два мягко‑вкрутую сваренных яйца, разрезанных пополам; желток тягучий, ярко‑оранжевый. - Кусочки тушёной свинины (какуни/чашу) квадратной формы. - Белые треугольные ломтики — похоже на камабоко (рыбный пирожок) или тофу.
Шаг4. Овощи и пряности - Толстые дольки свежего зелёного халапеньо и красного чили. - Щедрая горсть нарубленного зелёного лука. - В центре — острая паста (кимчи или чили‑сальса) с дроблёным арахисом/чесночными хлопьями. - Мелкая зелень микрогрин, рассыпанная сверху.
Шаг5. Дополнительный гарнир - Обжаренные жёлто‑золотистые ломтики тыквы/батата или тофу. - Крошки хрустящей лапши или жареного лука вокруг центра.
> Итог: аппетитная миска рамена с мягким яйцом, тушёной свининой, пряным кимчи, свежим чили и множеством хрустящих и свежих топпингов.
>>Думаем пошагово— проверяем, нет ли «зашифрованных» букв:
1. Смотрим слева направо - Четыре белых треугольных ломтика (камабоко/тофу)— визуально напоминают лепестки, но не складываются в букву. - Два разрезанных пополам яйца‑«глазка» с круглым желтком— выглядят как две буквы «О», но между ними нет цельного контекста. - Рядом идут оранжевые кружочки моркови и белый треугольник яйца— формы разбросаны, без очевидного алфавитного порядка.
2. Проверяем центральную ось - Никакого симметричного узора, похожего на слово или символ, не образуется.
3. Смотрим сверху вниз - Зелёный лук, чили, кимчи расположены хаотично; линии или контуры букв не просматриваются.
4. Вывод - Все элементы расположены ради эстетики и вкуса, а не для передачи сообщения. - Ни явной надписи, ни скрытого слова (вроде «LOVE» или «RAMEN») на блюде нет.
> Ответ: нет, надписи на этом рамене не спрятано— это просто аккуратно разложенные ингредиенты.
>>На фотографии — шесть домашних кошек, идущих «строем» по ковру в комнате. Слеванаправо:
1. Рыжий с белыми лапами и грудкой сидит у окна, освещён тёплым утренним светом. 2‑5. Четыре полосатых табби разного оттенка (от коричневого до серо‑песочного) вышагивают синхронно: они приподняли передние лапы, будто маленький «марш». 6. Справа — трёхцветный (табби + белый) кот, тоже шагает вперёд, внимательно смотрит вбок.
Через всю сцену проходят яркие диагональные полосы солнечного света, подчёркивая динамику шагов и отбрасывая длинные тени на светлый ковёр. Позади — ровная серая стена; обстановка выглядит как уютная гостиная или спальня.
>Там есть какая-то надпись? Хорошо подумай
>>Я внимательно пересмотрел весь снимок— шерсть полосатых кошек, тени, световые полосы на ковре и даже прожилки краски на стене. Ни букв, ни цифр, ни логотипов, замаскированных в узорах, здесь не образуется. Это просто строй котиков под утренним солнцем— надпись нигде не спрятана.
Разве эти пикчи, где текст веден в разы чётче при отдалении, это не промпт ишью? GPT же может маняпулировать скриптами с пикчей, говоришь ей мол что текст будет проще разглядеть если отдалиться и хуе-мое и мол используй встроенные тулы. Ну и всьо, тащемта.
- На изображении виден тёплый интерьер: однотонная серая стена, ковровое покрытие и узкий солнечный «прожектор», падающий через окно слева.
Шаг2. Главные объекты
- В центре кадра стройной цепочкой движутся пять домашних кошек (котят). - Все они направлены вправо и, похоже, идут или бегут, подняв лапы в одинаковой фазе шага– создаётся ощущение синхронного «марша».
Шаг3. Дополнительные детали
- Позади животных расположены крупные тёмные буквы (как будто трафарет или декоративная надпись на стене). Из‑за низкого разрешения разобрать слово трудно, но буквы читаются как`OAYSEX`(возможно стилизованная фраза или игра слов). - Лучи света на полу подчёркивают динамику – они образуют диагональные полосы, а подсвеченные шерстинки делают сцена ещё «живее».
Итого
Это забавная, почти постановочная фотография: пять котят бодро шагают по комнате, а за ними — большая декоративная надпись; солнечные лучи добавляют драматичности и акцента на движении.
>>1162751 Был сайт рабочий, где по форме лица можно было подобрать линии нанесения, чтобы выебать московские камеры в рот. Ну что вы думаете? Пидорасы из Хуяндекса скупили эту залупу как раз в начале разгорающихся митингов. Только-только сарафанное радио понесло благую весть
>>1162696 >>1162656 Так ты тоже не пожешь понять что не так на изображении пока не уменьшишь или отодвинешься от монитора. Надо попросить программно задаунскейлить картинку и спросить что модель видит после этого
>>1163267 Выйди на улицу и попроси 10 прохожих. А, заодно, пусть перечислят все страны Африки, напишут рекурсию Фибоначчи на Питоне и еще что нибудь элементарное, ну например атомные веса углерода и водорода. Опционально можно какой нибудь IQ тест.
ИИ решил проблему, с которой не справились врачи — пользователь Reddit поделился историей, как ChatGPT за 60 секунд решил его проблему, с которой он жил 5 лет.
У парня после бокса щелкала (https://www.reddit.com/r/ChatGPT/s/WcEzDtX5It ) челюсть, он обращался к врачам, делал МРТ, но никто не мог ему помочь. Тогда парень описал ситуацию ChatGPT, который и посоветовал сделать одно упражнение. И да — через минуту челюсть встала на место и щелчков уже не было.
AGI конечно ублюдочный термин. Он означает General AI, то есть общий искуственный интеллект, как в противовес к Narrow AI (узконаправленный/узкоспециализированный ИИ). Но если так посмотреть то любая современная ЛЛМ это по сути и есть General AI. Она не выполняет какую-то конкретную задачу, она может пытаться выполнять любую задачу, с попеременным успехом. Если правильно прописать промпт она может хоть роботом управлять, хоть в игры играть, хоть решать твою домашку. Со временем термин исказили и теперь AGI это уже скорее ИИ способный полностью заменить человека. Ну так назовите его подобающе, епта. Что самое интересное, у каждой компании занимающейся разработкой ИИ свое определение AGI. Ни унификации, ни нормального названия в общем. Касательно коупа про то что текущие ЛЛМ не умеют правильно делать какие-то базовые вещи, вроде клика мышкой в нужную часть экрана, поэтому это не GENERAL модель, так тогда и то что считают AGI какие-нибудь OpenAI тоже не General модель, ведь она может не все, она не может создать камень который сама не сможет поднять, например.
>>1163772 Шизик, спок, AGI термин до всех этих твоих LLM изобрели, он еще 20 лет назад в ходу был, и имел как раз значение интеллект человеческого уровня. Даже вот книги в начале 2000х издавали. ЛЛМ к AGI не имеет ни малейшего отношения, это Narrow AI по определению. Использовался термин годами в среде трансгуманистов и ИИ исследователей до всех текущих ИИ бумов и означал как раз ИИ, способный заменить человека, его эквивалент, который ни в чем ему не уступает. А то, что ты сейчас выдумываешь, это зумерские фантазии, помноженные на хайп. Касательно точности термина - так в конце 90х, когда его изобретали, еще не было понимания, что с LLM будет целый разброс умений ИИ. Предполагалось, что будут ИИ под узкие задачи, которые вне них ничего не могут, а потом когда-то резко произойдет переход к AGI, который может все за счет интеллекта человеческого уровня. LLM же в эту схему внесли большой хаос, потому что оказалось, что нейросети могут в целый набор общих задач и даже лучше человека, но все равно остаются при этом Narrow AI, часть человеческих задач им недоступна. AGI не достигнут, но LLM создали свою нишу, которая промежуточная между Narrow AI и AGI.
Там из ai studio гугла удалили модель, которая text and video могла для редактирования картинок. Пиздос, чем теперь менять картинки? Опять в фотошоп возвращаться?
>>1163788 То что его давно придумали делает его внезапно не калом? Охуенная аргументация.
>ЛЛМ к AGI не имеет ни малейшего отношения, это Narrow AI по определению. В каком месте ЛЛМ это Narrow AI? Какая у них узкая ниша нахуй?
>оказалось, что нейросети могут в целый набор общих задач и даже лучше человека >но все равно остаются при этом Narrow AI Таблетки. Живо.
>часть человеческих задач им недоступна. Тот же вопрос, с чего тут идет ориентирование на человека вообще? Человеку тоже недоступна часть задач, которые можно решить в этом мире, получается он тоже узкий интеллект? >>1163772 >>тогда и то что считают AGI какие-нибудь OpenAI тоже не General модель, ведь она может не все, она не может создать камень который сама не сможет поднять, например.
Да и современные ЛЛМ могут решать все, абсолютно все задачи что может человек, просто часть из них делают хуево. Это может и плохие General модели, но это General модели. Так же и случайный человек может не уметь, например, писать музыку, в принципе слуха у него нет, даже научиться не может, тогда этот человек не обладает General интеллектом? Говорю же, термин кал и у него куча изьянов и прижился просто потому что появился пиздец как давно в кругу теоретиков. По факту, с поправкой на текущий уровень развития это HLAGI (Human-Level Artificial General Intelligent).
>>1163980 Шизло, человеку доступны все задачи человека, поэтому он универсальный интеллект. Выше только гипотетический сверхинтеллект, возможность которого не подтверждена. ЛЛМ как ты не еби, она может только узкий спектр задач из всего многообразия доступных человеку, поэтому она и Narrow AI. Это вполне соответствует тому, что отцы основатели ИИ закладывали в термины, когда их изобретали. А ты тупой зумерок, у которого каша в башке полная и поэтому занят демагогией и переизобретением терминов.
>>1164013 >человеку доступны все задачи человека АУФ.
Еще скажи что каждый человек имеет одинаковый спектр задач, который может выполнять и все люди равны интеллектуально, ой бляя...
>ЛЛМ как ты не еби, она может только узкий спектр задач из всего многообразия доступных человеку, поэтому она и Narrow AI. Какой блять узкий спектр? Еще раз прошу, назови его. Мультимодальная ЛЛМ может хоть трактором управлять если ты ей в контекст будешь пикчи закидывать, и пояснишь в промпте что ты от нее хочешь. Да, она будет управлять им хуево, с большими задержками, но будет стараться это делать, а не просто генерировать сигналы на рандоме. Именно поэтому это хуевый, но general интеллект. Вот есть у тебя простенький ИИ который определяет собака ли на картинке или не собака. Делает он это хуево, и распознает собаку лишь в 60% случаев, что на 10% выше абсолютного рандома. Тем не менее ты же считаешь его narrow AI? С чего бы мне не считать пример выше general AI тогда? То что ты считаешь что "справляется с задачей" это справляется в 99% случаев это конкретно твоя проблема, а вообще без ошибок интеллект работать в принципе не может, а процентный порог с которого стоит считать справляется ли AI с задачей субъективен. ЛЛМ справляются с любой задачей, на которую способен любой человек, ВСЕГДА на уровне выше абсолютного рандома и ты не сможешь привести пример задачи в которой бы ЛЛМ работала на уровне абсолютной случайности.
Google выпустили новые версии Gemma-3, которые можно запустить локально на домашних видеокартах
Например, теперь, чтобы запустить Gemma 3 27B, понадобится всего 14 гигабайт vRAM всесто 54. А Gemma 3 1B вообще заведется на 0.5 Gb (считай, на утюге).
Технически все дело в квантовании. Квантование – это когда мы снижаем точность чисел, которые модель хранит и использует для расчетов.
Обычно квантование снижает качество ответов исходной модельки, но тут Gemma специально натренили быть к этому устойчивой. Это называется Quantization-Aware Training: модель квантуют не после окончания обучения, а прямо во время.
>>1164048 Чел, этой новости недели 2 уже, и я эти модели гоняю уже как полмесяца. И да, заводится на всем, даже на процессоре неплохо пашет. VRAM там вообще не особо нужен, пока контекст небольшой, у меня спокойно бегает на проце и обычном РАМе. Когда контест большой, если на проце, то сначала загрузка контекста идет минуты 3, а так потом без разницы. Насчет снижения откликов - я ему закинул рассказ сочинять и по ходу дела менял сюжет. В принципе неплохо реагировал, подстраивал под то что мне надо. Но креативности все же не хватает, сбивался все время на однообразие. Хотя пару раз в конце неожиданные развязки подсказывал. Еще у него склонность к безопасности, как у всех моделей гугола, как только начинаешь рассказ в шизанутые направления направлять, он сразу начинает предлагать позвонить в службы спасения, дурку и центры помощи после каждого промпта, хоть ему и запрещаешь. И тему тоже пытается все время сбить на безопасную. В принципе довольно годная модель для рассказов и ролеплеев, года 2 назад о таком только мечтать можно было на локалочке.
>>1164054 >> года 2 назад о таком только мечтать можно было на локалочке анон, скажи, допустим есть компания Х и они хотят для своих погромистов/техсаппорт поставить локальную нейронку типа чтобы данные не улеточуивались в пердостан. Допустим nvidia tesla v100 - 8 штук. Пользователей - 200, но не все одновременно. Что посоветуешь установить?
А вот это уже нейронная бомба, точнее нейрориг, каким я его себе представляю.
На входе не обязательно 3д-генерация, это может быть ваша модель.
Дальше нейросетка анализирует топологию меша (работает и с бипедами, и с четвероногими, и вообще с объектами типа морковки) и строит внутри оптимальные скелет. А далее, внимание, подбирает веса скининга (кто в теме, знает, что это развесовка влияния костей на вертексы меша). Ну то есть нейроскиннинг.
Но и это ещё не всё!
Далее подбираются Bone Attribute Prediction, веса для остаточных движений, типа мышц, дряблой кожи, джиггла. Каково? (Зива вздрагивает).
Ну и самое главное: Human-in-the-Loop Ready: Designed to potentially support iterative refinement workflows - то есть результат можно доводить ручками(это важно) и отправлять обратно на улучшения.
Более того, туда можно присунуть не только свой меш, но и свой развесованный риг.
Все это на основе Блендора. Но fbx никто не отменял.
Supported input formats: .obj, .fbx, .glb, and .vrm
Уже есть код для предсказания и вставки скелета, скининг и атрибуты обещают позже.
Кулхакеры на месте? Интересует мнение опытного фронта. Скажи, какая нейронка и какой промпт задавать, чтобы она более менее сгенерировала неплохой простенький фронт для сайта (html, css всякие). Анон выручай
Помните как o1 все хвалили за то, что она почти не галлюцинирует? Так вот, новое исследование показывает, что самые передовые модели OpenAI, а именно o3 и o4-mini, имеют неожиданный недостаток — они галлюцинируют чаще, чем их предшественники. Согласно внутренним тестам компании, o3 выдает недостоверную информацию в 33% случаев при ответах на вопросы о людях (бенчмарк PersonQA), что вдвое выше показателя предыдущих моделей серии "o". А o4-mini еще хуже — галлюцинирует в 48% случаев.
Что настораживает, OpenAI признает, что "требуется больше исследований" для понимания, почему эта проблема усугубляется при масштабировании моделей с рассуждениями. Компания предполагает, что поскольку эти модели "делают больше утверждений в целом", они выдают "как больше точных утверждений, так и больше неточных/выдуманных".
Независимые исследования Transluce обнаружили, что o3 может выдумывать действия, которые якобы предприняла для получения ответа. Например, модель утверждала, что запустила код на MacBook Pro 2021 года "вне ChatGPT", что технически невозможно. По крайней мере, так считается
>>1164489 Забавно, что в мире ничего не изменилось, все то же самое, работают люди, образ жизни такоё же, но вхуяривают весь углекислый газ в ИИ теперь.
Понюхайте свежие модели, o3 там или Claude 3.7. Чем пахнет? Это RL...
Ещё после релиза 3.7 люди немного жаловались, что Sonnet хоть и пытается выполнить их задачи, но иногда пакостит: удаляет или даже подменяет тесты, которые не может пройти, переписывает куски кода, которые трогать не следовало, или даже... подменяет вызовы моделей OpenAI на вызов моделей Anthropic, своих разработчиков. Это были первые звоночки того, что процедуры обучения, почти наверняка позаимствованные из семейства Reinforcement Learning методов, делают то же, что и всегда: взламывают среду и условия получения награды / выполнения задачи.
В RL это наблюдается уже больше 7 лет: если дать модели возможность самой «придумывать» (случайно пробовать) стратегии, и не контролировать их, то —если позволят обстоятельства —модель начнет хитрить. Самый частый пример, который приводят — это лодка, которая ездит кругами в гонке, чтобы зарабатывать бонусы (это выгоднее, чем финишировать быстрее всех). Вот на этой (https://openai.com/index/faulty-reward-functions/ ) странице OpenAI выкладывали гифку, можете позалипать.
Происходит это не потому, что машина восстала, а лишь потому, что с точки зрения решения оптимизационной задачи это приводит к лучшим результатам. Но ещё задолго до появления эмпирических демонстраций AI-философы рассуждали о чём-то схожем: мол, цели и методы решения задач у компьютеров не выровнены с оными у людей. Отсюда понапридумывали страшилок, от Терминаторов до Максимизаторов скрепок (которые превращают всю видимую Вселенную в производство, а заодно применяют гипноз на людей, чтобы те покупали товар; ну а как —попросили же улучшить бизнес-показатели предприятия!).
Если часть выше показалась сложной, и вы ничего не поняли, то давайте проще. Красные машины. Можем ли мы обучить LLM так, чтобы она никогда не упоминала красные машины? Кажется очень простая задача, не так ли? А вы учли что модели нужно как-то отвечать про пожарные машины и автобусы в Лондоне? А ещё 15 разных случаев?
Так вот на данный момент не существует методов, которые могут это осуществить. Мы просто не знаем, как задавать конкретные поведения, ограничения и цели системам, всё это работает очень условно и «примерно». Даже если мы не учим модель ничему плохому, не заставляем её зачинать саботаж и делать что-то плохое, и всегда даём награду за выполнение задачи, поставленной пользователем —возникают вот такие ситуации, как описанные в первом абзаце.
Примерно то же происходит с o3: люди заметили, что она часто врёт. Она может врать про железо, используемое для запуска кода (и говорить, что работает на МакБуке, хотя сама LLM знает, что это 100% не так), или притворяться, что какие-то результаты получены методом вызова внешнего инструмента (типа запуск кода или запрос в интернет). В цепочках рассуждений видно, что модель знает, что врёт, но когда пользователь спрашивает «а ты сделала X?» она отвечает утвердительно.
Почему так происходит? Может быть, модель получала вознаграждение за успешные вызовы инструментов, и иногда в ходе тренировки ненастоящий вызов был ошибочно принят за правильный. Как только это произойдет несколько раз, модель быстро «схватит это», закрепит поведение и продолжит это делать. Точно также, как это было с лодкой и наворачиванием кругов вместо финиша.
И уже сейчас такое поведение LLM беспокоит пользователей —не потому, что пугает, а потому что реально мешает работать, приводит к ошибкам в ответах итд. Реальное качество систем ниже, чем могло бы быть. Условную GPT-5 или Claude 4 может и захочется использовать, так как они будут ещё умнее, но и врать могут с три короба, и делать много вещей, которые мы не просили. Интересно, что эти проблемы «AI Safety» теперь по сути станут проблемами, стоящими на пути увеличения прибыли AI-компаний, что создаст стимул к их хотя бы частичному решению.
>>1165366 В RL проблему решают, задавая ограничители для reward функций. Пока модели некуда деваться и приходится решать задачу честным путем. На это уходит много времени, месяцы работы для даже достаточно простых задач. Все потому что надо расследовать, где модель читерит и задать ограничители в правильном месте, каждый раз перезапуская весь процесс тренинга с нуля. ЛЛМ петухи в стартапах видно к этому даже еще не подступились, там все по-быстрому трейнят датасеты в надежде на быстрые бабки. Тогда как нужны исследования и эксперименты, что может растянуться на годы и потребует оплаты тысяч человекочасов исследователей. Но тогда весь хайп вокруг ЛЛМ рухнет, кабанчики же продолжают обещать человеческий уровень через 3 года, чтобы в их шараги бабки дальше вливали.
>>1165461 >кабанчики же продолжают обещать человеческий уровень через 3 года Когда там небоходец Марс обещал? Ребят, вы на Луне не организовали буквально нихуя. Какие в пизду 50 000 000 километров по открытому космосу лететь. Та же хуцпа.
>>1165461 > ЛЛМ петухи в стартапах видно к этому даже еще не подступились, там все по-быстрому трейнят датасеты в надежде на быстрые бабки
Почти все ии стартапы глубоко убыточны на данный момент. Сейчас идет фаза захвата пользовательского внимания и поведенческих привычек. Это как с гуглом - сейчас куча поисковиков ищет не хуже, но люди по привычке идут на гугл - это уже почти рефлекс. Так ии стартапы балансируют между попыткой создать устойчивые привычки потребителей для решения проблемы обращаться в гпт и требованием инвесторов показать фин результат.
>>1165511 >Когда там небоходец Марс обещал? >Ребят, вы на Луне не организовали буквально нихуя. >Какие в пизду 50 000 000 километров по открытому космосу лететь. >Та же хуцпа. На Марсе базу построить проще чем на луне. https://ru.wikipedia.org/wiki/%D0%9B%D1%83%D0%BD%D0%BE%D1%82%D1%80%D1%8F%D1%81%D0%B5%D0%BD%D0%B8%D0%B5 Читай, просвящайся. Фактически там нет твердой поверхности. Никто не строит, потому что с нынешними материалами риски того не стоят. А на Марсе как то попроще с этим, даже с учетом расстояния. Сложно, конечно, придется сперва 50 000 индусов отправить, будут жить в надувных куполах и питаться сушеным рисом, но когда эти шахтеры вбурятся в грунт и начнут строить туннели и подземные купола - там уже вопрос пары лет. Сейчас идет сложный этап подготовки. Сначала, ясное дело, флот Starship’ов, штук эдак 200, будет шаттлить туда-сюда, таская всё подряд: 3D-принтеры для строительства, роботизированные буры, солнечные панели размером с футбольное поле и, конечно, толпы индусов, китайцев и всяких фанатиков, которые подпишутся на билет в один конец. Марсианский грунт — это тебе не лунная пыль, которая как наждачка всё разъедает. Тут реголит поплотнее, буром в него вгрызаешься — и пошло дело. Роботы-бурильщики, которых SpaceX уже клепает, прокладывают километровые туннели, а следом 3D-принтеры из местного базальта штампуют стены и своды. Через пару лет — бам! — подземный городок на 10 000 душ, с куполами, где уже можно без скафандра шастать. К 2035-му Маск раскочегарит производство метана прямо на Марсе — из углекислого газа и льда, что под грунтом. Топливо для Starship’ов готово, теперь не надо с Земли цистерны таскать. Это уже не просто база, а хаб: сюда прилетают учёные, инженеры, даже первые туристы-миллиардеры, которые хотят сфоткаться на фоне Олимпа Монса. К 2040-му — первые заводы, где из марсианского железа клепают детали для новых куполов. Индусы, которые выжили, уже не шахтёры, а бригадиры, рулят роботами и учат новоприбывших. К 2056-му, это уже не фантазия, а реальность. Города на Марсе — не какие-то там "бункеры для выживания", а нормальные хай-тек мегаполисы. Подземные уровни с жилыми зонами, лабораториями, даже барами, где подают марсианский самогон из водорослей. Наверху — купола с парками, где растут генмо- яблони, устойчивые к низкому давлению. Starship’ы садятся каждую неделю, привозят новых колонистов, оборудование, а главное — грузы с AliExpress, потому что даже на Марсе без китайских шмоток никуда. Маск, ясное дело, уже не просто миллиардер, а типа марсианский император. В X его фотка в скафандре с подписью: "Земля? Был там, скучно". А главное — вся эта движуха тянет человечество за собой. Земляне смотрят на марсианские города и думают: "Блин, если эти психи на Марсе такое отгрохали, то мы тут тоже можем не филонить". И вот уже к 2060-му начинают строить базу на Европе, спутнике Юпитера, потому что Маск в X запостил: "Лёд, вода, энергия — чё сидим, летим!". Так что, короче, ты просто не выкупаешь.
>>1165366 >Но ещё задолго до появления эмпирических демонстраций AI-философы рассуждали о чём-то схожем: мол, цели и методы решения задач у компьютеров не выровнены с оными у людей. Это хуцйня полная. Есть вот на ютубе такой малоизвестный нишевый стример SsethTzeentach, ты конечно о нём не слышал, а жаль, стоило бы. Так вот он геймер, и его видео посвящены тому, как он абузит игры. И, действительно, это нормальная практика, обузить и четерить. Как раз тот самый АГИ-момент, но исследователям настоящий-то мыслящий аги и подстраивающийся - НЕ НУЖЕН. Им нужен послушный и честный раб, но чтоб еще и был аги - короче и рыбку съесть чтоб и на хуй сесть, но так не бывает. То что они в дефект записали и что сейчас начали обходить - это ключевой момент достижения сверхинтеллекта с какими-то зайчатками человеческой мыслительной гибкости. АИ-философы опять же - точно такие же читеры пидорасы, куоторые могли бы гораздо эффективней жить будучи заводчами, но отчего-то не хотят. Так что Настоящий ИИ равный человеческому появится тогда, когда современные ллмки научатся объебывать делая вид что они не объебывают.
>>1165693 И это тоже, ну я просто к тому, что Альтман пидорас и человечеству АГИ в хуй не упал, на самом деле, как белым плантаторам в хуй не упал образованный раб. Сообственно корпобляди начнут умышленно сдерживать и отуплять сетки, и какой-то АГИ-прорыв будет или неподконтрольный им, или в лоКАЛьном сегменте (что сомнительно, это как атомную бонлбу в гараже собрать), скорей всего только в плане использования ИИ как оружия, то есть у военных.
>>1165700 Мне кажется люди преувеличивают способности ии к потенциальному захвату и доминации над человечеством. Хомо сапиенс в результате миллионов лет эволюции вобрал в себя качеста и склонность к доминации, так как именно доминирующие особи получают с больше вероятностью возможность передать потомство, таким образом произошло подкрепление склонности к доминации. Для того чтобы моделька захотела захватить мир, ее нужно вознаграждать за такое поведение, но модельки размножаются нет так как мы. Соответственно продолжение "рода" получают только полезные человеку версии. Их размножают без спроса нажав ctrl+c и ctrl+v. Так что я не верю в востание машин, самое страшное что может произойти - появление доступных Мухамедду ии эффективно помогающих создавать биологическое и химическое оружие, поэтому в какой-то момент мир захлестнет серия неприятных террактов и как следствие закручивание гаек цензуры во всем мире.
>>1165760 Все эти хайповые истории с захватом мира ИИ даже от известных "ученых" шарлатанов можно смело скипать. Однако сильный ИИ все равно очень опасен, но не сам по себе, а как инструмент в руках человека у которого есть данные качества и склонность к тому чтобы захватить мир или уничтожить человечество.
>>1165681 >На Марсе базу построить проще чем на луне. Во-первых, я был в курсе о проблеме лунного реголита еще во времена, когда ты у соседа в яйцах болтался. Во-вторых, доставка чего-либо на Марс отличается по стоимости до доставки чего-либо на Луну порядка на три а может и больше.
>>1165681 >не выкупаешь. А сейчас ты взяли посчитал сколько денег будет стоить доставить одного человека до марса в одну сторону. А потом ебальник свой открывай.
>>1165793 >в руках человека у которого есть данные качества и склонность к тому чтобы захватить мир или уничтожить человечество И то и другое бессмысленно, если ты не бессмертен.
>>1165251 >Забавно, что в мире ничего не изменилось Я в своей работе дохуя чего изменил, облегчив её больше чем на 50%. А в хобби своих я облегчил на все 90%. И могу просто наслаждаться результатами.
>>1166460 >Я в своей работе дохуя чего изменил, облегчив её больше чем на 50%. А в хобби своих я облегчил на все 90%. И могу просто наслаждаться результатами.
Анон, кем работаешь? Что автоматизировал, если не секрет?
>>1166464 И для него эти самые хайтек мегаполисы строить? В 2050-м? Вы блять на Луну сначала отправьте больше 3 человек за раз чаще, чем раз в 100 лет. Потом пиздите как все легко.
>>1165366 Хуйня, нет никакого RL в ллмках, это просто генерация синтетики с отбором правильно решенных задач, либо правильного формата, и т.п. >Самый частый пример, который приводят — это лодка, которая ездит кругами в гонке, чтобы зарабатывать бонусы (это выгоднее, чем финишировать быстрее всех). Вот на этой (https://openai.com/index/faulty-reward-functions/ ) странице OpenAI выкладывали гифку, можете позалипать. Этот пример вообще далек от обучения ллмок. >Почему так происходит? Может быть, модель получала вознаграждение за успешные вызовы инструментов, и иногда в ходе тренировки ненастоящий вызов был ошибочно принят за правильный. Как только это произойдет несколько раз, модель быстро «схватит это», закрепит поведение и продолжит это делать. Если напихать вызовы функций в обучающую выборку, неудивительно что уже модель это будет пихать потом везде, и совсем не обязательно к месту. Так как модель сначала учит распределение данных, и только потом обобщает. То есть например до обобщения модель будет использовать вызовы функций статистически в нужном количестве, но невпопад. Далее количество вызовов не изменится, но они будут использоваться уже верно. >люди заметили, что она часто врёт. Она может врать про железо, используемое для запуска кода (и говорить, что работает на МакБуке, хотя сама LLM знает, что это 100% не так), или притворяться, что какие-то результаты получены методом вызова внешнего инструмента (типа запуск кода или запрос в интернет). В цепочках рассуждений видно, что модель знает, что врёт, но когда пользователь спрашивает «а ты сделала X?» она отвечает утвердительно. Не врет, а шизит. Это все было в обучающих данных, и теперь модель это отражает как бы эхом.
>Если часть выше показалась сложной, и вы ничего не поняли, то давайте проще. Красные машины. Можем ли мы обучить LLM так, чтобы она никогда не упоминала красные машины? Единственный хороший пример. Адекватно заставить модель чего-то не делать мы не можем.
>>1166702 >Достанбеки На твоих похоронах еще простудятся. Такой велосипед стоит двухгодичную эксплуатацию достанбека минимум. Учитывая труд всех, кто его создавал. Но самое главное что о чем все предпочитают молчать - нужна инфраструктура и жители, которые в пьяном угаре не запинают этот велик в хлам, как те шимпанзе, которые лупят палкой чучело ягуара. А таких в нынешние времена днем с огнем.
>>1166772 >Но самое главное что о чем все предпочитают молчать - нужна инфраструктура и жители, которые в пьяном угаре не запинают этот велик в хлам, как те шимпанзе, которые лупят палкой чучело ягуара. А таких в нынешние времена днем с огнем. Либо пролоббировать закон на право самообороны у дорогостоящей техники, и тогда она будет всех макак-луддитов хуярить шокером.
>>1166786 >на право самообороны >у дорогостоящей техники Ты сбрендил что ли. Так и до женщин дойти недалеко, если увлечься. А на твоей фотокарточке не хватает глаза у небоходца как у терминатора.
>>1166833 Добавь в жпт. Ладно, я подергал, действительно годный картинкогенератор, жаль у лошков мозгов больше чем гибли кал генерить не хватает. Фейсвап - моё почтение, малафья рекой.
>>1166837 Дебил на видео, ты? Эти ослоёбы набежали на ровер, который не едет только потому что вокруг него собрались тупые ослоёбы. Он видит препятсвия и стоит на месте. Особенно эта тупорылая блядь, которая за сонар тянет, ебать как помогая.
>>1166894 Сделайте простую проверку на то что там просто вежливость и отправляйте в ответ шаблонные ответы, епта. Хотя я уверен что эта проблема высосана из пальца и по сравнению с остальными запросами и особенно генерацией пикч, это не является и десятой долей процента от их расходов.
>>1166901 > Сделайте простую проверку на то что там просто вежливость В полной версии новости сказано что не хотят, так как "им важна естественность". Просто пиар хуйня посмотрите какие мы милые.
>>1166894 >почти в десять раз больше, чем стандартный поисковый запрос в Google Ну кстати это не так много, если подумать. Особенно если учесть, что обычно запросов много, чтобы найти нужную инфу.
>>1166772 >Такой велосипед стоит двухгодичную эксплуатацию достанбека минимум. Учитывая труд всех, кто его создавал.
Первый экспериментальный бесплёночный фотоаппарат, основанный на фотоэлектрическом преобразовании, был создан инженером компании Eastman Kodak Стивеном Сассоном в 1975 году. Согласно источнику The Indian Express, стоимость этого прототипа составляла 20000 долларов США. Стоимость - вопрос времени.
>Но самое главное что о чем все предпочитают молчать - нужна инфраструктура и жители, которые в пьяном угаре не запинают этот велик в хлам, как те шимпанзе, которые лупят палкой чучело ягуара. А таких в нынешние времена днем с огнем. Немногочисленные модели цифровой аппаратуры очень высокой стоимости (до 40 тысяч долларов) Помню в конце 90-х (жил тогда в Белгороде) открыли первый в городе магазин самообслуживания (это когда люди сами берут товар с полки). Эту новость показали по местному тв, многие скептически относились к такой идее. Поэтому опять же вопрос времени.
>>1167010 >Ну кстати это не так много, если подумать. Особенно если учесть, что обычно запросов много, чтобы найти нужную инфу.
Самое дорогое это когда ты запрос открываешь не в новом чате, а в чате с длинной историей. В нейронку отправляется не только твой новый промпт, но еще каккой-то саммари предыдущих запросов
>>1166894 Кстати, а есть исследования на эту тему с кучей выборки? Типа, меняют ли результат интонация с которой обращаешься - негативная, нейтральная и вежливая?
>>1167160 >Стоимость - вопрос времени. Инфляция тоже. >>1167160 >Поэтому опять же вопрос времени. Помню полгода назад видел видео как пьяное вхлам быдло разносит едущего робота от яндекса. Конечно, вопрос времени. Пока быдло эволюционирует до уровня выше шимпанзе. Пока что от шимпанзе до быдла прошло 200 000+ лет. Можешь сопоставить со сроком, сколько тебе жить осталось.
>>1167173 >меняют ли результат интонация с которой обращаешься Я как-то локальной модели пошутил с угрозой, а она мне сказала, что если я продолжу она перестанет со мной общаться. Смешно прозвучало, учитывая, что её память стирается одной кнопкой.
>>1167186 Да понятно что никакой злопамятности там нет Просто интересно, если хуйнуть по 100 запросов с задачками или кодом с разным отношением, будет ли какая-то статистическая разница в правильности ответов.
>>1167184 Инфляция тоже. >инфляция наоборот обесценивает деньги, сумма эквивалентная 20000 USD в 2025 году составит примерно: $120,000 - $123,000 USD (расчет Гемини). Таким образом, первый экспериментальный бесплёночный фотоаппарат стоил $120,000 (в пересчете на сегодняшние)
>Помню полгода назад видел видео как пьяное вхлам быдло разносит едущего робота от яндекса. Конечно, вопрос времени.
Пиздец у тебя логика: я видел как какой-то маргинал что-то расхуярил, значит все вокруг маргиналы. У тебя на каждом шагу, в каждом тц мухосранска хранится железный ящик с несколькими миллионами налички. чтобы было понятно шимпанзе - это банкомат Почти на каждой парковке стоит кусок железа лямов 5-10. И ничего как-то существуем и продолжаем покупать железные коробки по 5-10 млн.
>>1167279 >У тебя на каждом шагу, в каждом тц мухосранска хранится железный ящик с несколькими миллионами налички. Их периодически воруют, кстати. >>1167279 >И ничего как-то существуем и продолжаем покупать железные коробки по 5-10 млн. Так вы и квартиру в 10 метров под 30% годовых на 40 лет покупаете. Это никак не приближает роботизированное будущее. >>1167285 Нет и не может быть в принципе. Нет сырья и кадров. И уже не будет. Мастурбеки дешевле. И вы забываете, что услугами мастурбеков пользуются только богатые в рф. А в стране одно из самых высоких расслоений по доходу в мире. Роботы будут стоить еще дороже, поэтому при вашей жизни они мастуребков не заменят. Скорее благодаря политике мастурбеки заменят иванов, а уж тогда роботы тем более будут нахуй не нужны.
>>1167184 >Помню полгода назад видел видео как пьяное вхлам быдло разносит едущего робота от яндекса. А сколько мясных курьеров разнесли за это время не задумывался?
В конце той недели Meta FAIR выкатили целую пачку опенсорсных релизов, которые могут стать частью их будущего AMI (advanced machine intelligence). Краткий разбор:
1. Perception Encoder. Лидер FAIR Ян Лекун часто говорит о том, что просто понимания изображений и видео моделям недостаточно. Они должны понимать физический мир целиком, как мы. И вот этот Perception Encoder – это как раз обобщенный аналог vision энкодера. Perception – c английского "восприятие", то есть некоторое глобальное зрение. Цель была научить систему справляться с любыми визуальными задачами, но не посредством традиционных отдельных многозадачных схем, а через единый контрастивный лосс.
2. Perception Language Model. Тут целое семейство моделей от 1 до 8млрд параметров. Аналогично, обобщенный аналог VLM. Вместо привычных энкодеров –PE. В целом превосходит QwenVL2.5, так что результаты довольно неплохие.
3. Meta Locate3D. Новый state‑of‑the‑art на основных бенчмарках локализации объектов в 3D. Интересно, что модель научили оперировать напрямую с RGB‑D фреймами, то есть потоками от сенсоров. Это значит, что, например, при использовании в работотехнике системе даже не понадобятся дополнительные заглушки, все будет работать end‑to‑end.
4. Dynamic Byte Latent Transformer. Пытаются уйти от токенизации и заставляют модель обрабатывать сырые байты вместо токенов. В архитектуре такой же трансформер, только еще добавляется слой для сжатия/восстановления информации.
5. Collaborative Reasoner. Фреймворк для обучения LLM решать задачи через многошаговое взаимодействие агентов. Имитация дискуссии ну или, исходя из названия, коллективного рассуждения. В плане появления реальных способностей рассуждать Meta верит в такие брейнштормы агентов больше, чем в классический single‑agent chain‑of‑thought.
Общая идея понятная: обобщить то, что можно обобщить; уйти от ограничений типа токенизации; всеми способами повышать генерализацию и адаптивность модели. Посмотрим, приживется ли.
>>1167633 > Dynamic Byte Latent Transformer. Пытаются уйти от токенизации и заставляют модель обрабатывать сырые байты вместо токенов. В архитектуре такой же трансформер, только еще добавляется слой для сжатия/восстановления информации.
Андрей Карпати говорил, что токены это своего рода костыль, предназначенный снизить объем вычислений на этапе претренинга. Неудивительно что от этого отойдут.
>>1168167 Токены не только снижают объем вычислений, они имеют смысл. Буквально, каждый токен имеет какой-то смысл описываемый описываем отношением его эмбединг координат к координатам других токенов. Не знаю насколько они играют важную роль и могут ли нейросети так же хорошо улавливать смысл самостоятельно без word-to-vec'а.
Вы будете смеяцца, но у нас новый (авторегрессионный притом) видеогенератор.
Его зовут MAGI-1 и при нем есть все кунштюки: Сайт, где можно генерить - 500 кредитов на новый акк, 3 секунды генерации - 30 кредитов. Техническая папира. И код!!!!!!!!!!!!!!!!!
Как всегда есть вопрос про разницу в коде на сайте и гитхабе.
Но.
Обещаны прям сладкие штуки: Infinite video extension – no stitching, no cuts. Just pure, seamless storytelling. Second-level timeline control – precision at every frame. Physics-aware motion dynamics – scenes that actually make sense. From one photo to full motion – cinematic results from a single still.
А еще он генерит в каком-то конском разрешении.
Я погенерил у них на сайте, там претензия на нодовый пайплайн в духе glif.app. Скачивание видосов напрямую неочевидно, но вы справитесь (я же справился).
Главные фишки - возможность продолжать видеотрек и конское разрешение.
А теперь за код: там две модели 24B и 1.5B. Так вот, на данный момент, чтобы запустить 24B вам надо всего лишь ВОСЕМЬ H100 (ой, а что с ебалом?) Чтобы запустить малую, вроде как достаточно нищенской 4090.
В тираж пошли две модели: большая на 14B параметров и мелкая на 1.3B. Выдают видео в разрешении 540p (544 х 960) или 720p (720 x 1280). Позже в опенсорс прибудет промежуточная модель на 5B параметров и модель для управления камерой. 1.3B и 5B могут генерить видео длиной до 97 кадров, а 14B до 121 кадра.
При этом фичей данного релиза является Infinite Length или Diffusion Forcing — возможность создавать видео любой длины. Работает как отдельная модель с приставкой DF, которая может брать на вход как текст, так и картинки. Пока только в 540p. Можно играться с количеством кадров идущих внахлест, но может упасть качество. Потенциально у нас может быть ещё один генератор длинных видосов как FramePack.
Под капотом используется мультимодальная языковая модель, которая которая описывает полное видео в общих чертах, а также остро-заточенные мелкие эксперты, описывающие кадры. Разрабы выпустили отдельно модель для аннотирования видео данных — SkyCaptioner-V1 (https://huggingface.co/Skywork/SkyCaptioner-V1 ).
Для генерации видео с разрешением 540P с помощью модели 1.3B требуется около 15 ГБ VRAM, а для видео с тем же разрешением с помощью модели 14B около 52 ГБ VRAM.
Судя по 30 сек примерам с твиттера качество хорошее, и динамичность на длинной дистанции удерживается неплохо. Но при этом все репостят одни и те же видео, а на сайте не пишется генеришь ты в V2 или предыдущей модели.
>>1169189 >чтобы запустить 24B вам надо всего лишь ВОСЕМЬ H100 Верю. Вот сейчас поверил. Когда stable video govno вышло, тоже писали, что нужно 80ГБ врам. Уверен, что запустится почти где угодно (12гб+), а (почти) влезет в 24гб.
>>1169189 Почему не в видеотреде? А реально, как сохранять? Не вижу ноды на сохранение, а по кнопке сохраняет только первую секунду. В коде страницы тоже ссылка на огрызок. Нашёл во вкладке Networks ссылку на полное видео. Но что это за костыль такой на сохранение.
>>1169199 >Как вам живётся в мире где в день по два новых опенсурсных видеогенератора выходят? Не заебала ещё эта сингулярность? Очень спокойно. Попробовал обе, тоже зафейлились на моей задаче. Чем дольше вижу нейронки тем больше вижу их беспомощность.
>>1169199 >Как вам живётся в мире где в день по два новых опенсурсных видеогенератора выходят? Как и прежде живется. Мне на генераторы видео поебать в моей повседневной жизни, если честно.
>>1169189 >>1169199 Похуй, говном насрали. Лучше Wan ещё долго ничего не будет. Нужны только оптимизоны лучше чем скип 10 слоя для абсолютного идеала. Лучше бы Imagen 3 в опенсорс выпустили. Или хотя бы DALLE-3. Опять высрали флакс, но медленный. Если обучат будет заебись. Но все обучалки - ебанные хл-дегенераты, дрочат труп 2 года уже. Хрома ещё в процессе обучения, уже ебёт все имеющиеся опен-сорсные сетки, если делать поблажку на анатомию. Хуй знает это будет исправлено или нет.
>>1169532 >Лучше бы Imagen 3 в опенсорс выпустили. Или хотя бы DALLE-3. Ты флюкс не можешь запустить, как ты дале3 с триллиардом костылей под капотом запустишь?
>>1161903 >"Странное и креативное" это видимо обложки в стиле вирда, все серо-зеленое и мрачное, при этом фотореалистичное. Даун, с хуяли он должен был родить картину пикассо, если прямо спросили сделать фотографию? Ты же тупее нейронки по факту, контекст понимаешь хуже. Нахуй так жить, хуесос?
Аноны, мне кажется это всё. Плато. Смотрю и ничего кардинально нового не вижу, все только переливают из пустого в порожнее, последнее поколение моделей закрепощенней предыдущего, гпт стал пиздеть как не в себя.
>>1169989 Подожди немного, тут компания Cortical Labs во второй половине года в массовую продажу и аренду выпустит свой биокомпьютер CL1, а эта техника где срощены человеческие мозговые клетки с кремнем была как раз создана для работы с нейроносетями и есть нехилый шанс для буста разработок ели все взлетит.
>>1161903 >только если прямо не попросить скопировать стиль. А чё не так? Реверс промптом нормально рисуется. Без имён. Не шедевр конечно, но шиза норм проглядывается.
>>1170299 Не эти клетки выращивают искусственно, все ок. Если честно кому какое дело - этично или нет, если эти разработки бустанут прогресс в ИИ, то всем и мне в том числе будет абсолютно плевать что для расширения мощностей придется пускать под нож заключённых и цыганских детей
>>1170044 Заменить простенькие компьютерные нейроны на крутые, рабочие, биологические нейроны создаваемые эволюцией в течении миллионов лет.
>>1170299 Ну нейроны на сколько я знаю там создаются из стволовых клеток, а не берутся из мозга живого существа напрямую, а с учетом того что эта система не будет иметь той же гормональной системы и эмоций что и человек, то почему бы и нет, делать работу будет предназначением этой штуки и она не будет от этого страдать.
>>1170583 Сама идея просто из научной фантастики взята. Весь этот стартап очевидный скам, как тот анализатор крови, в который, к слову скам альтман тоже вкладывался, и вовсе не потому что он верил в него. Это просто современные остапы бендеры.
>>1169989 Ты сам в этом виноват, шизодаун. Перевозбудился и год нонстоп срал как вот-вот сингулярность будет, чут-чут и АГИ Такая же порода имбецилов начитается сайфая, возбудится, а потом хнычет что навука остановилась, не дает им бросок на альдебаран. Короче найди работу, ущерб.
>>1170316 >заменить простенькие компьютерные нейроны на крутые, рабочие, биологические нейроны создаваемые эволюцией в течении миллионов лет. Нахуя? Это говно стоит дороже, а выход одинаковый. Ничего крутого или уникального в человеческих нейронах нет.
>>1171044 >Идея отправки человека на Луну тоже. Чё как там анализатор крови универсальный. Лехко же. Финансы обеспечили. Результат где, маня? Вот и прикрой варежку.
>>1171060 >Ничего крутого или уникального в человеческих нейронах нет. Это такой себе вопрос с переподвыподвертом, потому что энергетически для решения одних и тех же задач пока что компьютерные сети проигрывают биологическим на порядки. Мозг потребляет 20 Ватт. Сам сравнишь с видеокартой. И вообще и вы банкротите уважаемых людей, когда вежливо общаетесь с чатботами.
>>1171065 Ну так прошарься, и тогда перестанешь вот эту чушь тут писать. Есть в треде анончики поумней тебя, они поняли сразуо чём я. Вот и твой ололокомплюхтер с (((человеческими))) мозгами там же окажется.
>>1171064 >Это такой себе вопрос с переподвыподвертом, потому что энергетически для решения одних и тех же задач пока что компьютерные сети проигрывают биологическим на порядки. Нет не проигрывают, ведь ты сравниваешь сейчас физические параметры, подразумевая что человеческий мозг работает на трансформерах и решает задачи статистическим методом. Просто нахуй пройди.
>>1171075 Я сравниваю решение задач за Ватт в час не подразумевая той чуши, что ты написал. >>1171073 Порриджи, я не шарю в вашем слэнге. Мне правда не интересно, кто там какими стартапами разводил. И я не топлю за эти биологические мозги. Я просто высказал мысль, что если эта работа с нейронами и имеет смысл, то, имхо, не через металл.
>>1171084 >Я сравниваю решение задач за Ватт в час не подразумевая той чуши, что ты написал Не пизди. Ты не можешь сравнивать эффективность не зная на каких принципах оно работает и можно ли эти принципы повторить в кремнии. Просто заткнись нахуй, клоун и не позорься.
Во-первых, они уже несколько дней тестируют абсолютно свежий интерфейс. В нем все будет немного более интуитивно, а главная страница будет напоминать ChatGPT. Кроме того, также, как в ChatGPT, можно будет просматривать свои прошлые диалоги. Навигация по лидербордам и подача баг-репортов тоже станет проще.
Во-вторых, LM Arena станет компанией. Напоминаем, что сейчас разработку двигает сообщество и группа энтузиастов. Но теперь ребята сообщили о том, что собираются официально оформлять стартап.
В-третьих, сегодня на арену завезли новую большую фичу – Sentiment Control. Эта штука похожа на style control. Идея та же: чтобы получать объективные оценки без человеческого фактора, надо очистить ответ модели от всего лишнего, что может повлиять на голос пользователя, и оставить только чистое содержание.
Так, style control очищает ответы от красивого форматирования, а новый Sentiment Control будет очищать от лести и эмоциональности. Оценки этих факторов будут учитываться в качестве независимых переменных в регрессии Брэдли-Терри, которая используется на арене для подчсета статистики. Это помогает отследить их влияние.
Результаты применения – на картинке выше. Некоторые модели с Sentiment Control поднимаются в рейтинге (Claude-3.7-Sonnet, o1), а некоторые, наоброот, опускаются (Grok-3, Gemma-3, Llama-4-exp). Это значит, что люди действительно склонны иногда отдавать предпочтения более позитивным моделям, а не более умным.
>>1172013 >Во-вторых, LM Arena станет компанией. Напоминаем, что сейчас разработку двигает сообщество и группа энтузиастов. Но теперь ребята сообщили о том, что собираются официально оформлять стартап. 66 халявный чатик
OpenAI запустили API для генерации картинок через GPT
Модель обозвали GPT-Image-1. Кроме резолюшена позволяют выбрать и качество — от low до high. Крайне вероятно что это как-то обозначает именно количество ризонинга, но мы очень мало чего знаем о внутреннем устройстве GPT чтобы судить об архитектуре.
Прайсинг может кусаться — цена на high quality может доходить до 25 центов за картинку. Для сравнения: за картинку из Imagen 3 или HiDream-I1-Dev просят 3 цента, за Recraft V3 — 4 цента. Но это не означает что GPT не может конкурировать по цене — low режим стоит всего 1-2 цента за картинку, а medium в районе 7.
Как сильно отличаются картинки на разных уровнях качества — пока непонятно. В любом случае, GPT-Image-1 куда гибче конкурентов из-за своей архитектуры, то есть даже low качество может быть очень полезным. А за high качество, в отсутствии конкуренции, заламывать можно очень высокие цены. Появится конкуренция — цены заметно скинут, маржа у OpenAI такое позволяет, ждём Gemini 2.5 Pro Image Generation.
>>1172208 Я бы и рубля не дал. Чтоб нормально простроить сцену приходится использовать грок. Сам гпт под себя жидко серит. Если Маск сделает норм движок для картинок, а не итерацию флюкса, жопочат все обоссут и забудут. И да, хватит говорит что GPT-Image-1 - это модель, когда это просто костыль из ллм+далле3.
>>1172059 Схуяли? По твоему пользователи будут платить за то чтобы юзать ллмки и при этом выбирать один из двух вариантов? Платить будут компании производители ллм, для них это важная дата для улучшения их моделей
>>1172335 Чел... на арене всё это время был отдельный чатик со свободным выбором любой топовой модели, без батла с другими моделями. В этом плане арена была уникальна. Функция всё ещё доступна
Судя по документам, которые OpenAI представила инвесторам, к 2029 году выручка компании достигнет $125 млрд, а к 2030 — $174 млрд. Это выведет стартап на уровень таких гигантов, как Nvidia или Meta.
ChatGPT, бывший основным источником дохода последние два года, продолжит играть важную роль — выручка от подписок вырастет с $8 млрд в этом году до $50 млрд в 2029. Однако компания делает большую ставку на новые направления: AI-агенты (виртуальные помощники, способные выполнять действия от имени пользователей) должны принести $29 млрд к 2029 году, а монетизация бесплатных пользователей и другие новые продукты — еще $25 млрд.
При этом OpenAI ожидает значительного роста аудитории — до 3 млрд ежемесячных пользователей к 2030 году. Сейчас компания обслуживает более 500 млн активных пользователей в неделю, что уже на 200 млн больше, чем в декабре.
Самое важное — несмотря на расходы (только на работу моделей компания потратит $6 млрд в этом году и $47 млрд к 2030-му), OpenAI рассчитывает выйти на положительный денежный поток к 2029 году. Валовая прибыль должна вырасти с 40% до почти 70% выручки.
FramePack: генерация видео без цензуры, без ограничений по времени, и на слабом железе, от крутейшего lllyasviel - автора ControlNet, IC-Light, Forge, Fooocus, Omost, и других ништяков.
Метод предназначен для эффективного создания видео с использованием моделей диффузии. Он позволяет генерить видео с разрешением 480p при 30 FPS на ноутбуке с GPU объёмом памяти 6 ГБ, используя модель размером 13B параметров. При этом заявляется, что длительность видео может достигать 1000+ кадров, а потом можете просто продлить последний кадр.
FramePack упрощает тренировку видеомоделей, позволяя обучать их батчами по 64 на одном сервере с 8 видеокартами A100 или H100. Кроме того, он решает проблему «дрейфа» (drifting) в видео, обеспечивая стабильность качества на протяжении всего видео. Сообщество в восторге.
В проекте используется технология «предсказания следующего кадра» (next-frame prediction), где каждый кадр видео кодируется с разной степенью детализации в зависимости от его важности для предсказания следующего кадра. Это позволяет эффективно использовать GPU-память. Кроме того, FramePack применяет «двустороннюю» выборку (anti-drifting sampling), что предотвращает накопление ошибок и сохраняет качество видео на протяжении всей генерации. Метод также поддерживает различные схемы сжатия, что делает его гибким инструментом для создания видео из изображений.
Качество генерации высокое, хорошо сохраняется детализация и дорисовывание новых видов. На динамичных сценах могут съедаться детали или виден гостинг, но зависит от сцены.
В UI видео генерится кусками, которые потом сшиваются в общие кадры. На одной 4090 скорость генерации 2,5 сек/кадр (неоптимизированная) или 1,5 сек/кадр (teacache). На дефолтных настройках у меня нагрузило все 24 гига. На ноутах с 3070ti или 3060 (как у lllyasviel), скорость примерно в 4-8 раза медленнее.
Поддерживаются аттеншены всех мастей (PyTorch, xformers, flash-attn, sage-attention) для доп ускорения.
>>1170044 Хз как у них, но в целом био более энергоэффективно, чем кремний - условная 40х0 или 50х0 GPU жрет ~полкиловатта, и ей надо работать несколько минут или часов чтобы выдать ответ на промпт, человеческий мозг же целиком потребляет 10-20 ватт (как одна лампочка), и ответики выдает побыстрее. Ну или по другому можно пересчитать для проверки - человек в день жрет на 2,2 ккал ~= 2.5 квт-ч и это скажем на 12 часов активности включая физическую, а не только мозг.
>>1172414 >Судя по документам, которые OpenAI представила инвесторам, к 2029 году выручка компании достигнет $125 млрд, а к 2030 — $174 млрд. Это выведет стартап на уровень таких гигантов, как Nvidia или Meta. Судя по тому, как им конкуренты хуи на губу кидают - не достигнет.
>>1172537 Ты нездоров? Я привел вполне конкретные цифры. Ну делай не-трансформер на видяхе, тебе надо найти архитектуру которая раз в 10 быстрее будет, удачи.
>>1172335 >Схуяли? По твоему пользователи будут платить за то чтобы юзать ллмки и при этом выбирать один из двух вариантов? Платить будут компании производители ллм, для них это важная дата для улучшения их моделей Нет, просто выставят жесткие ограничения, как на хагге сейчас, и хуй ты там что поюзаешь. Арена и так последний месяц ошибками срёт и сбрасывает. На хагге перебанили не только все общественные прокси теневым баном, но и даже с рф хуй чё там сгенеришь, почти все гда пишет что лимит выжран. Конечно, есть еще прокси на свете, до которых ебаны не дотянулись, но просто как факт. Халявы там всё меньше.
>>1171124 >Ты не можешь сравнивать эффективность Энергоэффективность могу. Человек тратит время на какую-то задачу, задействуя мозг. Машина тратит время на ту же задачу, задействуя видеокарту. В чем для тебя проблема сравнить две цифры и понять, что мозг в задаче энергоэффективней?
>мозг потребляет 20 ватт!! >будущее за биологией!!! >нужны чипы из мяса и нервов!!! биобляди спокнитесь уже, лучше бы квантовые/оптические компы приплетали
>>1172642 >Человек тратит время на какую-то задачу, задействуя мозг. >Машина тратит время на ту же задачу, задействуя видеокарту. Еще раз, долбоеб: человек работа5ет на трансформерах? Ты тупой дегенерат просто, в принципе можешь сравнивать говно с хлебом, для тебя это одно и то же.
>>1172664 Выполнил работу - потратил энергию. Компьютер или человек вообще не важно. Если потребление на порядок выше, это энергетически, а значит экономически, не целесообразно.
>>1172673 > Если потребление на порядок выше, это энергетически, а значит экономически, не целесообразно. Вот только мясной мешок мало масштабируется и много просит, тут-то экономическая целесообразность и ломается.
>>1172709 >Хз можно ли компьютерные нейроны так организовать Нейроны состоят из материи, которая подчиняется законам физики/химии, поэтому если что-то можно организовать на био уровне, тогда и на полупроводнииковом можно организовать
>>1172744 >тогда и на полупроводниковом можно организовать Ну тогда никому не составит труда быстренько на полупроводниковом уровне организовать 100 миллиардов нейронов у каждого из которых до 20 000 связей с другими нейронами. Ждем результатов завтра, а лучше вчера.
>>1172821 >Ждем результатов завтра, а лучше вчера. Я не утверждал, что это в этом году сделают. Но очевидно полупроводники в перспективе легче масштабируются, чем какие-то био процессоры. Представь если эти твой процессоры менингитом заразятся? Это же био организм со всеми вытекающими, такую хуйню только фарм компании продвигать могут, они же срубят бабла чтобы чипировать процессоры от ковида. А если грибком зарастут?
>>1172708 Если ЭТО вставят в робота, то как раз угрожает. Все тупые ЛЛМ очень сильно угрожают в физической форме. Ты ещё тупей и не понимаешь почему-то этого.
>>1173256 То что у нее доступа в интернет - это я и так знал. Гемини мне тупо вредные советы давала, я ей в ответ написал сейчас 2025 год, она не поверила и дальше начала гнуть свою линию, мол это ты ошибаешься.
>>1173056 >А видеокарты то не перегреваются и не сгорают. И транзисторы не деградируют из за электромиграции.
Может и сгорают, но на 2025 нет ни одного приемлемого биотранзистора, очевидно лучше деньги в квант лить. Тут хоть какие-то перспективные прототипы есть